5分钟上手DeepEval追踪测试:从崩溃到稳定的LLM监控实战
 项目地址: https://gitcode.com/GitHub_Trending/de/deepeval
项目地址: https://gitcode.com/GitHub_Trending/de/deepeval 你是否经历过这样的困境:AI应用在开发环境表现完美,部署后却频繁出现幻觉回复、工具调用失败,甚至用户投诉回答不相关?传统测试只能覆盖预设场景,而真实世界的复杂交互往往成为漏网之鱼。DeepEval的追踪测试功能(Tracing)正是为解决这一痛点而生——它能像CT扫描一样透视LLM应用的每一个执行环节,让隐藏的问题无所遁形。本文将带你掌握从代码埋点到异常诊断的全流程,最终实现关键功能的持续验证。
为什么需要LLM追踪测试?
在传统软件中,单元测试和集成测试足以覆盖大部分场景。但LLM应用的"黑箱"特性使其难以捉摸:同样的输入可能因上下文变化产生截然不同的输出,工具调用链的某个微小偏差就可能导致整体功能失效。DeepEval的追踪系统通过以下核心能力解决这些挑战:
- 全链路可视化:将复杂的AI交互分解为可监控的单元(Span),形成清晰的执行时间线
- 组件级评估:对检索器、工具调用、LLM生成等独立模块进行精准测评
- 动态测试生成:基于实际运行数据创建测试用例,捕捉边缘场景
- 性能瓶颈定位:识别执行过程中的延迟节点和资源消耗峰值
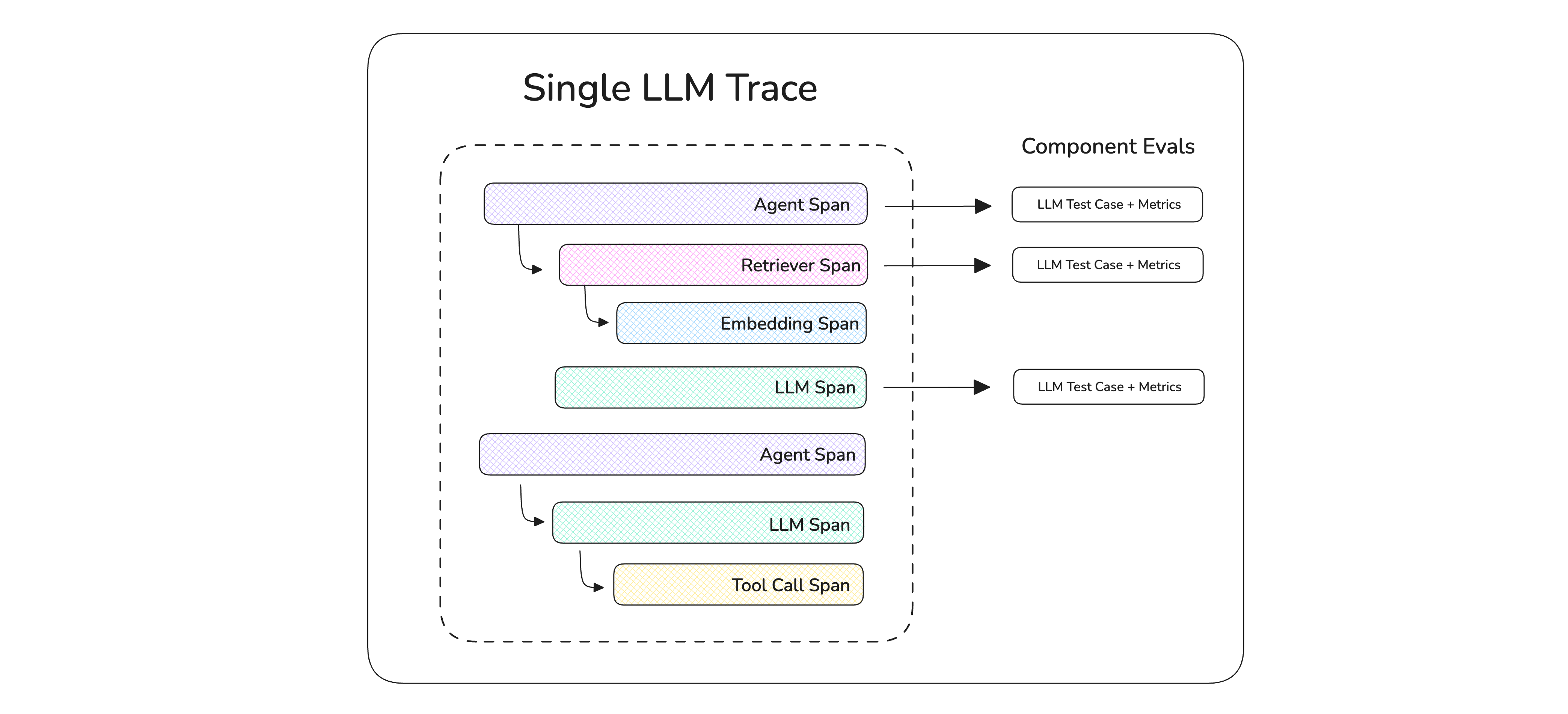
图1:DeepEval追踪系统将应用执行分解为嵌套的Span结构,每个组件操作都可独立评估
官方文档详细阐述了追踪功能的设计理念:LLM Tracing。与传统监控工具不同,DeepEval采用非侵入式设计,无需重构代码即可实现全方位监控。
快速入门:3步实现追踪埋点
第一步:安装与环境配置
首先确保DeepEval已正确安装。如果是新项目,通过以下命令快速初始化:
pip install deepeval
对于现有项目,可直接集成追踪模块。所有追踪相关的核心代码位于deepeval/tracing目录,主要包括装饰器、上下文管理和工具类。
第二步:核心API应用
DeepEval提供极简的埋点方式,只需两个核心API即可完成追踪配置:
- @observe装饰器:标记需要监控的函数或组件
- update_current_span:记录组件输入输出和上下文信息
以下是一个基础的RAG应用追踪示例,完整代码可参考examples/tracing/test_chatbot.py:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from openai import OpenAI
client = OpenAI()
@observe(type="retriever", name="文档检索器")
def retrieve(query: str) -> list[str]:
# 实际应用中这里会调用向量数据库
context = [f"关于{query}的参考文档片段1", f"关于{query}的参考文档片段2"]
update_current_span(
input=query,
retrieval_context=context
)
return context
@observe(type="llm", name="回答生成器", model="gpt-4o")
def generate_answer(query: str, context: list[str]) -> str:
