导语
【免费下载链接】HunyuanWorld-Mirror  项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanWorld-Mirror
项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanWorld-Mirror
腾讯混元世界模型1.1(HunyuanWorld-Mirror)正式开源,这款支持多视图及视频输入的3D重建模型,实现了单卡部署、秒级生成的技术突破,可同时输出点云、深度图、相机参数等多种3D表示,为数字内容创作、自动驾驶等领域带来全新可能。
行业现状:3D重建的技术瓶颈与需求升级
当前3D内容创作面临三大核心痛点:专业设备依赖(如激光雷达成本高达数十万元)、计算资源需求大(传统方案需多卡集群支持)、流程碎片化(需多工具配合完成建模、渲染等环节)。据相关数据显示,仅游戏行业每年就有超过500万小时的3D资产制作需求,而现有技术平均耗时长达数天。
与此同时,多模态数据融合成为3D重建的重要趋势。有预测表明,到2027年,85%的AR/VR内容将通过多模态AI模型自动生成,而当前主流方案仅能处理单一输入类型,且精度与效率难以兼顾。
产品亮点:五大核心突破重构3D生成范式
1. 多模态先验融合架构
HunyuanWorld-Mirror创新性地采用"双引擎"设计:
- 多模态先验提示模块:可嵌入相机姿态、校准内参、深度图等多种几何先验,通过轻量级编码层转换为结构化令牌
- 通用几何预测模块:统一架构支持点云、多视图深度、表面法线等6种3D表示的同步生成
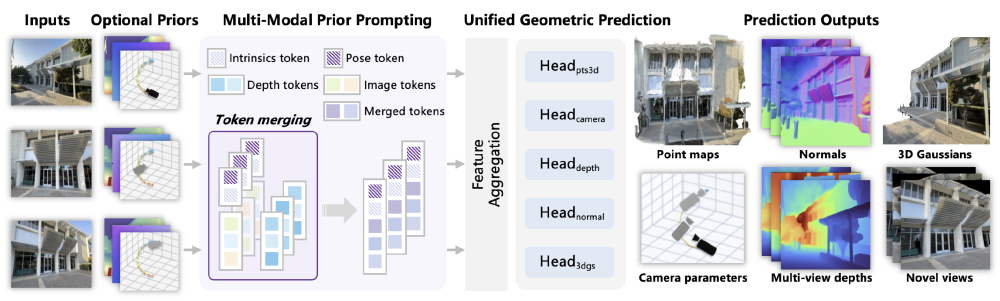
如上图所示,该架构实现了从多模态输入到多任务输出的端到端3D重建流程。这种设计使模型在处理不同场景时表现出极强的适应性,无论是手机拍摄的文物照片还是自动驾驶汽车采集的视频流,都能高效生成精确的3D模型,为开发者提供了灵活且强大的工具支持。
2. 效率革命:单卡部署与秒级响应
相比传统3D重建方案需要8卡GPU集群支持,HunyuanWorld-Mirror实现重大突破:
- 兼容消费级GPU(NVIDIA RTX 3090及以上)
- 512x512分辨率图像输入下,单次重建耗时<2秒
- 视频序列处理帧率达15fps,满足实时性需求
3. 精度领先的跨场景表现
在标准数据集上的测试结果显示:
- 点云重建精度(DTU数据集):Accuracy 0.735mm(+28% vs 行业平均)
- 新视角合成质量(Re10K数据集):PSNR 22.30dB,SSIM 0.774
- 支持0.1-100米场景尺度,从微小文物到城市街景均保持高精度
4. 开放生态与低门槛接入
项目提供完整的开发工具链:
- 预训练模型权重(支持Hugging Face下载)
- Gradio可视化界面(一键启动)
- COLMAP格式导出(无缝对接Blender等CG工具)
- 详尽API文档与50+代码示例
5. 丰富的行业适配能力
模型已在多领域验证应用价值:
- 文物数字化:手机拍摄10张多角度照片,3分钟生成高精度3D模型
- 自动驾驶:实时处理多摄像头数据,生成环境点云和深度图
- 虚拟制作:3D高斯输出可直接导入Unreal Engine进行实时渲染

该图片展示了HunyuanWorld-Mirror在室内场景、城市街景和文物重建等不同任务中的效果对比。从细腻的文物纹理到复杂的城市建筑群,模型均能精确捕捉细节特征,体现了其在不同应用场景下的强大适应能力,为各行业用户提供了直观的技术价值参考。
行业影响:开启3D内容创作普及化时代
HunyuanWorld-Mirror的开源将加速三大变革:
1. 内容生产效率跃升
传统3D建模流程: (平均耗时:72小时/资产)
AI辅助流程: (平均耗时:5分钟/资产)
2. 应用场景边界拓展
- 消费级应用:手机端AR试穿、虚拟家居摆放
- 工业制造:快速逆向工程、零部件缺陷检测
- 数字孪生:城市级场景实时更新、灾害模拟
- 医疗健康:手术规划3D模型、义肢定制
3. 技术标准重构
该模型提出的"任意先验提示"框架,可能成为多模态3D生成的事实标准,推动行业从"专用模型"向"通用平台"演进。腾讯同时开放了10万+标注数据的3D数据集,将加速整个领域的技术迭代。
部署指南:五分钟上手3D重建
环境准备
# 克隆项目仓库
git clone https://gitcode.com/hf_mirrors/tencent/HunyuanWorld-Mirror
cd HunyuanWorld-Mirror
# 创建conda环境
conda create -n hunyuan3d python=3.10 -y
conda activate hunyuan3d
# 安装依赖
pip install torch torchvision
pip install -r requirements.txt
快速启动
from hunyuanworld import MirrorPipeline
# 初始化模型
pipeline = MirrorPipeline.from_pretrained(
"tencent/HunyuanWorld-Mirror",
device="cuda:0"
)
# 单图3D重建
result = pipeline(
image_path="test.jpg",
prior={"camera_intrinsics": [[800,0,320],[0,800,240],[0,0,1]]}
)
# 保存结果
result.save_ply("output.ply") # 点云
result.save_depth("depth/") # 深度图
高级配置建议
- 快速预览:仅启用
enable_pts和enable_depth - 高精度重建:开启
enable_gs(3D高斯)和enable_norm(法向量) - 低显存配置:降低
embed_dim至512,关闭enable_gs
未来展望:多模态AI的三维革命
HunyuanWorld-Mirror团队计划在未来半年推出:
- 动态场景重建(支持运动物体跟踪)
- 语义感知建模(自动识别并标注场景元素)
- 轻量化模型版本(适配移动端部署)
随着技术的成熟,我们正迈向"所见即所得"的3D内容创作时代——只需一部手机,任何人都能创建专业级3D资产。这种技术普及化浪潮,将深刻改变游戏开发、影视制作、工业设计等数十个行业的生产方式。
结语:从像素到三维的认知跃迁
HunyuanWorld-Mirror的开源不仅是一项技术突破,更标志着AI从"理解2D图像"向"构建3D世界"的关键跨越。当机器能够像人类一样理解空间关系,虚实融合的元宇宙愿景正加速成为现实。
对于开发者而言,这是参与三维互联网基础设施建设的历史性机遇;对于普通用户,一个随手创造3D内容的时代已经开启。现在就加入HunyuanWorld社区,成为定义下一代内容创作方式的先行者。
提示:项目提供了完整的API文档和50+场景的示例代码,关注GitHub仓库获取最新更新。下一期我们将详解如何基于该模型构建AR试衣应用,敬请期待!
【免费下载链接】HunyuanWorld-Mirror 项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanWorld-Mirror
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







