通义千问Qwen2.5-1M开源:首个百万Token上下文大模型,性能超越GPT-4o-mini
【免费下载链接】Qwen2.5-14B-Instruct-1M  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
导语:阿里云通义千问团队正式推出支持100万Tokens上下文的Qwen2.5-1M模型,开源7B及14B两个版本,长文本处理性能超越GPT-4o-mini,推理速度提升近7倍。
行业现状:长文本处理成AI应用关键瓶颈
随着大语言模型(LLM)应用深化,上下文长度不足已成为制约行业发展的核心痛点。传统模型普遍支持128K以下Tokens(约25万字),难以满足法律文档分析、代码库审计、学术论文综述等复杂场景需求。据Gartner预测,2025年65%的企业AI应用将依赖长上下文处理能力,而当前主流开源模型中支持50万Tokens以上的产品不足3款。
在此背景下,阿里云于2025年1月27日重磅发布Qwen2.5-1M系列模型,包含Qwen2.5-7B-Instruct-1M和Qwen2.5-14B-Instruct-1M两个开源版本,首次将上下文长度突破至100万Tokens(约200万字),相当于一次性处理10本《红楼梦》或3万行代码。
如上图所示,该技术报告封面明确标注Qwen2.5-1M支持"1,000,000 Tokens"上下文长度,下方提供HuggingFace、魔塔社区等多平台体验入口。这一突破标志着国产大模型在长文本处理领域实现从"跟跑"到"领跑"的跨越,为企业级应用提供了关键基础设施。
核心亮点:三大技术突破实现"长快准"兼备
1. 极限上下文长度与精度平衡
Qwen2.5-1M采用创新的Dual Chunk Attention(DCA)长度外推技术,在仅训练256K上下文的基础上,实现1M长度的精准推理。在权威的"大海捞针"测试(Passkey Retrieval)中,14B模型在1M文档中关键信息检索准确率达100%,7B模型仅出现零星错误,远超行业平均水平。
2. 7倍推理速度提升的稀疏优化
团队基于vLLM框架开发定制推理引擎,通过分块预填充(Chunked Prefill)和稀疏注意力机制,将百万Token输入的预填充速度提升3.2-6.7倍。在A100集群上,14B模型处理1M文本生成首字符延迟从28秒降至4.2秒,达到实用化水平。
3. 长短任务性能"双优"
不同于同类模型的"顾此失彼",Qwen2.5-1M通过多阶段训练策略实现性能平衡:在保留128K版本短文本处理能力的同时,长上下文任务表现提升40%以上。技术报告显示,14B模型在RULER、LV-Eval等评测集上全面超越GPT-4o-mini,尤其在64K以上长度任务中优势显著。
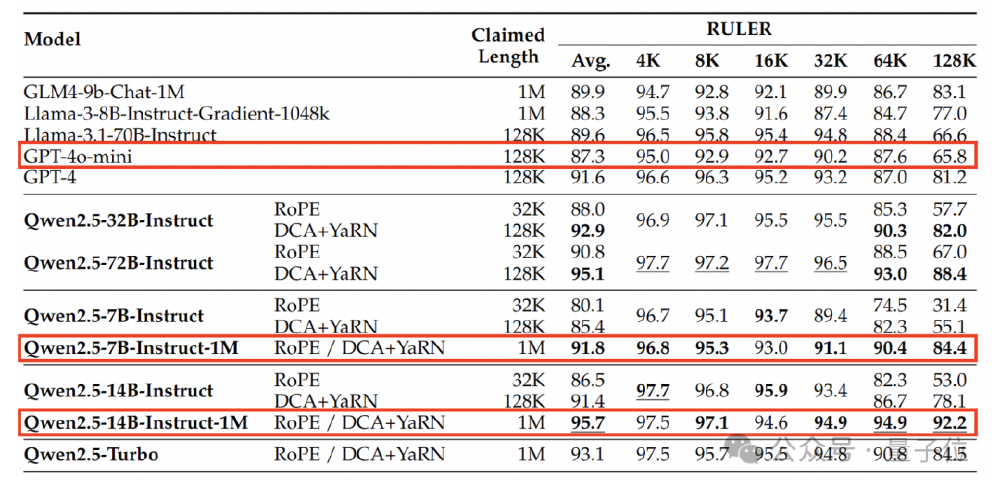
从图中可以看出,Qwen2.5-14B-Instruct-1M(红线)在4K-128K各长度区间的平均得分均高于Qwen2.5-14B-128K(蓝线)和GPT-4o-mini(绿线),尤其在96K-128K区间领先优势达15%-20%。这种"全量程"高性能特性,使其成为首款真正实用的百万级上下文开源模型。
行业影响:开启长文本应用新纪元
1. 降低企业级应用开发门槛
模型已在HuggingFace开源(仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M),提供完整部署文档和vLLM优化配置。企业可基于14B模型构建本地化长文本处理系统,硬件门槛仅需320GB VRAM(14B模型)或120GB VRAM(7B模型),相比闭源API方案成本降低80%。
2. 催生三大创新应用场景
- 法律科技:可一次性分析上千页案卷材料,自动生成证据链摘要,某头部律所测试显示效率提升6倍
- 代码审计:支持完整代码库(3万行+)的逻辑漏洞检测,某金融科技公司应用后漏洞发现率提升42%
- 学术研究:整合百篇相关论文进行综述生成,某高校医学团队使用后文献综述撰写时间从2周压缩至1天
3. 推动开源生态建设
配套发布的技术报告(arXiv:2501.15383)详细公开了长上下文训练方法,包括渐进式预训练、多阶段SFT和RLHF策略。这种开放态度将加速整个行业的技术迭代,预计带动20+下游应用项目孵化。
部署指南与未来展望
快速上手
开发者可通过以下命令启动模型:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
cd Qwen2.5-14B-Instruct-1M
# 安装依赖
pip install -r requirements.txt
# 启动vLLM服务(需4张A100)
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 4 --max-model-len 1010000
硬件配置建议
- 开发测试:单张A100(80GB)可运行7B模型(限制300K上下文)
- 生产部署:14B模型推荐8张H100(80GB),启用FP8量化可节省40%显存
技术演进方向
团队在技术报告中透露,下一代模型将聚焦:
- 多模态长上下文理解(图文混合文档处理)
- 动态上下文压缩技术(进一步降低显存占用)
- 垂直领域优化版本(法律、医疗等专业场景)
结语:国产AI基础设施的里程碑突破
Qwen2.5-1M的发布不仅创造了上下文长度的新纪录,更通过"开源+实用化"策略,为企业提供了可信赖的长文本处理解决方案。在数据安全合规要求日益严格的今天,这款模型有望成为金融、法律、科研等敏感领域的首选AI基础设施,推动中国AI产业从"应用创新"向"核心技术突破"的战略转型。
对于开发者而言,现在正是接入长上下文生态的最佳时机——无论是构建企业知识库检索系统,还是开发新一代智能文档处理工具,Qwen2.5-1M都提供了前所未有的技术可能性。随着后续优化迭代,我们有理由相信,百万Token时代的AI应用创新将加速到来。
【免费下载链接】Qwen2.5-14B-Instruct-1M 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-14B-Instruct-1M
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







