在大模型技术演进过程中,"混合专家架构(MoE)+长思维链推理(Long-CoT)+强化学习优化(RL)"的技术组合被公认为提升模型智能的关键路径,但如何在复杂训练过程中保持稳定性并实现高效推理,一直是困扰研发团队的核心挑战。9月19日,蚂蚁集团百灵大模型团队正式对外发布开源项目Ring-flash-2.0,通过创新算法与架构设计,将这一行业难题转化为可直接落地的技术方案。该模型以1000亿总参数量为基础,仅需激活61亿参数即可运行,在数学推理(AIME25测试86.98分)、代码能力(CodeForces elo评分90.23)和长文本处理(128K上下文200+token/s吞吐)等关键指标上全面突破,不仅达到400亿参数以内稠密模型的最佳性能水平,更具备与更大规模混合专家模型竞争的实力。
【免费下载链接】Ring-flash-2.0  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
项目地址:https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
创新"棒冰算法":双向动态截断攻克训练不稳定性难题
Ring-flash-2.0实现性能飞跃的核心驱动力,源于研发团队自主创新的"棒冰(icepop)"训练算法。这一机制采用"双向截断+掩码修正"的独特设计思路,通俗来讲就是"在训练过程中实时识别并冻结那些在训练与推理阶段精度差异过大的token,防止其通过反向传播干扰整体梯度更新"。正是这一关键技术创新,有效解决了传统强化学习方法(如GRPO)中普遍存在的训练过程崩溃问题,同时将训练与推理阶段的精度差异严格控制在15%以内的合理范围。
实验数据表明,在为期60天的强化学习训练周期内,采用icepop算法的模型损失函数曲线始终保持平稳下降趋势,而使用GRPO算法的对照组在第18天就出现明显震荡并最终完全发散。这种显著的稳定性提升使模型能够充分吸收长思维链训练带来的推理能力增强,为后续各项性能突破奠定了坚实基础。
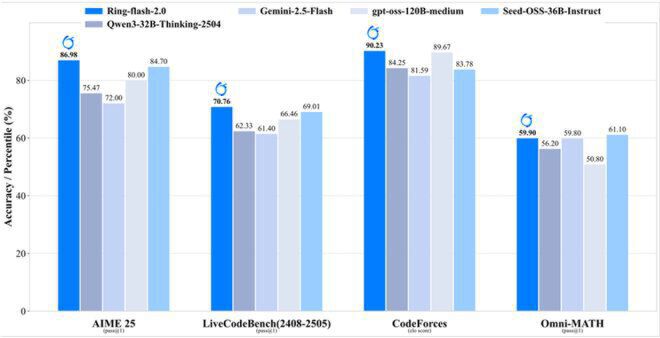
如上图所示,Ring-flash-2.0在数学推理(AIME 25)、代码生成(LiveCodeBench)、编程竞赛(CodeForces)和综合数学(Omni-MATH)四大权威评测榜单上的准确率均处于领先位置。这一性能表现充分验证了"棒冰算法"在平衡训练稳定性与推理精度方面的核心价值,为开发者提供了一套兼顾训练效率与模型效果的大模型开发新范式。
三阶递进训练体系:构建从"逻辑推理"到"实用表达"的能力进化路径
为确保模型既能突破推理能力边界,又能满足实际应用场景需求,百灵团队为Ring-flash-2.0精心设计了三阶递进式训练体系。第一阶段实施长思维链监督微调(Long-CoT SFT),从数学证明、代码调试、逻辑推理和科学问答四大领域精选高质量训练数据,通过多步骤推理示例帮助模型掌握"分步思考"的能力。与传统监督微调方法相比,该阶段特别强化了对中间推理过程的监督信号,使模型不仅能够输出正确答案,还能展现出可解释的完整推理路径。
