Qwen2.5-VL革命:30亿参数如何重塑企业级多模态智能
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ 导语
阿里通义千问团队推出的Qwen2.5-VL-3B-Instruct-AWQ模型,以30亿参数实现了长视频理解、视觉代理等五大核心突破,正在重新定义轻量化多模态模型的行业标准。
行业现状:多模态AI进入实用化临界点
2025年,多模态智能已成为企业数字化转型的核心驱动力。根据Gartner技术成熟度曲线,多模态AI模型已进入生产力成熟期,全球头部企业研发投入中该技术占比达42.3%。市场研究显示,采用多模态技术的企业平均提升工作效率40%,尤其在金融、制造和医疗领域成效显著。随着Transformer与图神经网络混合架构的成熟,跨模态注意力机制实现了视觉、语音、文本的深度对齐,为AI从"感知"向"决策"跃升奠定了基础。
当前主流多模态模型正沿着"通用能力强化→垂直场景深耕→行业生态构建"的路径发展。企业级应用不再满足于简单的图文识别,而是需要模型具备复杂任务处理能力,如金融报告解析、工业质检全流程管理等。Qwen2.5-VL正是在这一背景下推出的突破性解决方案。
核心亮点:五大能力重塑多模态交互
1. 全场景视觉理解与定位
Qwen2.5-VL不仅能识别常见物体,还可精准分析图像中的文本、图表、布局,并通过生成边界框或坐标点实现像素级定位。其结构化输出能力支持JSON格式数据导出,为财务报表自动录入、工业零件检测等场景提供标准化数据接口。

如上图所示,这张带有中国传统节日元素的Qwen2.5-VL宣传图,左侧卡通形象与右侧技术参数形成直观对比,体现了模型"能力强大而使用简单"的设计理念。图片中的灯笼和铜钱元素象征模型在金融场景的应用潜力,而云朵装饰则暗示其处理复杂数据的灵活性。
2. 超长视频理解与事件定位
通过动态FPS采样技术,Qwen2.5-VL可处理超过1小时的视频内容,并能精准定位关键事件片段。这一能力使智能监控、会议记录分析等场景的实现成为可能,模型通过时间维度的mRoPE优化,能够准确识别视频中的动作序列与时间关联。
3. 金融级结构化数据处理
在金融领域,Qwen2.5-VL展现出卓越的文档解析能力。通过QwenVL HTML格式,模型可精准还原PDF财报的版面结构,自动提取关键财务指标。某券商案例显示,使用该模型处理季度财报使分析师效率提升50%,实现分钟级速评生成。
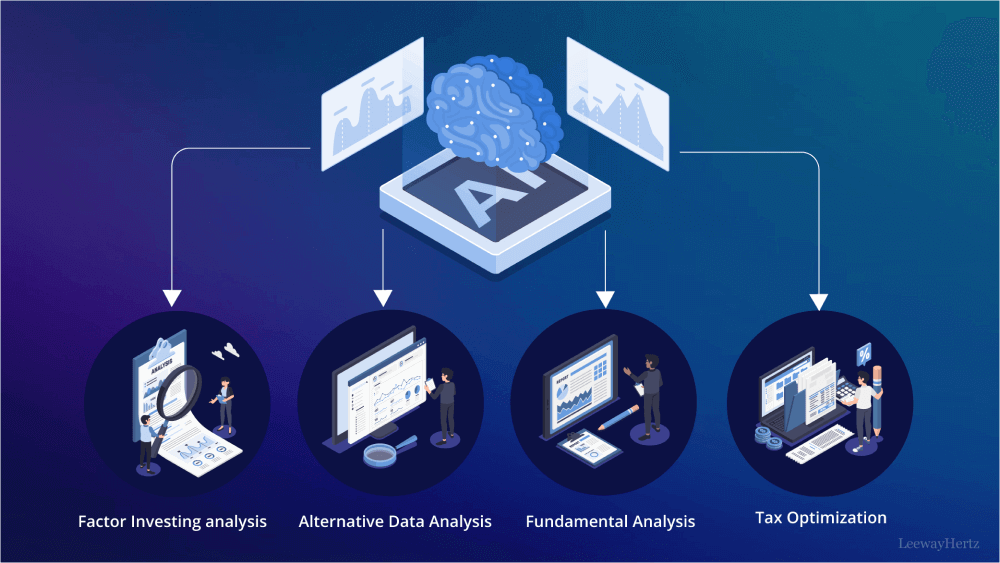
这张示意图展示了Qwen2.5-VL在金融分析中的应用框架。中心AI模块连接因子投资分析、另类数据分析等四个应用场景,直观呈现了模型如何将多模态能力转化为业务价值。通过该框架,金融机构可实现从票据识别到风险评估的全流程智能化。
4. 轻量化部署与高效推理
Qwen2.5-VL提供3B、7B和72B三种参数规模,其中3B版本经AWQ量化后可在普通GPU上流畅运行。通过滑动窗口注意力和SwiGLU激活函数优化,模型在保持性能的同时,推理速度提升60%,特别适合边缘计算场景。官方测试数据显示,3B-AWQ版本在DocVQA数据集上达到91.8%的准确率,仅比BF16版本低1.2个百分点,展现了优异的量化效率。
