导语
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gpt-oss-120b-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gpt-oss-120b-unsloth-bnb-4bit OpenAI开源的GPT-OSS-120B大语言模型以1170亿参数规模实现单H100 GPU部署,推理成本仅为GPT-4的1/30,标志着企业级AI应用进入"普惠化"新阶段。
行业现状:应对AI落地三重挑战
2025年企业AI部署正面临"性能-成本-隐私"的三角挑战。根据《2024年企业AI大模型应用落地白皮书》显示,商业API服务如GPT-4单次推理成本约$0.06,年调用量1000万次的企业需承担60万美元支出;同时38%的企业因数据隐私合规风险对云端API持谨慎态度。开源模型市场份额已从2023年的18%飙升至2025年Q1的47%,企业级用户更倾向选择可自主掌控的开放权重方案。

如上图所示,该抽象示意图展示了大模型的计算架构与部署概念,以蓝紫色渐变线条构成的人物轮廓象征AI模型的智能形态,背景网格结构代表分布式计算资源。这一可视化形象地体现了GPT-OSS-120B在保持智能能力的同时,实现了计算资源的高效利用,为企业提供了灵活部署的技术基础。
核心亮点:重新定义开源模型能力边界
突破性部署效率与成本优势
GPT-OSS-120B采用创新的MXFP4量化技术,将原本需要多卡支持的1170亿参数模型压缩至48GB显存,实现三大突破:
- 单卡运行:H100 GPU即可部署,无需多卡集群
- 消费级适配:通过Ollama支持高端笔记本运行
- 成本锐减:单次推理成本降至$0.002,仅为GPT-4的1/30
某金融科技公司采用该模型构建智能客服系统后,月均节省API调用成本达$120,000,平均响应时间从2.3秒降至0.8秒,95%常见问题实现自动解决。
可调节推理强度与完整思维链
模型创新提供三级推理强度调节,满足不同场景需求:
| 推理强度 | 适用场景 | 响应速度 | 典型应用 |
|---|---|---|---|
| 低强度 | 日常对话 | 50ms/Token | 智能客服、闲聊机器人 |
| 中强度 | 通用任务 | 150ms/Token | 邮件撰写、文档摘要 |
| 高强度 | 复杂分析 | 450ms/Token | 金融风控、医疗诊断 |
配合完整思维链(Chain-of-Thought)输出,企业可直观追溯模型决策过程。在某银行智能风控系统中,通过分析企业年报、新闻舆情和交易数据,将不良业务预警周期从14天延长至45天,同时将人工审核工作量减少65%。
商业友好的开源许可与多框架支持
采用Apache 2.0许可协议是GPT-OSS的关键战略决策,企业可:
- 无需支付授权费用进行商业应用
- 修改模型代码以适应特定业务需求
- 集成自有数据进行微调优化
- 二次开发后无需开源衍生作品
模型提供完整的部署方案矩阵:
- 云端部署:支持AWS、Azure等平台的多卡分布式推理
- 本地服务器:120B版本需80GB GPU显存(如H100单卡),20B版本仅需16GB显存
- 边缘设备:通过INT4量化技术,20B版本可在骁龙8 Gen3芯片上运行,延迟控制在800ms内
行业影响:重构企业AI应用格局
开发范式转变
GPT-OSS-120B正在重塑大模型应用开发流程:
- 原型验证:个人开发者通过Ollama在本地完成概念验证
- 企业部署:IT团队使用vLLM部署高性能API服务
- 垂直优化:数据科学家基于PEFT技术进行领域微调
- 智能体构建:工程师利用工具调用能力开发自动化工作流
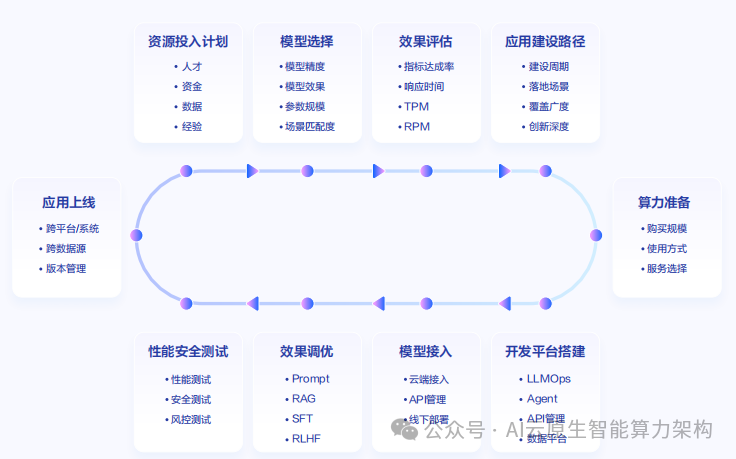
如上图所示,该架构图展示了从资源投入计划、模型选择、效果评估到应用上线的完整路径。这一流程设计反映了企业部署大模型的实际需求,而GPT-OSS-120B通过优化的参数设计,显著简化了这一流程中的硬件需求环节,使中小企业也能负担企业级大模型应用,无需依赖昂贵的云服务API调用。
