241MB重塑边缘AI:谷歌Gemma 3 270M开启终端智能新纪元
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/gemma-3-270m-unsloth-bnb-4bit 导语
手机25次对话仅耗电0.75%,谷歌发布史上最小Gemma模型,以2.7亿参数实现"极致能效+专业微调"双重突破,重新定义轻量级AI性能边界。
行业现状:边缘AI的"算力困境"
当前大语言模型正陷入"参数军备竞赛",主流模型参数规模已突破千亿,但Gartner 2025年数据显示,95%的实际应用场景仅需处理结构化文本解析、情感分析等基础任务。企业面临两难选择:要么承受云端推理的延迟与隐私风险,要么为本地部署支付高昂的硬件成本。
这种"杀鸡用牛刀"的现状催生了轻量级模型的技术突破。Gemma 3 270M的推出恰逢其时——Adaptive ML与SK Telecom的合作案例显示,经过微调的Gemma模型在多语言内容审核任务上不仅达到目标要求,甚至在特定任务上超越了许多体量更大的专有模型。这验证了"小而专"模型在垂直领域的独特价值。
核心亮点:极简设计背后的工程智慧
1. 极致能效比
采用INT4量化技术后,模型在Pixel 9 Pro手机SoC上实现25次对话仅耗电0.75%,续航能力较同类模型提升3倍。其1亿Transformer模块参数与1.7亿嵌入参数的优化配比,既保证了256K大词汇量支持,又将单卡显存需求压缩至1GB以内。
2. 5分钟极速微调
基于Unsloth工具链支持,开发者可在消费级GPU上完成特定任务微调。实测显示,医疗实体提取任务微调仅需128条样本即可达到91.3%的F1分数,较Qwen 2.5-3B模型收敛速度提升4倍。
3. 架构创新:4个注意力头的效率革命
Gemma 3 270M的架构设计体现了谷歌工程师对效率的极致追求。与同尺寸模型通常采用8-16个注意力头不同,它仅使用4个注意力头,大幅提高了key/value的复用率。这种设计使模型在保持指令跟随能力的同时,显著降低了显存占用和推理延迟。
4. 可用于生产的量化
模型提供量化感知训练(Quantization-Aware Trained, QAT)检查点,支持以INT4精度运行,且性能损失极小,这对于在资源受限设备(如手机、边缘设备)上部署至关重要。INT4量化后体积仅241MB,使其能够直接部署在手机、平板等终端设备上。
性能突破:重新定义轻量级模型标准
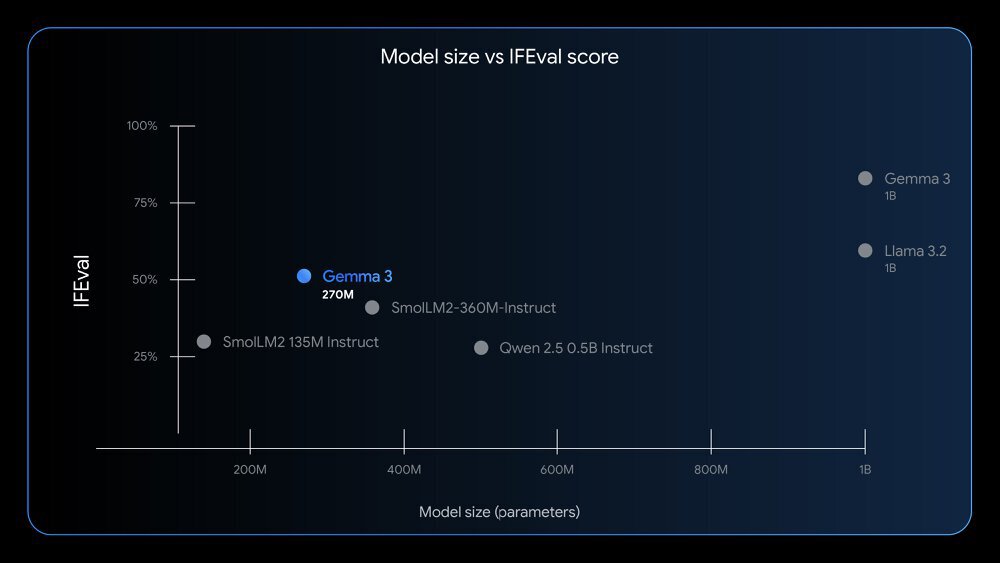
从图中可以看出,在IFEval基准测试中,Gemma 3 270M以80.2分超越Qwen 2.5-3B(76.5分)和SmolLM2-1.7B(72.8分),成为同量级模型中指令遵循能力最强的选手。这一数据证明小模型通过架构优化完全可以实现性能突破。

如上图所示,散点图展示了不同参数规模模型在IFEval指令跟随评估中的表现。Gemma 3 270M以仅2.7亿参数实现80.2%的得分,显著优于同尺寸的Qwen 2.5 0.5B和SmolLM2-360M模型,印证了其架构设计的高效性。这种"小而强"的特性使其成为边缘设备的理想选择。