prompt = f"基于以下信息回答问题:{context}\n问题:{query}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
).choices[0].message.content
update_current_span(
test_case=LLMTestCase(
input=query,
actual_output=response,
retrieval_context=context
)
)
return response
@observe(type="agent", name="RAG助手")
def rag_chatbot(query: str) -> str:
context = retrieve(query)
return generate_answer(query, context)
这个示例展示了典型的RAG应用三层结构:检索器→生成器→代理协调,每层都添加了类型标注和关键信息记录。当调用rag_chatbot("什么是DeepEval?")时,系统会自动生成包含三个嵌套Span的追踪记录。
第三步:执行与结果查看
运行应用后,追踪数据会自动收集。通过DeepEval CLI可查看基本统计:
deepeval logs show --last
对于可视化界面,推荐使用Confident AI平台(需单独注册),执行deepeval login后即可在控制台查看交互式追踪报告:
deepeval login
高级应用:从追踪到测试的闭环
动态测试用例生成
DeepEval的追踪系统不仅用于监控,还能基于实际运行数据自动创建测试用例。通过get_current_golden()方法可获取当前评估的基准用例,结合update_current_span实现动态断言:
from deepeval.dataset import get_current_golden
@observe(metrics=[AnswerRelevancyMetric(threshold=0.8)])
def critical_function(input: str):
result = process(input)
golden = get_current_golden() # 获取当前基准用例
update_current_span(
test_case=LLMTestCase(
input=input,
actual_output=result,
expected_output=golden.expected_output if golden else None
)
)
return result
这种方式特别适合持续集成环境,能自动将生产环境的真实交互转化为测试素材。
多维度性能分析
通过追踪数据,我们可以构建应用的性能画像。以下是一个简单的性能分析脚本,可集成到测试流程中:
from deepeval.tracing import get_trace_summary
def analyze_performance():
summary = get_trace_summary()
print(f"平均执行时间: {summary.average_duration}ms")
print(f"组件耗时分布: {summary.span_duration_distribution}")
print(f"失败率统计: {summary.failure_rates}")
# 识别慢组件
slow_spans = [s for s in summary.spans if s.duration > 1000]
