82亿参数双模式革命:Qwen3-8B-Base如何重塑开源大模型格局
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B-Base
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B-Base 导语
阿里巴巴通义千问团队于2025年4月发布的Qwen3-8B-Base模型,以82亿参数实现性能与效率双重突破,首创"思考/非思考"双模式推理架构,重新定义了中小规模开源大模型的技术边界。
行业现状:大模型的"效率困境"
当前大语言模型发展面临"性能与成本"的核心矛盾。据行业分析,2025年企业级AI部署中算力成本占比已达43%,闭源模型调用成本高昂,而传统开源模型在复杂推理任务中仍存差距。Qwen3-8B-Base通过创新架构设计,在保持高性能的同时将推理成本降低50%以上,为开发者和企业提供了新的技术选择。

如上图所示,紫色背景上展示了Qwen3的品牌标识,包含白色"Qwen3"文字与穿印有Qwen字样T恤的卡通小熊形象(小熊比OK手势)。这一视觉设计不仅强化了品牌认知,也体现了Qwen3系列在保持技术领先性的同时,致力于打造友好易用的开发者体验。
核心亮点:技术创新与性能突破
1. 首创双模式推理架构
Qwen3-8B-Base支持"思考模式"与"非思考模式"动态切换,通过简单指令(如/think或/no_think)灵活控制推理深度:
- 思考模式:针对数学推理、代码生成等复杂任务,在HumanEval代码测试中达到89.7%的Pass@1率
- 非思考模式:适用于信息检索、简单对话等场景,响应速度提升50%以上
这种设计打破了传统大模型"一刀切"的算力分配模式,实现了不同场景下的最优资源配置。
2. 三阶段预训练与架构优化
采用创新的三阶段预训练流程:
- 第一阶段:30万亿token基础语言建模,构建通用知识体系
- 第二阶段:5万亿高质量数据强化STEM、编码等推理能力
- 第三阶段:专项训练长文本处理能力,上下文长度扩展至32,768 tokens
架构上采用36层Transformer结构,配备32个查询头和8个键值头(GQA注意力机制),非嵌入参数达6.95B,优化了计算效率。
3. 多语言能力与数据规模跃升
相比前代模型实现质的飞跃:
- 支持119种语言,涵盖中文(含粤语)、阿拉伯语、斯瓦希里语等低资源语言
- 预训练数据量达36万亿token,包含丰富的编码、STEM、书籍和合成数据
- 中文处理能力尤为突出,在相关中文测试中表现超越同类英文模型
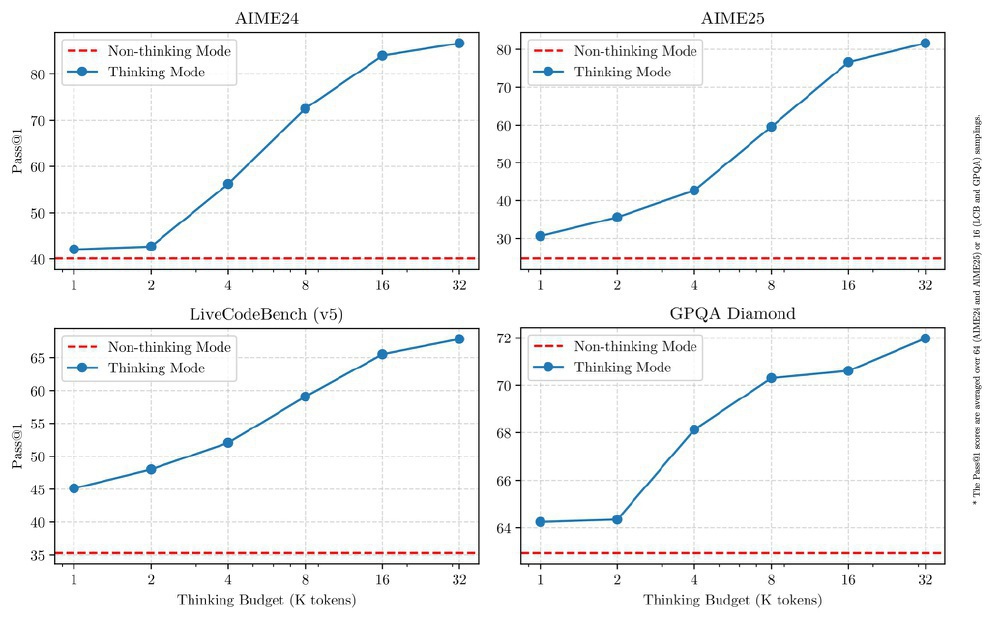
如上图所示,该图展示了Qwen3在AIME24、AIME25、LiveCodeBench (v5)、GPQA Diamond四个基准测试中,不同推理模式下随思考预算(K tokens)变化的Pass@1性能曲线。从图中可以清晰看出,思考模式在复杂任务中表现优异,而非思考模式在简单任务上效率更高,直观体现了混合推理架构的优势。
性能表现:基准测试成绩单
Qwen3-8B-Base在多项权威测试中表现优异:
- MMLU多任务测试得分78.3%,超越Llama 3 8B(76.5%)
- GSM8K数学推理准确率达95.3%,接近GPT-4o水平
- HumanEval代码生成测试Pass@1率89.7%
- 支持32,768上下文长度,可处理数百页文档
在编程能力测试中,Qwen3-8B在devopseval测试集上总通过率达0.6622,超过Qwen2.5-14B的0.6327,展现出跨量级的性能提升。
