DeepSeek-V3.2-Exp发布:稀疏注意力技术如何重塑大模型效率革命
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp 导语
深度求索在2025年9月29日推出的DeepSeek-V3.2-Exp实验版模型,通过创新的稀疏注意力机制将大模型推理成本降低50%,同时API价格同步下调75%,标志着中国大模型企业在效率优化领域实现技术突破。
行业现状:大模型进入"效率竞速"时代
2025年全球大语言模型市场规模预计突破1500亿美元,年复合增长率维持在45%以上。随着模型参数量级突破万亿,算力成本已成为制约行业发展的核心瓶颈。根据IIM信息咨询报告,当前推理算力需求已超过训练,占AI基础设施支出的62%,其中长文本处理场景的效率问题尤为突出。在此背景下,DeepSeek推出的稀疏注意力技术(DSA)正切中行业痛点,成为继混合专家(MoE)架构后又一重要技术方向。
核心亮点:DSA技术实现"效率飞跃"
1. 细粒度稀疏注意力机制
DeepSeek Sparse Attention(DSA)通过"闪电索引器"实现动态稀疏计算,在长文本处理中仅对关键信息进行精确计算。官方数据显示,该技术在160K上下文长度下可降低30%-50%的推理成本,而性能保持与V3.1版本基本持平。这一突破使得模型在处理法律文档分析、代码库理解等长文本场景时,硬件需求显著降低。

如上图所示,Prefilling阶段(左)和Decoding阶段(右)的双折线图显示,随着Token长度增加,V3.2-Exp的成本优势逐渐扩大,在128K位置时推理成本仅为V3.1的53%。这一效率提升直接转化为商业价值,使模型部署门槛大幅降低。
DSA的两大核心组件:
- 闪电索引器(Lightning Indexer):轻量级筛选器,使用128维小键缓存快速扫描整个上下文,找出最相关的关键信息
- 稀疏多潜在注意力(Sparse MLA):重量级计算器,仅对筛选出的关键信息进行512维完整维度计算,保证计算精确性
2. 四阶段后训练流程创新
该模型采用创新性的四阶段训练方法:密集热身训练→稀疏训练→专家蒸馏→RL强化学习,既保持了原有性能,又实现了效率突破。特别值得注意的是,团队使用TileLang高级语言进行GPU算子快速原型开发,再通过CUDA实现高效版本,相关算子已全部开源,为社区提供了可复用的效率优化工具链。
3. 商业价值双重释放
效率提升直接反映在定价策略上:API输入价格下降50%(缓存输入每百万token仅需0.2元),输出价格降低75%(每百万token仅需3元)。与此同时,华为云已完成对该模型的适配,支持160K长序列上下文,并通过MaaS平台向企业用户开放,金融、法律等对长文本处理需求强烈的行业率先受益。
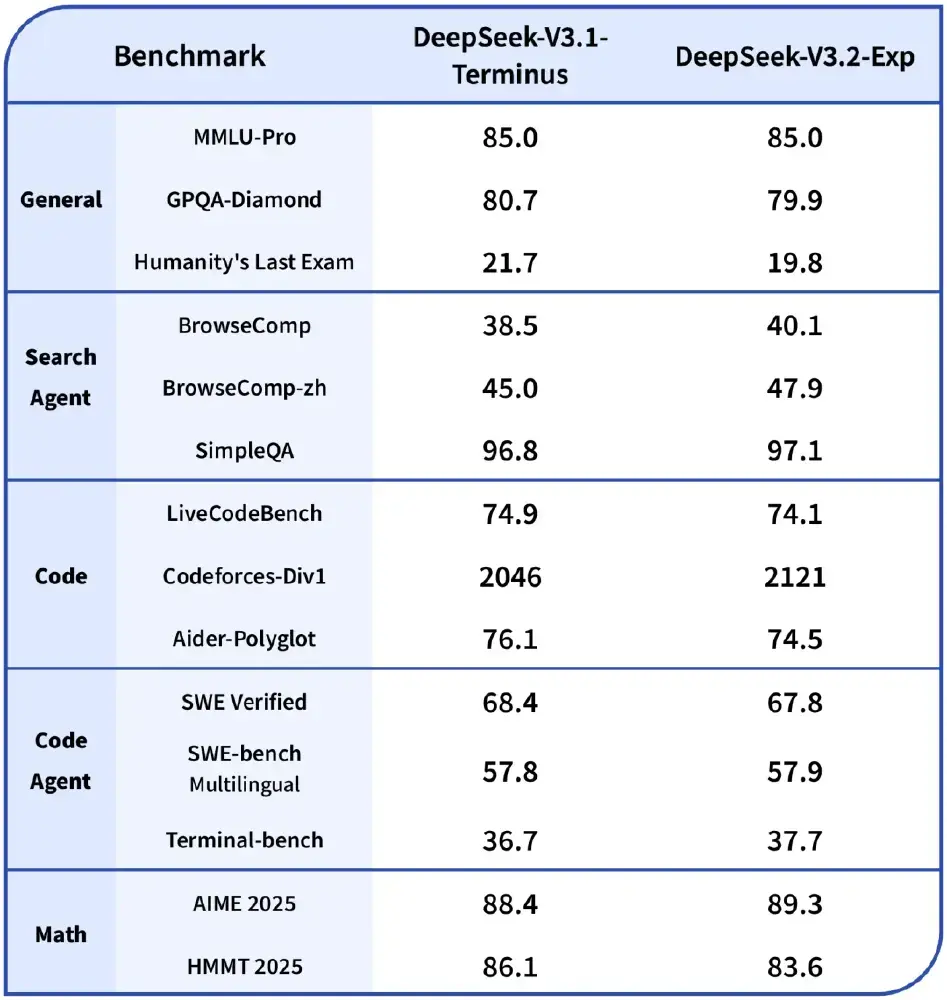
该表格展示了V3.2-Exp与V3.1在11个评测维度上的性能对比,其中9项指标差异小于2%,证明效率提升并未以牺牲质量为代价。在代码生成任务上甚至实现1.3%的小幅提升,显示出稀疏机制对特定场景的适应性优势。