if slow_spans:
print("需要优化的慢组件:")
for span in slow_spans:
print(f"- {span.name}: {span.duration}ms")
这个分析功能依赖于deepeval/tracing/trace_context.py中的上下文管理和指标收集逻辑。
最佳实践与避坑指南
1. 合理规划Span粒度
过细的Span划分会增加系统开销,过粗则失去诊断价值。建议遵循以下原则:
- 功能独立:每个Span应对应一个完整功能单元(如检索、生成、工具调用)
- 边界清晰:Span之间的调用关系应形成明确的树状结构
- 关键路径优先:优先追踪用户交互频繁的核心流程
参考示例项目中的分层设计:examples/tracing/test_chatbot.py将系统分为检索器、搜索工具、格式化器和LLM生成器等独立Span。
2. 上下文信息采集策略
有效诊断问题需要收集关键上下文,但过多数据会影响性能。推荐采集的核心字段:
- 输入输出:函数的主要参数和返回值
- 环境信息:模型类型、温度参数、工具版本
- 时间戳:开始/结束时间、耗时统计
- 错误信息:异常堆栈、错误码、重试次数
通过update_current_span的灵活参数实现按需采集:
update_current_span(
input=user_query,
output=final_answer,
metadata={
"model_used": "gpt-4o",
"temperature": 0.7,
"tool_calls": ["search", "calculator"]
}
)
3. 生产环境优化
在生产环境使用时,可通过环境变量控制追踪行为:
# 禁用详细日志
CONFIDENT_TRACE_VERBOSE=0
# 批量处理追踪数据(减少IO)
CONFIDENT_TRACE_FLUSH=0
完整的环境变量配置说明见docs/docs/evaluation-llm-tracing.mdx。
常见问题与解决方案
Q: 追踪功能会影响应用性能吗?
A: DeepEval采用惰性计算和异步处理机制,正常情况下性能损耗<5%。可通过type参数指定Span类型,实现针对性监控,进一步降低开销。
Q: 如何处理分布式系统的追踪?
A: 对于微服务架构,可通过trace_id跨服务传递上下文。核心实现参考deepeval/tracing/trace_context.py中的上下文变量管理。
Q: 能否与现有测试框架集成?
A: 完全兼容pytest等主流测试工具。可将追踪数据转化为测试报告,示例见tests/test_core/test_tracing/目录下的测试用例。
总结与进阶路线
通过本文介绍的追踪测试框架,你已掌握LLM应用的全链路监控能力。下一步可深入以下高级主题:
- 自定义指标开发:基于追踪数据创建业务特定的评估指标,参考docs/docs/metrics-custom.mdx
- CI/CD集成:将追踪分析纳入持续集成流程,实现自动回归测试
- 多模态追踪:扩展追踪能力到图像、语音等多模态交互场景
完整的API文档和进阶教程可在官方文档中找到。DeepEval的追踪系统正在快速迭代,欢迎通过CONTRIBUTING.md参与开发贡献。
掌握追踪测试,让你的AI应用从"黑箱"变为"透明可控"的智能系统,为用户提供稳定可靠的服务体验。立即开始在项目中集成DeepEval追踪功能,开启AI应用质量保障的新范式!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







