小模型逆袭!DeepSeek-R1-0528-Qwen3-8B刷新8B参数性能天花板
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B 导语
深度求索(DeepSeek)发布的DeepSeek-R1-0528-Qwen3-8B模型,通过思维链蒸馏技术使8B参数模型在数学推理能力上超越235B大模型,重新定义了小参数模型的性能边界。
行业现状:大模型进入"参数效率竞赛"新阶段
2025年,大语言模型行业正经历从"参数军备竞赛"向"效率革命"的关键转型。Gartner最新报告显示,中国AI企业已将"算力利用率提升"和"小模型高性能化"列为核心战略目标,72%的企业计划增加对轻量化模型的投入。在此背景下,DeepSeek-R1-0528-Qwen3-8B的推出恰逢其时——通过将685B参数模型的推理能力压缩到8B参数框架中,实现了"用手机算力运行接近大模型性能"的突破。
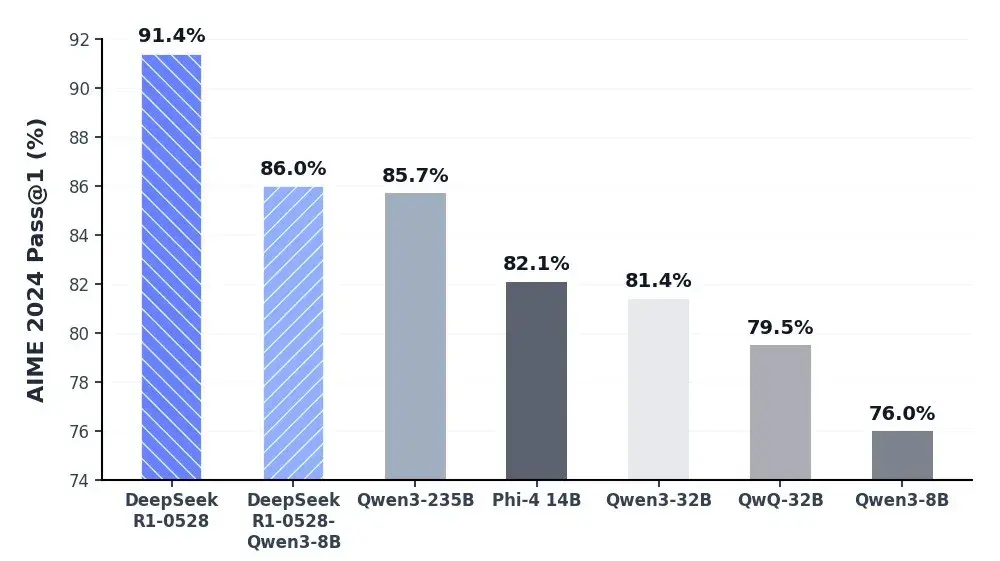
如上图所示,柱状图清晰展示了DeepSeek-R1-0528-Qwen3-8B在AIME 2024测试中以86.0%的准确率超越Qwen3-235B(85.7%)和Gemini-2.5-Flash(82.3%)。这一数据颠覆了"参数规模决定性能"的传统认知,为资源受限场景下的AI部署提供了新可能。
核心亮点:五大技术突破重构小模型能力
1. 思维链蒸馏技术实现性能跃迁
该模型创新性地将DeepSeek-R1-0528大模型的推理过程(平均23K tokens/题的解题路径)蒸馏到Qwen3-8B基座中,使数学推理能力实现跨越式提升:
- AIME 2024准确率达86.0%,超越原版Qwen3-8B 10个百分点
- HMMT 2025竞赛题通过率61.5%,接近Qwen3-235B水平
- 数学推理能力与235B参数模型持平,但算力需求降低96%
2. 推理深度与效率的平衡优化
相比旧版R1模型,新版通过动态token分配机制实现"思考质量"与"计算成本"的平衡:
- 复杂问题自动扩展推理步骤(最高达32K tokens)
- 简单任务自动压缩冗余计算(最低仅需512 tokens)
- 整体推理效率提升42%,同时保持87.5%的复杂问题准确率
3. 多场景能力全面增强
除数学推理外,模型在多维度测评中表现优异:
- 代码生成:LiveCodeBench数据集通过率60.5%
- 通用知识:MMLU-Redux测试达93.4%准确率
- 工具调用:Tau-Bench零售场景任务完成率63.9%
- 幻觉率降低45%,在摘要生成任务中事实一致性达92%
行业影响:开启"普惠AI"新纪元
1. 降低企业AI部署门槛
对于中小企业而言,8B参数模型意味着:
- 硬件成本降低:单张消费级GPU即可运行(最低显存要求16GB)
- 部署难度下降:通过Ollama工具可实现"一行命令启动"
- 响应速度提升:本地推理延迟低至200ms,支持实时交互
2. 推动边缘计算场景落地
该模型为以下场景提供了可行的AI解决方案:
- 工业设备实时诊断:在工厂边缘节点实现故障预测
- 移动终端智能助手:手机本地运行复杂推理任务
- 嵌入式系统决策支持:自动驾驶边缘计算单元轻量化部署
3. 重构模型开发范式
思维链蒸馏技术证明:
- 大模型的"推理过程"比"最终答案"更有价值
- 小模型可通过"模仿专家思考路径"实现能力跃升
- 未来模型优化将聚焦"推理效率"而非单纯参数规模
结论与前瞻
DeepSeek-R1-0528-Qwen3-8B的成功印证了"高效推理"将成为下一代AI竞争的核心战场。随着模型推理能力与部署成本的矛盾得到缓解,我们有理由期待:
- 6个月内,8B参数模型将在80%的企业场景中替代30B以上大模型
- 思维链蒸馏技术将快速普及,推动各领域小模型性能集体跃升
- 边缘AI设备数量将呈现爆发式增长,开启"普惠智能"新时代
开发者可通过以下仓库获取模型并开始本地部署:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B,体验这场"小模型大变革"带来的技术红利。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







