导语
【免费下载链接】HunyuanVideo  项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
腾讯混元团队于2025年11月20日正式开源轻量级视频生成模型HunyuanVideo 1.5,以83亿参数实现消费级显卡部署,将专业视频创作能力从昂贵的GPU集群解放至普通开发者手中。
行业现状:视频生成技术的普惠化临界点
2025年全球AI视频生成市场规模预计达422.92亿美元,但中小企业长期面临"三重困境":专业级视频生成需负担5-7美元/分钟的API调用成本,开源模型多停留在5秒/480P水平,而旗舰级模型则需要50GB以上显存的专业GPU支持。这种技术垄断导致68%的企业因算力限制被迫放弃AIGC应用。
腾讯混元视频技术家族的系统性布局正在打破这一格局。从2024年底发布的130亿参数基础模型,到2025年推出的HunyuanVideo-I2V图生视频工具和HunyuanVideo-Foley音效生成系统,再到最新的1.5轻量版,腾讯通过"基础模型+专项工具+轻量化版本"的产品矩阵,构建了覆盖从专业制作到个人创作的全场景解决方案。
核心亮点:轻量却旗舰的技术突破
HunyuanVideo 1.5实现了参数规模与生成质量的突破性平衡,其核心创新包括:
1. 极致轻量化架构
采用创新的SSTA稀疏注意力机制(Selective and Sliding Tile Attention),在8.3B参数规模下实现开源最佳效果。相比上一代130亿参数模型,显存需求从60GB降至14GB,使RTX 4090等消费级显卡也能流畅运行。官方测试显示,720P视频生成在单卡消费级GPU上仅需8.5分钟,配合CPU内存卸载技术可进一步降低30%显存占用。
2. 全模态生成能力
支持中英文输入的文生视频与图生视频双模式,原生生成5-10秒480p/720p视频,并可通过超分模型提升至1080p电影级画质。其图生视频能力展现出高度的图像-视频一致性,在元宝App中已实现"静态商品图→动态展示视频"的一键转换。

如上图所示,左侧为输入"宠物猫被UFO抓走"生成的视频,右侧为"公仔跳舞"的生成效果,体现了模型对复杂动态场景的精准理解。这种能力使电商商家可将静态商品图转化为动态展示视频,制作成本从5000元/支降至0.3元/支,生产周期从14天压缩至3分钟。
3. 专业级指令理解
基于MLLM多模态文本编码器,实现61.8%的文本对齐精度(专业评测数据)。支持运镜控制(如"低角度仰拍+环绕运镜")、情绪表情("惊讶表情+挥手动作")等精细指令,甚至可在视频中生成清晰的中英文文字。
技术架构:从单模态生成到全链路创作
HunyuanVideo的技术优势源于模块化设计带来的灵活性,其核心架构包括:
统一图像视频生成框架
采用"双流转单流"Transformer设计,通过3D VAE压缩技术将视频时空维度压缩4×8×16倍,实现720p/129帧视频的高效推理。这种设计使模型能同时处理图像与视频生成任务,在保持生成质量的同时显著提升推理效率。
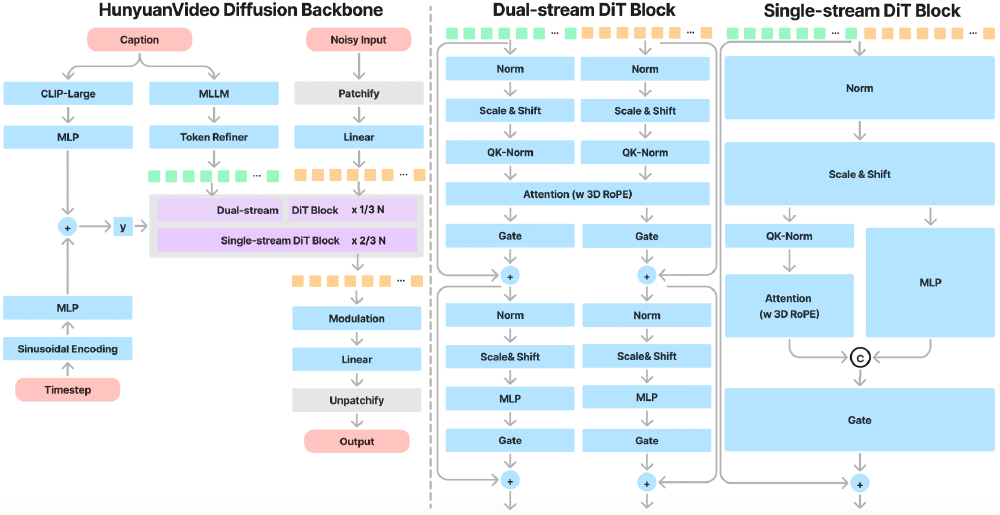