行业影响:开启"普惠AI"新阶段
1. 技术格局重塑
DSA技术的出现,使"性能与效率"的二元对立得到缓解。中关村科金总裁喻友平指出:"在金融行业,通过大模型技术,我们为头部券商打造的财富助手响应速度提升40%,而服务器成本下降近三成"。这种"降本增效"的双重优势,正在改变企业选择大模型的决策权重。
2. 开源生态加速成熟
模型已在HuggingFace和ModelScope全面开源,论文同步公开。这种开放策略吸引了超过200家企业参与测试,其中不乏工商银行、华泰证券等金融机构。开源生态的繁荣,使得垂直领域微调成本降低60%以上,加速了大模型的行业渗透。

如上图所示,深蓝色背景中带有光效线条,透明蓝色鲸鱼形象上标注"DeepSeek Sparse Attention",视觉化呈现DeepSeek的稀疏注意力机制技术。这一技术创新通过"先筛选,后计算"的方式,将复杂的注意力计算分解为闪电索引器和稀疏多潜在注意力两大核心组件协同工作。
3. 竞争焦点转移
随着效率成为核心竞争力,行业正从"参数竞赛"转向"架构创新"。Menlo Ventures报告显示,2025年企业级大模型市场份额中,效率优化型产品占比已达38%,较去年提升21个百分点。DeepSeek通过此次技术突破,其API调用量在发布后两周内增长217%,市场份额提升至9%。
结论/前瞻:稀疏化将成行业标配
DeepSeek-V3.2-Exp作为实验性版本,虽在复杂场景稳定性和端侧部署方面仍有优化空间,但其验证的稀疏注意力技术路线已展现出明确前景。根据行业预测,到2026年底,80%以上的主流大模型将采用类似的稀疏化技术,推动推理成本进一步下降,为AI在中小企业的普及扫清障碍。
企业用户可通过以下方式快速体验该模型:
# 克隆项目仓库
git clone https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3.2-Exp
# 转换模型权重
cd DeepSeek-V3.2-Exp/inference
export EXPERTS=256
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} --n-experts ${EXPERTS} --model-parallel ${MP}
# 启动交互式对话
export CONFIG=config_671B_v3.2.json
torchrun --nproc-per-node ${MP} generate.py --ckpt-path ${SAVE_PATH} --config ${CONFIG} --interactive
随着稀疏注意力技术的持续迭代和硬件优化的深入,大模型行业正迈入"效率优先"的新纪元。DeepSeek-V3.2-Exp的发布不仅是一次技术更新,更标志着中国AI企业在基础架构创新领域已跻身全球第一梯队,为行业可持续发展提供了新的技术范式。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