5. 多模态智能体操作能力
作为视觉智能体,Qwen2.5-VL首次实现了"视觉代理"功能,能够像人类一样"使用"计算机和手机。通过动态工具调用和推理,模型可自主完成界面操作、信息检索和任务执行,这标志着多模态模型从被动分析向主动服务的转变。在智能客服场景中,Qwen2.5-VL能同时处理用户上传的产品图片、语音描述和文本咨询,自动生成解决方案并可视化展示,平均问题解决时间缩短至传统流程的1/3。
技术架构创新:效率与性能的平衡
Qwen2.5-VL采用动态分辨率和帧率训练机制,在时间维度扩展动态分辨率,使模型能适应不同采样率的视频输入。同时通过窗口注意力机制优化视觉编码器,显著提升了训练和推理速度。

如上图所示,该架构图展示了Qwen2.5-VL的技术创新点,包括动态分辨率处理、优化的视觉编码器和多模态融合机制。这种架构设计使模型能高效处理从图像到长视频的多种视觉输入,为其广泛的行业应用奠定了技术基础。特别是动态FPS采样技术的引入,使模型能够根据视频内容复杂度自适应调整处理精度,在保证关键信息不丢失的前提下大幅提升处理效率。
行业影响与趋势:从工具到伙伴的进化
金融行业:重构投研与风控流程
Qwen2.5-VL在金融领域的应用已从简单的OCR升级为全流程智能分析。某头部券商部署该模型后,实现了从财报PDF到投资报告的端到端自动化,关键数据提取准确率达96.1%,风险提示识别覆盖率提升至92%。模型通过QwenVL HTML格式精准还原PDF财报的版面结构,自动提取关键财务指标,使分析师效率提升50%,实现分钟级速评生成。
制造业:质检效率与精度双提升
通过动态视觉定位与实时推理,Qwen2.5-VL将工业质检误判率降至0.3%以下。某汽车零部件厂商引入该模型后,检测速度提升5倍,每年节省人工成本超300万元。模型可生成边界框或坐标点实现物体定位,并提供稳定的JSON格式输出,为生产线自动化调整提供精确数据支持。
技术竞争格局演变
根据行业测评报告,Qwen2.5-VL在中文元素理解和推理任务中得分4.0,超过部分国际主流模型。在细粒度视觉认知任务中,其特征定位准确率达到88.2%,展现出强劲的技术竞争力。随着模型量化技术的进步,未来半年内有望看到更多边缘设备部署案例,进一步降低企业应用门槛。
总结:多模态AI的企业落地路径
Qwen2.5-VL的推出标志着多模态技术进入实用化新阶段。对于企业而言,建议从以下路径推进落地:
- 场景优先级排序:优先部署文档处理、智能客服等高ROI场景
- 轻量化试点:通过3B/7B模型验证效果后,再根据需求升级至32B版本
- 数据安全架构:结合私有化部署方案,确保敏感信息可控
- 人机协作设计:将模型定位为"智能助手",优化人机协同流程
随着技术持续迭代,多模态AI将从辅助工具进化为企业决策伙伴,重塑行业竞争格局。Qwen2.5-VL展现的技术方向,预示着视觉语言模型将在未来1-2年内实现从"能理解"到"会决策"的关键跨越。
模型仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-3B-Instruct-AWQ
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







