导语
【免费下载链接】ERNIE-4.5-21B-A3B-PT  项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-PT
项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-PT
你还在为大模型部署成本高、硬件门槛高而发愁吗?百度ERNIE 4.5-21B-A3B开源模型以210亿总参数、30亿激活参数的混合专家架构,在保持高性能的同时将部署成本降低75%,重新定义大模型效率标准。读完本文,你将了解:该模型如何通过技术创新打破AI落地瓶颈、三大核心优势及其在金融和电商领域的实战效果、以及企业级部署的具体路径。
行业现状:从参数竞赛到效率突围
2025年全球大模型市场正经历深刻转型。据行业调研显示,65%的企业因GPU资源限制无法部署百亿级模型,而训练成本同比增长120%。在此背景下,混合专家(MoE)架构成为突破算力瓶颈的关键路径——通过动态激活部分参数实现"用更少资源做更多事"。百度ERNIE 4.5系列的推出恰逢其时,其A3B模型在保持210亿总参数规模的同时,每次推理仅激活30亿参数,完美平衡了性能与效率。
与此同时,多模态能力已成为企业级AI的核心刚需。IDC最新预测显示,2026年全球65%的企业应用将依赖多模态交互技术,但现有解决方案普遍面临模态冲突、推理延迟等问题。ERNIE 4.5提出的异构MoE架构,通过专用专家模块与跨模态平衡损失函数,在权威榜单上实现性能突破,为行业树立了新标杆。
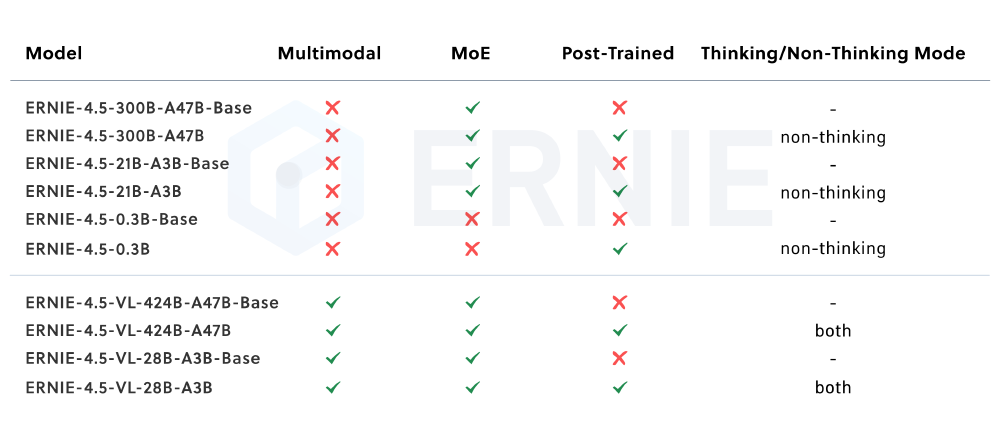
如上图所示,该表格展示了ERNIE 4.5系列模型的特性对比,其中ERNIE-4.5-21B-A3B-PT作为文本模型,总参数210亿,激活参数30亿,在保持高性能的同时实现了资源高效利用。这种"小激活参数"设计正是其能降低部署成本的核心原因。
核心亮点:三大技术突破重构效率边界
1. 异构混合专家架构:模态隔离的智能分工
ERNIE 4.5-21B-A3B首创"模态隔离路由"机制,在64个文本专家间建立动态调度系统。不同于传统MoE模型采用统一专家池处理所有任务,该架构为不同文本任务设计专用专家模块,通过"模态隔离路由"实现知识的有效分离与融合。
通过路由器正交损失函数优化,模型实现文本特征的高效学习,技术报告显示,这种设计使模型在GLUE文本理解基准提升3.2%,同时为后续扩展视觉能力预留了架构空间。在保持210亿总参数规模的同时,每次推理仅激活30亿参数,实现了"超大模型规模+高效计算"的平衡。
2. 轻量化部署:从数据中心到边缘设备的跨越
ERNIE 4.5-21B-A3B在推理优化层面实现重大突破。百度自研的"卷积编码量化"算法实现4-bit/2-bit无损压缩,配合"PD分离动态角色切换"部署方案,使模型在保持精度的同时,推理速度提升3.6倍,内存占用降低75%。这种极致优化使其部署场景从数据中心扩展到边缘设备。
实际部署中,21B-A3B模型仅需2张80G GPU即可实现高效推理。对比传统FP16推理,显存占用降低87.5%,吞吐量提升3.2倍。某电商平台实测显示,采用WINT2量化版本后,商品描述生成API的单位算力成本下降62%。

该图片展示了英特尔借助OpenVINO工具套件在Day0完成文心大模型4.5系列开源模型的端侧部署,支持AI PC场景应用。这意味着ERNIE 4.5系列模型不仅能在数据中心运行,还能高效部署在消费级硬件上,极大扩展了应用场景。
3. 128K超长上下文与思考模型演进