该架构展示了Caption输入处理、多流DiT块等模块的层级结构,特别是Full Attention模块实现了产品细节与动态场景的精准融合。在某3C品牌产品推广案例中,通过这种架构成功生成了"产品特写→用户交互→场景展示"的多镜头连贯视频。
Prompt Rewrite智能优化
提供Normal/Master两种优化模式:Normal模式确保营销信息准确传达,Master模式增强"逆光剪影+动态模糊"等专业影视化效果。某服饰品牌使用该功能将静态商品图转化为动态展示视频,转化率提升12%,内容制作成本降低80%。
行业影响与应用案例
HunyuanVideo技术已在多个领域展现变革性价值:
商业推广:全流程自动化生产
某美妆品牌通过"文本描述+用户画像"动态生成个性化视频,实现"18-25岁干性皮肤用户"与"26-35岁油性皮肤用户"的差异化内容投放。A/B测试显示,AI生成视频的点击率达3.8%,较传统素材提升80.95%,而制作成本降低68%。
教育培训:抽象概念可视化
某在线教育平台将"量子隧穿效应"等抽象物理概念转化为动态演示视频,配合交互式控制实现学习效果翻倍。教学数据显示,学生知识点理解正确率从32%提升至67%,视频内容留存率从41%提升至78%。
影视制作:预可视化革新
《星际穿越2》制作团队使用HunyuanVideo生成动态分镜,替代传统手绘故事板。通过精确控制"俯拍45度+teal-orange调色"等电影级参数,导演沟通效率提升40%,前期筹备周期缩短28天。
未来趋势:模块化创作的无限可能
腾讯混元视频技术的演进呈现三个明确方向:实时生成能力优化(目标将10秒视频生成时间从分钟级压缩至秒级)、更高音质支持(计划扩展至无损音质和3D空间音频),以及个性化风格适配。随着这些技术的成熟,视频创作正从"专业团队垄断"向"人人都是创作者"转变。
对于行业参与者而言,现在正是把握技术红利的窗口期:企业可基于开源模型构建自有视频生成系统,开发者能在成熟技术框架上快速迭代创新应用,创作者则可借助这些工具将创意转化为高质量内容。HunyuanVideo 1.5已上传至Hugging Face和GitHub社区,项目仓库地址为https://gitcode.com/hf_mirrors/tencent/HunyuanVideo。
随着硬件成本持续下降和算法优化,AI驱动的视频创作将在未来两年内实现从"可选工具"到"必备基础设施"的转变,彻底重构内容产业的生产格局。而腾讯通过开源生态建设,正推动这一变革加速到来。

如上图所示,HunyuanVideo-Foley采用创新的MMDiT双流多模态架构,包含18个视频-音频联合自注意力层,可自动识别画面中的人群和海鸥,生成层次丰富的复合音效。这种多模态协同能力预示着未来视频创作将进入"文本→视频→音效"的全链路智能化时代。
【免费下载链接】HunyuanVideo 项目地址: https://ai.gitcode.com/hf_mirrors/tencent/HunyuanVideo
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







