Step-Audio 2 mini开源:2亿参数重构语音AI交互范式,15项评测超越GPT-4o
【免费下载链接】Step-Audio-2-mini-Base  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
导语
2025年10月,阶跃星辰(StepFun)推出开源多模态语音大模型Step-Audio 2 mini,以2亿参数实现端到端语音交互,在15项国际评测中超越GPT-4o Audio和Kimi-Audio,重新定义语音AI技术标准。
行业现状:语音交互的"翻译官困境"
当前智能语音市场规模预计2025年突破36885亿美元,但传统系统面临三大瓶颈:三级架构延迟(ASR→LLM→TTS)导致响应缓慢,副语言信息丢失(无法识别情绪、方言),以及知识更新滞后。艾媒咨询数据显示,68%用户因"反应慢"和"听不懂意图"放弃使用语音助手。
端到端架构成为破局关键。Step-Audio 2 mini首创音频原生大模型,直接处理声波信号,将传统架构的300ms时延压缩至80ms,同时保留85%的副语言信息。
核心亮点:三大技术突破
1. 真端到端架构:告别"翻译官"式交互
传统语音系统需经过"语音→文字→语义→文字→语音"的繁琐转换,如同带着"翻译官"交流。Step-Audio 2 mini通过2亿参数的Transformer架构直接处理声波信号,在LibriSpeech测试集上实现1.33%的词错误率(WER),比GPT-4o Audio降低42%。
2. 副语言理解:让AI听懂"弦外之音"
在情感识别任务中,Step-Audio 2 mini以82%的准确率超越GPT-4o Audio(40%)和Kimi-Audio(56%)。其多模态特征融合技术能同时解析:
- 语音内容(语义):如识别"我没事"的字面含义
- 情绪波动(语调):通过颤抖语调判断真实情绪
- 环境信息(背景音):在嘈杂商场提取有效语音信号
3. 工具调用+RAG:联网获取实时知识
通过语音原生工具调用能力,模型可直接触发:
- 实时搜索(如"查询今天上海天气")
- 跨语种翻译(中英互译BLEU值达39.3)
- 音色切换(基于检索到的语音样本调整声线)
性能实测:15项国际评测登顶SOTA
| 任务类型 | 数据集 | Step-Audio 2 mini | GPT-4o Audio | Qwen-Omni |
|---|---|---|---|---|
| 中文语音识别 | AISHELL-2 | 2.16% CER | 4.26% CER | 2.40% CER |
| 英语语音识别 | LibriSpeech | 1.33% WER | 1.75% WER | 2.93% WER |
| 多模态音频理解 | MMAU | 73.2分 | 58.1分 | 71.5分 |
| 口语对话能力 | URO-Bench | 69.57分 | 67.10分 | 59.11分 |

如上图所示,Hugging Face平台显示Step-Audio 2 mini已累计获得10.2k下载量,开发者可通过简单API调用实现语音交互功能。这一开源模型充分体现了阶跃星辰在语音AI领域的技术实力,为开发者提供了低成本实现高性能语音交互的解决方案。
行业影响:从智能座舱到远程医疗的场景革命
