导语
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3-0324
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3-0324 DeepSeek正式发布参数量达6850亿的DeepSeek-V3-0324大模型,在数学推理、代码生成等核心能力上实现显著跃升,部分中文场景性能已超越GPT-4.5。
行业现状:大模型进入“效率竞争”新阶段
2025年,大语言模型发展已从参数规模竞赛转向实际应用效能的比拼。据相关研究数据显示,中国AI代码生成市场规模在2024年已达90亿元,预计2028年将飙升至330亿元,年复合增长率高达38%。在此背景下,模型性能的每一点提升都直接关系到企业的降本增效能力。
与此同时,企业对大模型的需求也日益精细化。相关研究《2024年中国大模型行业应用优秀案例白皮书》指出,“电力营销客服”等场景通过大语言模型+知识库+智能体技术,一次解决用户问题比例可从30%提升至70%。这要求模型在专业领域知识、工具调用准确性和长上下文理解等方面实现综合提升。
模型亮点:五大核心能力全面进化
1. 数学推理能力跨越式提升
DeepSeek-V3-0324在多项权威评测中表现抢眼,MMLU-Pro得分从75.9提升至81.2(+5.3),GPQA从59.1提升至68.4(+9.3),尤其在AIME竞赛题上实现了19.8分的提升,从39.6跃升至59.4。这些数据表明模型在复杂逻辑推理和数学问题解决方面有了质的飞跃。
2. 代码生成质量媲美专业开发者
前端开发能力显著增强,生成代码的可执行率大幅提升。实际测试显示,开发者仅需输入自然语言需求,模型即可生成800行以上具备商业级质量的前端代码。网页界面与游戏前端的视觉设计更贴合现代美学标准,完全符合行业主流开发规范。
3. 中文写作能力对标专业水准
模型严格遵循R1写作范式,中长篇文本的结构完整性与思想深度显著增强。多轮对话场景下的上下文连贯性问题得到有效解决,支持精准的交互式内容改写;同时,翻译质量与正式文书撰写能力也实现了跨量级提升。
4. 工具调用精度大幅优化
针对企业级应用的核心需求,模型在工具调用(Function Calling)准确性上进行了重点优化,修复了前代版本的精度问题。这使得模型在API调用、数据分析等需要外部工具支持的场景中表现更加可靠。
5. 架构优化实现效能平衡
该模型延续了MoE(混合专家)设计理念,配备256个路由专家与1个共享专家系统,每个token处理过程动态激活8个专家协同工作。通过RoPE位置编码技术,模型上下文窗口可扩展至163840 tokens(160K),在保持6850亿参数量的同时,实现了性能与效率的平衡。
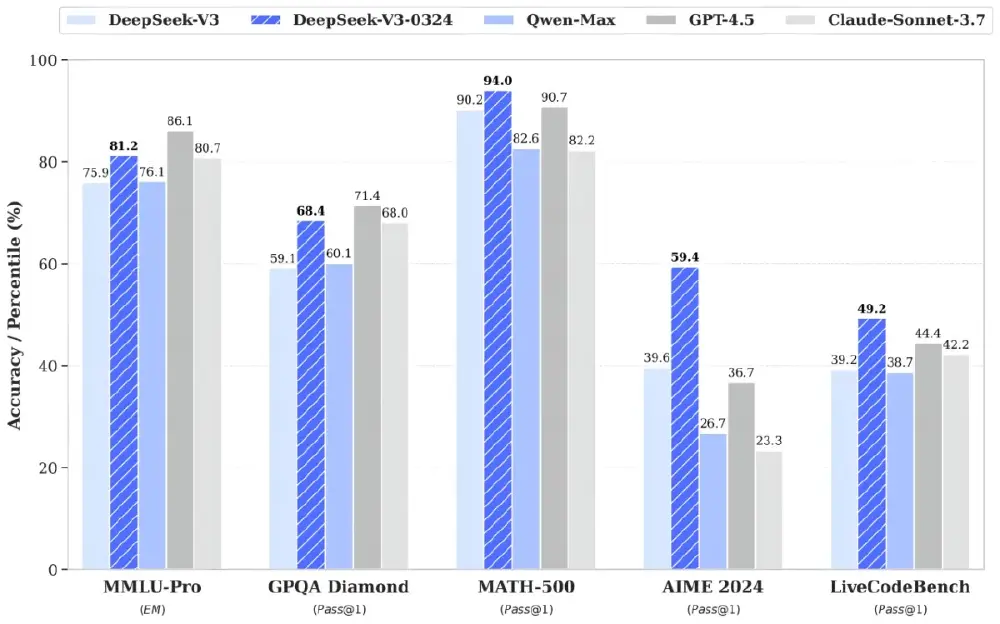
如上图所示,DeepSeek-V3-0324在MMLU-Pro、GPQA Diamond、MATH-500等多项评测中均超越了Qwen-Max等主流模型,部分指标已接近或超越GPT-4.5水平。这一性能提升充分体现了模型在推理能力上的显著进步,为企业级应用提供了更强的技术支撑。
行业影响:加速AI在企业级场景的落地
降低企业AI应用门槛
DeepSeek-V3-0324采用MIT开源协议,允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。私有化部署时只需更新checkpoint和tokenizer_config.json,大大降低了企业应用的技术门槛和迁移成本。
推动开发模式变革
模型在代码生成方面的进步将进一步改变软件开发模式。相关数据显示,AI辅助编程可提高开发者生产力高达55%,同时减少30%的bug率。随着DeepSeek-V3-0324等高性能模型的普及,“自然语言描述→自动生成代码”的开发流程将逐渐成为主流。
赋能垂直行业数字化转型
该模型在中文处理、专业领域知识和工具调用方面的优势,使其特别适合金融、医疗、公共服务等对中文理解要求高的垂直行业。通过API接口,企业可以快速构建智能客服、数据分析、报告生成等各类AI应用。
部署与使用:灵活适配多样化需求
多种部署方式可选
模型参数约660B,开源版本上下文长度为128K(网页端、App和API提供64K上下文)。用户可通过以下方式获取和部署:
- 项目地址:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3-0324
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
- Model Scope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3-0324
优化的使用配置
官方推荐温度参数设置为0.3,API调用时采用特殊的温度映射机制:
- 当API温度T_api在0-1区间时,模型实际温度T_model = T_api × 0.3
- 当T_api在1-2区间时,T_model = T_api - 0.7
这一设计有效解决了默认参数下输出质量波动的行业痛点,大幅降低了应用落地的调优成本。
结论与前瞻
DeepSeek-V3-0324的发布,标志着国产大模型在核心性能上已跻身全球第一梯队。其在数学推理、代码生成和中文处理等方面的优势,将为企业数字化转型提供强大动力。随着模型性能的不断提升和应用生态的完善,我们有理由相信,AI技术将在更多行业场景中实现真正的价值落地。
对于开发者和企业而言,现在正是评估和引入新一代大模型技术的最佳时机。通过合理利用DeepSeek-V3-0324等先进工具,企业可以显著提升运营效率,加速创新步伐,在数字化浪潮中占据有利位置。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