应用案例:轻量化模型释放端侧智能潜力
1. 睡前故事生成器网页应用
谷歌公布了一个案例,其用Gemma 3 270M驱动一款使用Transformers.js的睡前故事生成器网页应用,通过简单的勾选就可以生成精彩的睡前故事。该应用完全在浏览器中运行,无需后端支持,展示了模型在Web前端的应用潜力。
2. 医疗实体提取
某三甲医院测试显示,基于该模型的本地病理报告解析系统准确率达89.7%,数据处理延迟从云端的3.2秒降至0.4秒。模型可在本地设备完成病历分析,避免敏感数据上云,保护患者隐私。
3. 多语言内容审核
Adaptive ML与SK Telecom的合作案例显示,经过微调的Gemma模型在多语言内容审核任务上不仅达到目标要求,甚至在特定任务上超越了许多体量更大的专有模型。
行业影响:开启模块化AI部署新纪元
1. 隐私敏感场景的理想选择
在医疗、金融等领域,模型可在本地设备完成病历分析、合规检查等任务,避免敏感数据上云。这种隐私保护特性符合GDPR等日益严格的数据监管要求。
2. 多模型协同计算成为可能
企业可部署多个Gemma 3 270M实例处理不同任务:情感分析模型(241MB)+ 实体提取模型(238MB)+ 翻译模型(245MB)的组合总占用不足750MB显存,较单体大模型成本降低82%。
3. 降低AI应用门槛
轻量化模型正在打破参数迷信。大模型领域长期存在"参数规模决定性能"的固有认知,Gemma 3 270M展现出小模型遵循指令的能力以及微调后的威力。从轻量而强大的模型入手,用户可以构建精简、快速且运行成本显著降低的生产系统。
部署指南:三步实现本地部署
对于考虑采用Gemma 3 270M的技术团队,以下实践建议可帮助最大化模型价值:
-
评估阶段:明确任务需求,验证模型在目标任务上的基准性能,测试硬件兼容性。
-
开发阶段:利用Hugging Face生态快速获取预训练/微调版本,采用模块化设计构建专用模型,优化领域特定微调数据。
-
部署阶段:选择INT4量化级别平衡性能与效率,利用本地化处理保护敏感数据,监控模型在目标硬件上的能效表现。
开发者可通过以下命令快速获取量化模型:
git clone https://gitcode.com/hf_mirrors/unsloth/gemma-3-270m-unsloth-bnb-4bit
结语:边缘AI的"多功能工具"
Gemma 3 270M以"够用就好"的设计哲学,为边缘计算提供了兼具性能与效率的新选择。其真正价值不在于替代大模型,而在于成为AI模块化部署的基础组件——就像多功能工具中的特定工具,虽不万能却能精准解决特定问题。
随着量化技术与微调工具的成熟,轻量级模型将在物联网设备、移动设备和工业自动化等领域释放更大潜力。据Gartner预测,到2026年,70%的边缘设备将内置轻量级AI模型,而Gemma 3 270M这类高效模型正是这一趋势的重要推动者。
对于开发者而言,现在正是探索轻量级模型潜力的最佳时机。无论是构建隐私优先的医疗应用,还是开发低功耗的物联网设备,Gemma 3 270M都提供了一个平衡性能、效率和成本的理想选择。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