行业影响与应用前景
1. 推动开源模型性能边界
Qwen3-8B-Base的发布进一步缩小了开源模型与闭源模型的性能差距。在保持82亿参数规模的同时,部分指标接近或超越更大规模模型,证明了高效架构设计的价值。
2. 降低企业级AI部署门槛
- 支持消费级硬件部署,8GB显存即可运行量化版本
- 兼容Hugging Face Transformers、vLLM、SGLang等主流框架
- Apache-2.0开源协议,允许商业应用和二次开发
3. 应用场景与行业案例
已在多个领域展现实用价值:
- 智能编程:集成到IDE工具中,实现代码自动补全和Bug修复
- 教育辅助:作为个性化学习助手,提供数学问题分步解析
- 企业服务:用于客户支持、文档分析等任务,降低运营成本
- 工业应用:陕煤集团已部署Qwen3系列模型用于矿山风险识别系统

如上图所示,该图展示了Qwen3完整的模型家族架构,包含从0.6B到235B参数的8款开源模型,分为混合专家(MoE)和稠密模型(Dense)两大系列。Qwen3-8B-Base作为Dense系列的重要成员,平衡了性能、效率和部署门槛,为中低资源场景提供了理想选择。
部署与应用指南
快速启动代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"https://gitcode.com/hf_mirrors/Qwen/Qwen3-8B-Base",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("https://gitcode.com/hf_mirrors/Qwen/Qwen3-8B-Base")
# 思考模式示例(数学推理)
prompt = "求解方程 x² + 5x + 6 = 0 /think"
部署优化建议
- 推理框架:优先使用vLLM(≥0.8.5)或SGLang(≥0.4.6.post1),吞吐量提升3-5倍
- 硬件配置:开发测试推荐RTX 4090,生产环境建议A10 GPU(支持50-100并发用户)
- 量化策略:4-bit AWQ量化可将显存占用降至5GB以下,性能损失小于3%
结论与前瞻
Qwen3-8B-Base代表了开源大模型发展的重要方向:通过架构创新而非单纯参数扩张来提升性能。其混合推理模式、高效预训练方法和多场景适配能力,为AI技术普惠化提供了新可能。
对于开发者和企业而言,现在正是探索Qwen3-8B-Base应用价值的最佳时机:
- 个人开发者可通过Ollama(
ollama run qwen3:8b)快速体验 - 企业用户可基于模型构建垂直领域解决方案,降低AI部署成本
- 研究人员可借助开源特性,深入探索大模型推理机制
未来,随着工具调用、多模态理解等功能的完善,Qwen3系列有望从语言模型升级为通用智能体,在复杂任务规划、长周期推理等场景实现突破。开源社区可关注模型的量化优化、领域微调等方向,共同构建更高效、更易用的AI基础设施。
立即体验Qwen3-8B-Base开源模型,访问仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-8B-Base
欢迎点赞、收藏、关注,获取更多AI模型深度解析与应用指南!下期将带来Qwen3-8B的量化部署实战教程。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







