6倍提速+100万上下文:Kimi Linear重构大模型效率天花板
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Linear-48B-A3B-Instruct
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-Linear-48B-A3B-Instruct 导语
2025年10月,月之暗面科技发布Kimi Linear混合线性注意力架构,首次实现线性注意力在性能、效率和普适性上对传统Transformer的全面超越,标志着大语言模型正式进入"高效长上下文"时代。
行业现状:长文本处理的"三重困境"
当前大模型在处理长文本时面临难以调和的矛盾:传统Transformer的软最大注意力虽能建模复杂依赖关系,但时间复杂度O(N²)和KV缓存线性增长的特性,使其在百万级上下文场景中陷入"慢、贵、卡显存"的三重困境。据行业分析,现有改进方案或牺牲短文本性能(如Mamba2),或难以平衡精度与效率(如混合注意力模型),始终未能实现突破性进展。
Kimi Linear的出现打破了这一僵局。通过创新的Kimi Delta Attention(KDA)机制与3:1混合架构设计,该模型在1.4T token训练规模下,同时实现了短上下文性能超越、长上下文效率跃升和硬件成本显著降低,为大模型工业化应用提供了全新技术路径。
核心亮点:KDA机制与混合架构的完美协同
1. Kimi Delta Attention:线性注意力的"精度革命"
Kimi Linear的核心突破在于Kimi Delta Attention(KDA)机制。与传统线性注意力相比,KDA通过三大创新实现精度跃升:
- 逐通道门控遗忘机制:采用Diag(α)对角矩阵替代标量遗忘因子,使模型能针对不同特征通道动态调整记忆保留策略
- Delta规则优化:改进的快权重学习机制增强了模型对长程依赖的捕获能力,同时保持线性计算复杂度
- 可学习位置嵌入:通过神经网络自动学习位置信息,避免传统位置编码在超长上下文的性能衰减
这些改进使KDA在短上下文任务上首次达到甚至超越全注意力水平,解决了线性注意力"精度妥协"的固有缺陷。
2. 3:1混合架构:效率与精度的黄金平衡点
Kimi Linear采用创新的"3层KDA+1层全局注意力"混合设计:
- 3层KDA:负责局部依赖建模和位置信息编码,占比75%的网络层大幅降低计算资源消耗
- 1层MLA:保证全局语义连贯性,避免纯线性注意力的"碎片化记忆"问题
- NoPE设计:全局注意力层去除传统RoPE,进一步优化长上下文性能稳定性
这种架构使模型在1M token上下文长度下,KV缓存需求降低75%,解码吞吐量提升最高达6倍,同时保持与全注意力相当的语义建模能力。
3. 性能实测:全场景碾压传统方案
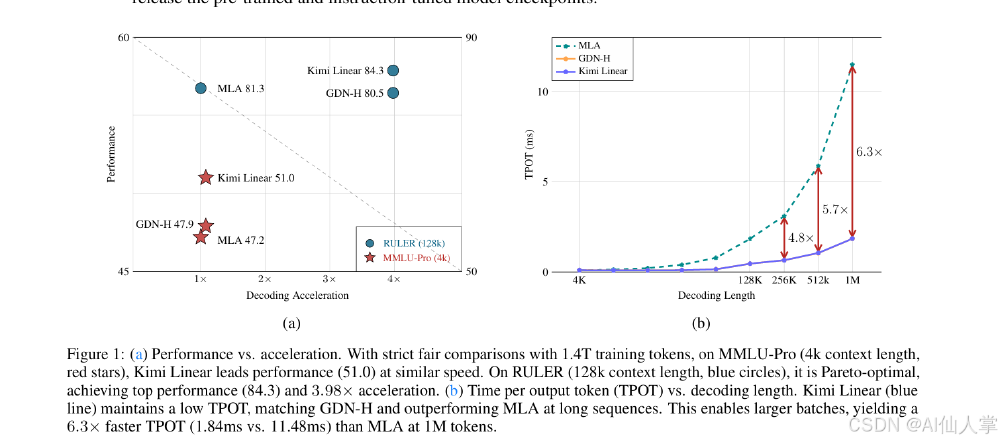
如上图所示,左侧图表对比了Kimi Linear与传统模型在不同上下文长度的性能与速度。在MMLU-Pro(4k上下文)测试中,模型达到51.0分的性能水平,同时保持与全注意力相当的速度;在RULER(128k上下文)任务上,实现84.3分的帕累托最优性能和3.98倍加速比。右侧图表则显示,在1M token超长上下文中,Kimi Linear的TPOT(Time Per Output Token)比MLA快6.3倍,充分验证了其在极端场景下的效率优势。
4. 混合架构设计:技术报告解析

如上图所示,这是Kimi Linear技术报告的标题页,清晰展示了项目名称、开发团队及开源链接。该报告详细阐述了混合线性注意力架构的设计理念,为理解大模型效率优化提供了完整的技术视角。报告中提到,Kimi Linear原本是下一代旗舰模型K3的技术验证,现在提前开源旨在推动整个社区对高效注意力机制的探索。
效率实测:长上下文场景的压倒性优势
在处理长序列时,Kimi Linear的性能优势尤为显著:
- 预填充速度:当序列长度达到100万时,Kimi Linear比全注意力模型快2.9倍
- 解码速度:对于100万的上下文长度,Kimi Linear的解码速度是全注意力的6倍
- KV缓存优化:通过3:1的混合架构,其KV缓存使用量减少了高达75%
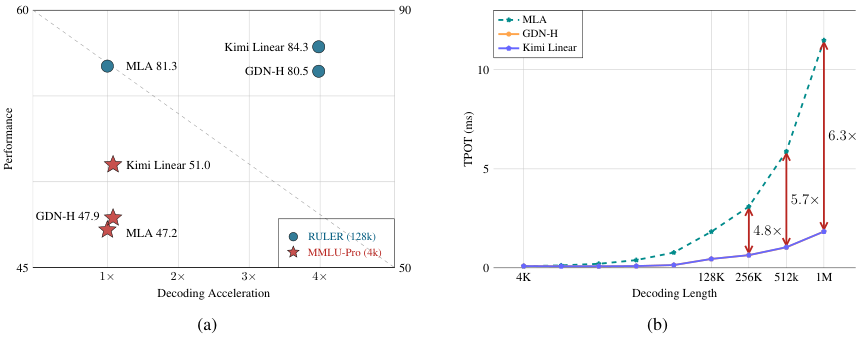
如上图所示,图(a)展示Kimi Linear在解码加速与性能上优于MLA、GDN-H等基线模型,图(b)显示Kimi Linear在不同解码长度下的解码时间(TPOT)显著低于MLA和GDN-H,尤其长序列时效率优势突出。这意味着在同样的硬件上,Kimi Linear能够处理更长的上下文,或者服务更多的用户。
部署指南:开箱即用的工业级解决方案