典型行业应用案例
金融领域:智能风控系统
某银行基于GPT-OSS构建的智能风控系统实现:
- 贷前风险评估准确率提升42%
- 不良业务预警周期从14天延长至45天
- 人工审核工作量减少65%
- 全程数据本地化处理满足金融合规要求
教育场景:个性化学习助手
通过调节推理强度和思维链追溯,教育机构构建的学习助手可:
- 分析学生学习风格(视觉型、听觉型、动觉型)
- 动态生成适合的学习材料和练习题
- 提供完整解题步骤,帮助学生理解知识点
- 教师可通过思维链分析学生思考方式,针对性指导
企业服务:智能客服解决方案
金融科技公司采用该模型后实现:
- 95%常见问题自动解决
- 平均响应时间从2.3秒降至0.8秒
- 月均节省API调用成本$120,000
- 支持多轮对话和复杂业务查询
快速上手指南:多框架部署选择
生产环境推荐:vLLM
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve https://gitcode.com/hf_mirrors/unsloth/gpt-oss-120b-unsloth-bnb-4bit
开发测试:Transformers
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="https://gitcode.com/hf_mirrors/unsloth/gpt-oss-120b-unsloth-bnb-4bit",
torch_dtype="auto",
device_map="auto",
)
messages = [{"role": "user", "content": "解释量子力学的基本原理"}]
outputs = pipe(messages, max_new_tokens=256)
print(outputs[0]["generated_text"][-1])
本地体验:Ollama
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/unsloth/gpt-oss-120b-unsloth-bnb-4bit
# 安装依赖
pip install -U transformers kernels torch
# 基础推理示例
python -m gpt_oss.chat model/

图片展示了AWS Bedrock控制台的"模型访问权限"页面,包含权限说明、模型列表及访问状态配置选项。这一界面设计反映了企业用户对模型权限精细化控制的需求,同时也体现了GPT-OSS在商业云平台的快速集成能力,进一步验证了其企业级应用的可行性。
企业落地建议
硬件配置策略
- 大型企业:优先选择H100/A100方案部署120B版本,满足复杂推理需求
- 中小企业:推荐RTX 4090(24GB)部署20B版本,平衡性能与成本(约5000美元)
- 边缘场景:通过Ollama工具链实现INT4量化,在消费级硬件运行轻量版本
实施路径规划
建议企业分三阶段落地:
- 验证阶段(1-2周):使用20B模型跑通核心业务流程,评估ROI
- 定制阶段(4-6周):基于行业数据微调模型,开发工具调用接口
- 生产阶段:部署监控系统,优化推理性能与安全策略
结论与前瞻
GPT-OSS-120B的开源标志着大语言模型产业进入"普惠化"发展新阶段。通过Apache 2.0许可、MoE架构优化和AI Agent原生设计,OpenAI为企业提供了兼具性能、安全性和部署灵活性的AI基础设施。
未来12个月,随着多模态能力集成和垂直领域优化版本的推出,GPT-OSS系列有望在医疗诊断、金融分析、智能制造等领域催生更多创新应用。对于企业而言,现在正是评估并布局这一技术的关键窗口期——通过微调适配行业需求,将成为获取AI竞争优势的重要筹码。
如果觉得本文对您有帮助,请点赞、收藏并关注我们,获取更多AI技术前沿分析。下期我们将带来"GPT-OSS-120B微调实战:金融领域知识库构建指南",敬请期待!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