第二阶段创新性引入可验证奖励强化学习(RLVR)机制,针对不同推理任务设计量化奖励系统。例如在数学问题处理中,通过符号执行器验证每一步计算的准确性;在代码生成任务中,利用单元测试判断解决方案的有效性。这种基于客观结果的奖励信号,有效避免了传统强化学习中因奖励函数设计偏差导致的模型能力退化问题。第三阶段通过人类反馈强化学习(RLHF),使用标注专家精心构建的偏好数据集,将模型输出的格式规范性、内容安全性和阅读流畅度调整至实用水平,最终形成"推理能力拔尖、实用体验友好"的均衡模型。
高效架构设计:超低专家激活比实现性能与效率双重突破
继承自Ling 2.0系列的高效混合专家架构,是Ring-flash-2.0实现"小激活大能力"的另一关键支撑。通过采用1/32的超低专家激活比例(即每层仅激活3.125%的专家网络)和多任务感知路由(MTP)层等创新设计,模型在实际推理过程中仅需激活61亿参数(扣除嵌入层后为48亿),却能实现相当于400亿参数稠密模型的推理效果。这种极致的参数效率带来了显著的部署优势——在由4张H20显卡组成的基础算力平台上,Ring-flash-2.0即可实现每秒200个token以上的生成速度,将高并发场景下推理型大模型的算力成本降低60%以上。
在长文本处理能力方面,模型通过YaRN上下文外推技术原生支持128K tokens的输入长度,实测数据显示随着输出文本长度的增加,其相对加速比最高可达7倍。这意味着在处理万字文档摘要任务时,Ring-flash-2.0的速度是普通模型的7倍,这种"越长越快"的独特特性使其特别适用于法律文书分析、学术论文解读等长文本应用场景。
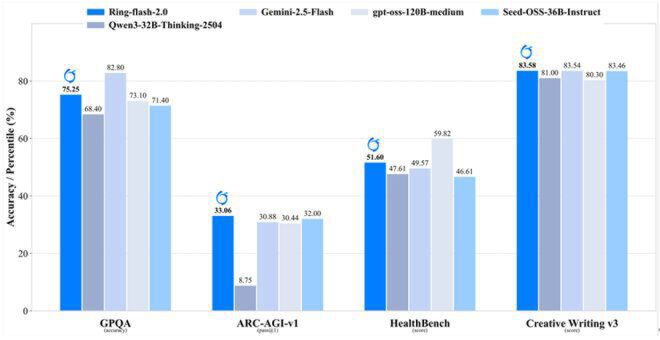
如上图所示,Ring-flash-2.0在通用推理(GPOA)、科学问答(ARC-AGI-v1)、医疗知识(HealthBench)和创意写作(Creative Writing v3)等跨领域任务上的准确率均处于领先位置。这一对比结果充分验证了高效混合专家架构在保持模型通用性方面的显著优势,为开发者提供了一个"小而全"的优质大模型选择。
开源生态价值:降低推理大模型开发门槛,推动技术普惠
Ring-flash-2.0的开源发布不仅提供了预训练模型权重,更完整开放了"棒冰算法"实现代码、三阶训练流水线和高效推理引擎。这种全链路开源策略,使中小企业和研究机构能够以极低的成本复现400亿级模型的推理能力,有望加速大模型技术在金融、医疗、教育等垂直领域的应用落地。
项目地址:https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
从技术发展角度看,Ring-flash-2.0通过"算法创新+架构优化"的双轮驱动,成功突破了传统大模型"参数量决定性能"的固有认知,证明了通过精细化设计同样可以实现高效能推理。这种技术路径为行业提供了重要启示:未来大模型的竞争焦点将逐渐从单纯的参数量比拼,转向算法创新与架构优化相结合的综合能力竞争。随着Ring-flash-2.0的开源,预计将有更多开发者基于这一平台进行二次创新,推动大模型技术向更高效、更稳定、更易用的方向发展。
【免费下载链接】Ring-flash-2.0 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