Kimi Linear提供完整的开源生态支持,开发者可通过以下方式快速部署:
基础环境配置
# 安装依赖
pip install -U fla-core transformers vllm
模型下载与调用
开源版本包含两个模型 checkpoint,适用于不同场景:
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| Kimi-Linear-Base | 48B | 3B | 1M |
| Kimi-Linear-Instruct | 48B | 3B | 1M |
开发者可通过Hugging Face Transformers库直接调用:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Kimi-Linear-48B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 超长文本处理示例
messages = [
{"role": "system", "content": "你是一个专业的文档分析助手,能够理解超长文本内容并提取关键信息。"},
{"role": "user", "content": "请分析附件中的技术文档,总结核心创新点和性能指标..."} # 可处理百万token级文本
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(inputs=input_ids, max_new_tokens=500)
response = tokenizer.batch_decode(generated_ids)[0]
高效部署方案
对于生产环境,推荐使用vllm部署OpenAI兼容API:
vllm serve moonshotai/Kimi-Linear-48B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 1048576 \
--trust-remote-code
行业影响:从技术突破到产业变革
Kimi Linear的开源发布将对AI行业产生深远影响,主要体现在三个维度:
1. 成本结构重构:75%显存节省的工业化价值
该模型通过线性注意力机制将KV缓存需求降低75%,配合最高6倍的解码加速,直接解决了大模型部署中的硬件瓶颈。对于需要处理超长文本的企业应用(如法律文档分析、代码库理解、医疗记录处理),硬件成本可降低60-80%,使原本难以落地的RAG和Agent应用成为经济可行的方案。
2. 应用场景拓展:从"不可能"到"轻而易易举"
Kimi Linear支持100万token上下文长度,配合高效推理能力,使以下场景成为可能:
- 全量代码库理解:一次性分析百万行级代码库的依赖关系和架构缺陷
- 超长文档处理:单轮解析整本书籍或数千页报告,无需分段处理
- 实时日志分析:高效处理系统长时间运行日志,实现异常检测和根因分析
- 复杂Agent任务:支持AI智能体进行多步骤推理和长期规划,记忆保留能力大幅提升
3. 技术路线转向:线性注意力的"回潮"与融合
正如AI研究者Raschka指出,Kimi Linear的成功标志着线性注意力方法的正式回潮。该模型证明线性注意力不仅能做到效率优势,更能通过创新设计实现精度超越,这将推动大模型架构从"纯Transformer"向"线性-全局混合"方向演进。未来,结合MoE技术的线性注意力模型可能成为超大模型的主流架构选择。
未来展望:线性注意力的"黄金时代"
Kimi Linear的发布不仅是一项技术突破,更标志着大模型发展进入"效率优先"的新阶段。随着线性注意力技术的成熟,我们有理由相信:
- 模型规模与效率的解耦:不再单纯依赖参数规模提升性能,而是通过架构创新实现"更小参数、更强能力"
- 硬件门槛持续降低:使中小企业和开发者能够负担大模型应用,推动AI应用普及
- 多模态融合加速:线性注意力在图像、视频等模态的扩展应用,将推动多模态大模型的效率革命
正如技术社区评价,Kimi Linear是"Transformer之后架构演进的一座里程碑"。它证明线性注意力不仅可以替代传统注意力,更能超越其性能极限,为大模型的可持续发展指明了方向。对于AI从业者而言,把握这一技术趋势,将在未来的模型优化和应用开发中占据先机。
想要体验Kimi Linear的强大能力?可通过官方开源仓库获取模型权重和部署工具,立即开始构建高效的超长上下文AI应用。关注我们,获取更多大模型技术解析和实战指南!
项目地址: https://gitcode.com/MoonshotAI/Kimi-Linear-48B-A3B-Instruct
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