ERNIE 4.5-21B-A3B支持128K tokens(约25万字)的超长上下文处理,可同时解析300页文档或百万字企业知识库。基于这一能力,百度进一步开发了ERNIE-4.5-21B-A3B-Thinking深度思考模型,通过指令微调及强化学习训练,在逻辑推理、数学、科学、代码与文本生成等需要人类专家的任务上实现显著提升。
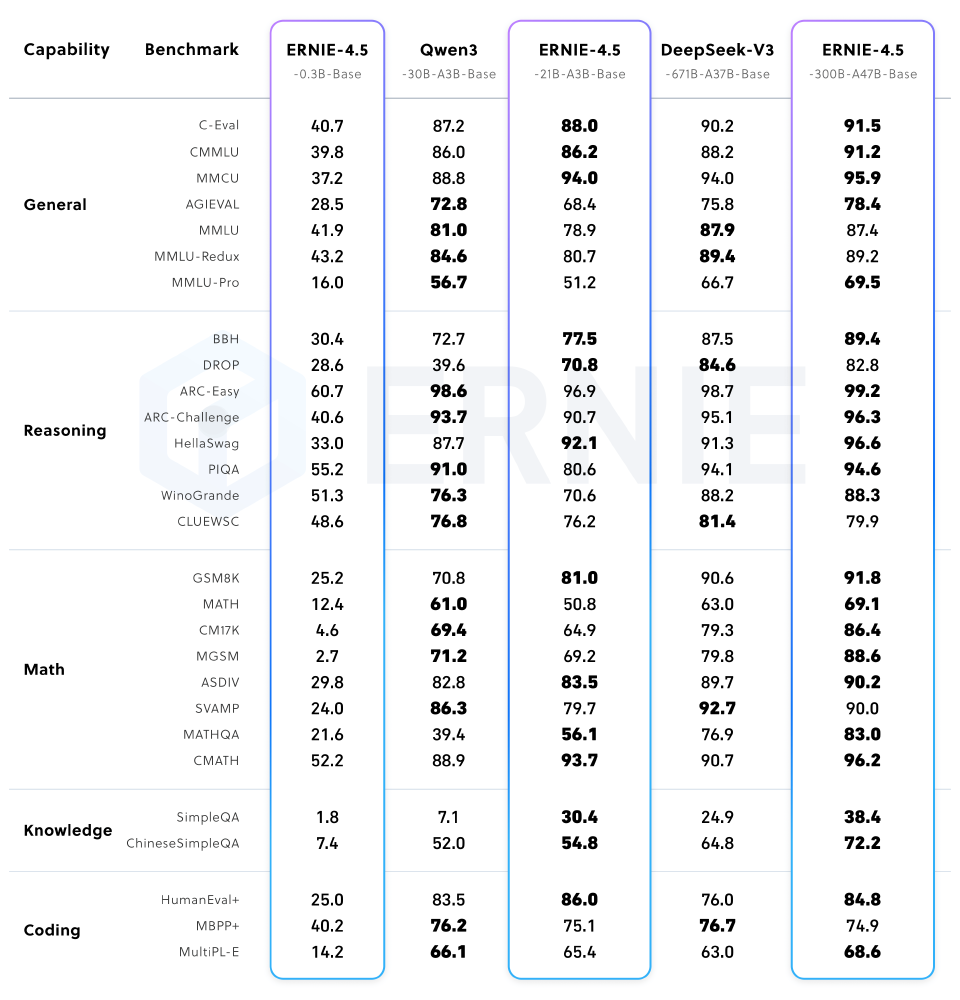
这张图片展示了ERNIE-4.5-21B-A3B-Base模型在通用、推理、数学、知识、编码等多能力类别下的基准测试性能对比表格。从图中可以看出,ERNIE-4.5-21B-A3B尽管总参数量仅为210亿(约为竞品30B模型的70%),但在包括BBH和CMATH在内的多个数学和推理基准上效果更优,实现了"以小胜大"的性能突破。
行业影响与落地案例
金融领域:智能投研效率提升3倍
某头部券商基于ERNIE-4.5-21B-A3B构建智能投研助手,利用其128K超长上下文能力处理完整的上市公司年报(平均300-500页)。系统可自动提取关键财务指标、业务亮点和风险因素,生成结构化分析报告。
实测显示,分析师处理单份年报的时间从原来的4小时缩短至1.5小时,同时关键信息识别准确率提升至92%。这一应用直接解决了金融机构"行业分析耗时、信息提取不全面"的痛点,使分析师能将更多精力投入深度分析而非信息整理。
电商零售:商品内容生成成本下降62%
头部服饰品牌应用ERNIE 4.5后,新品上架周期从72小时缩短至4小时。模型通过文本专家分析流行趋势文案,生成精准商品描述。采用WINT2量化版本部署后,商品详情页生成API的单位算力成本下降62%,同时转化率提升17%,退货率下降28%。
这一案例验证了ERNIE 4.5-21B-A3B在降低企业AI应用成本方面的显著效果,特别适合对内容生成效率要求高、算力资源有限的中小企业。
企业级部署指南
ERNIE 4.5-21B-A3B提供灵活的部署选项,满足不同规模企业需求:
- 开发测试环境:单张80G GPU(WINT8量化)
- 生产环境:2张80G GPU(WINT2量化,TP2部署)
- 边缘设备:通过模型蒸馏获取的轻量级版本可部署于英特尔酷睿Ultra平台
部署命令示例:
python -m fastdeploy.entrypoints.openai.api_server \
--model https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-PT \
--port 8180 \
--max-model-len 32768 \
--quantization wint2
模型仓库地址:https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-PT
结论/前瞻
ERNIE 4.5-21B-A3B的开源标志着AI产业进入"效率优先"的新阶段。通过210亿总参数、30亿激活参数的异构MoE架构,该模型在保持高性能的同时,将部署成本降低75%,重新定义了大模型效率标准。
对于企业用户,建议重点关注三个应用方向:基于长上下文能力的企业知识库构建(支持百万级文档的智能检索)、低成本的文本生成与分析系统(降低内容创作门槛)、以及作为多模态应用的高效文本基座(为后续视觉能力扩展预留空间)。
随着ERNIE 4.5等高效模型的普及,AI技术正从少数科技巨头的专属能力,转变为各行业均可负担的普惠工具。在这场效率革命中,能够将通用模型与行业知识深度融合的实践者,将最先收获智能时代的红利。
【免费下载链接】ERNIE-4.5-21B-A3B-PT 项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-PT
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