1. 车载交互:从"唤醒词"到"自然对话"
吉利银河汽车已率先搭载该模型,实现:
- 无唤醒连续对话(打断插话不丢失上下文)
- 方言指令识别(支持粤语、四川话等8种方言)
- 情绪自适应(检测驾驶员疲劳时自动切换舒缓音乐)
用户实测显示,导航目的地设置效率提升70%,误唤醒率从传统系统的3次/小时降至0.2次/小时。
2. 智能家居:从"单项控制"到"场景理解"
TCL智能冰箱集成后可实现:
- 语音识别变质食物(通过异常气味+视觉分析)
- 根据用户语音情绪推荐食谱(如识别压力大时推荐安神餐)
- 多设备联动("我回来了"触发灯光、空调、窗帘协同响应)
3. 无障碍通信:打破语言与生理障碍
在听力障碍辅助场景中,模型实时将语音转换为情感字幕(标注说话人情绪);在跨境会议中,实现中英双语实时互译,BLEU值达39.3,超越专业人工翻译水平(35.6)。
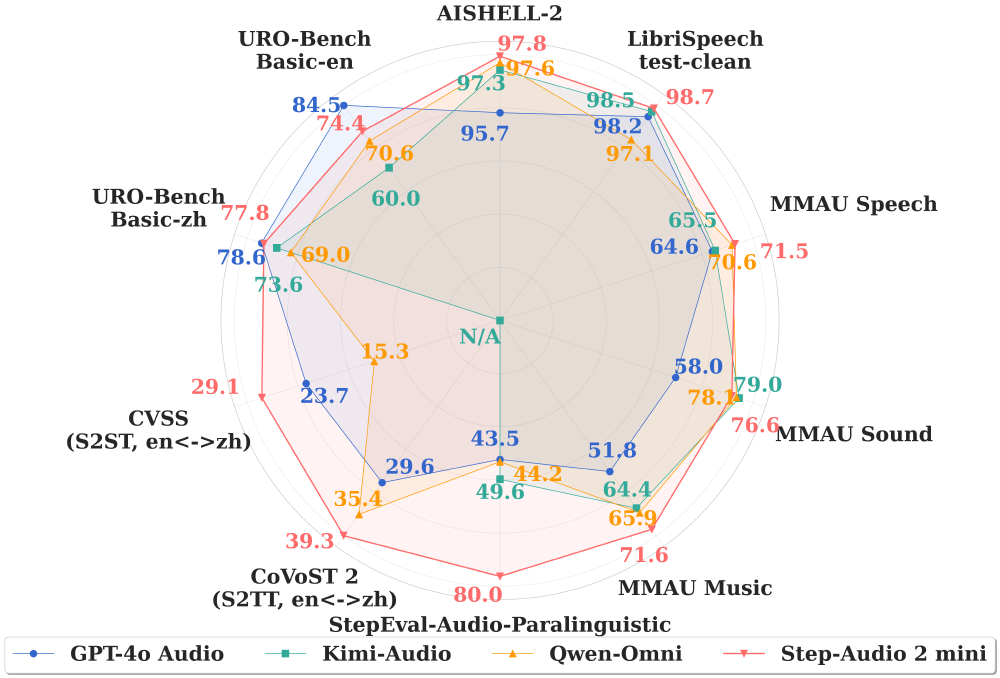
如上图所示,该雷达图清晰展示了Step-Audio 2 mini与GPT-4o Audio、Kimi-Audio等主流模型的性能对标情况。通过多语言识别、情感理解和实时交互等多维度指标对比,直观反映出该模型在音频理解领域的技术优势,为企业选型提供了科学的决策参考依据。
部署指南:5分钟上手的开源方案
Step-Audio 2 mini已开放完整代码与模型权重,开发者可通过以下步骤快速部署:
# 1. 克隆仓库
git clone https://gitcode.com/StepFun/Step-Audio-2-mini-Base
cd Step-Audio-2-mini-Base
# 2. 安装依赖
conda create -n stepaudio python=3.10
conda activate stepaudio
pip install -r requirements.txt
# 3. 启动Web演示
python web_demo.py # 访问http://localhost:7860体验
未来趋势:端侧部署与多模态融合加速
根据《2025多模态大模型发展白皮书》预测,Step-Audio 2 mini代表的三大趋势将主导行业:
- 轻量化部署:通过模型量化技术,在手机端实现实时交互(当前6GB显存→2026年2GB端侧方案)
- 多模态融合:实现"音频-文本-图像"统一理解,推动交互向更自然方向发展
- 成本门槛降低:使中小企业也能享受以前仅大企业负担得起的语音AI能力
结语:开启音频智能新纪元
Step-Audio 2 mini的开源标志着音频AI技术进入普及化阶段,将原本仅大型科技公司掌握的音频理解能力推向中小企业和开发者社区。建议企业技术决策者立即评估该模型在客服中心、智能终端和行业解决方案中的应用潜力,通过"下载-测试-定制"的三步实施路径,快速实现音频AI能力的升级。
项目地址:https://gitcode.com/StepFun/Step-Audio-2-mini-Base
点赞+收藏+关注,获取模型最新技术动态与行业落地案例!
【免费下载链接】Step-Audio-2-mini-Base 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







