导语
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Apriel-1.5-15b-Thinker
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Apriel-1.5-15b-Thinker 当企业还在为千亿级大模型的部署成本望而却步时,ServiceNow推出的Apriel-1.5-15B-Thinker以150亿参数实现了与主流大模型相当的推理能力,将企业级AI部署成本从20万元降至2万元以内,单GPU即可运行的特性让中小企业首次触及前沿AI技术。
行业现状:大模型"瘦身革命"与多模态刚需
2025年,AI行业正经历从"唯参数论"到"效率优先"的范式转移。Gartner数据显示,全球多模态AI市场规模将从2025年的24亿美元飙升至2037年的989亿美元,制造业质检、金融文档分析、医疗影像识别等场景对文本与图像协同理解的需求激增。然而,传统千亿级模型动辄上千万元的部署成本,让85%的中小企业被挡在AI门槛之外。
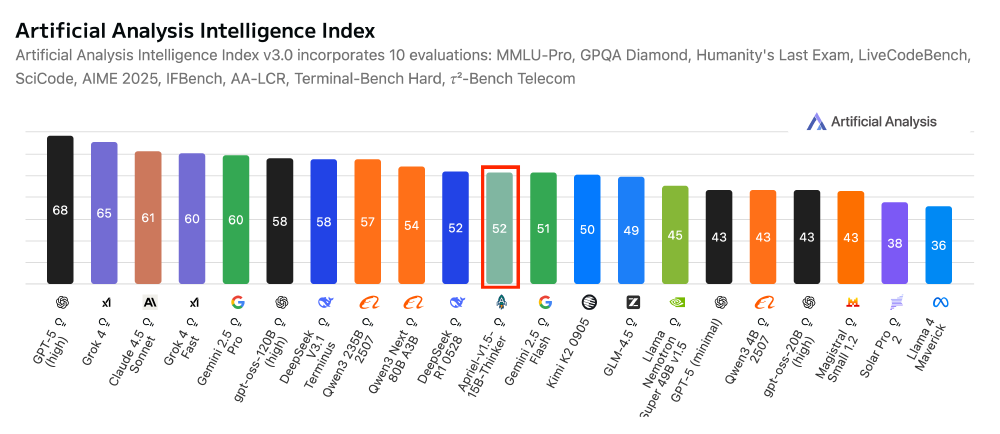
在此背景下,Apriel-1.5-15B-Thinker的出现恰逢其时。这款模型在Artificial Analysis指数中获得52分,与DeepSeek R1 0528、Gemini-Flash等主流模型持平,而体量仅为同类产品的1/10,重新定义了"小而强"的技术标准。
核心亮点:三阶段训练实现效率突破
Apriel-1.5-15B-Thinker的突破源于其创新的"Mid training is all you need"研发理念,通过三个阶段实现性能跃升:
1. 极致性能体积比

如上图所示,柱状图清晰呈现了Apriel-1.5-15B-Thinker在Artificial Analysis Intelligence Index的10项评估指标中与主流模型的对比。该模型不仅在数学推理(AIME2025准确率87%)、指令跟随(IFBench 62分)等任务上表现突出,更在电信行业专业测试Tau2 Bench Telecom中斩获68分,证明轻量级模型同样能深度适配企业级场景。
2. 零图像微调的跨模态迁移
传统多模态模型需同时进行文本与图像微调,而Apriel-1.5-15B-Thinker通过创新训练策略,在未进行专门图像SFT的情况下,仅依靠多模态预训练和文本微调实现图像推理能力。这种设计使模型在640×H100 GPU集群上7天即可完成训练,研发成本降低60%。
3. 企业级部署友好性
模型原生支持单GPU运行,内存占用控制在14GB以内,消费级显卡即可流畅推理。提供vLLM部署方案和工具调用接口,与现有系统无缝集成:
# 基础调用示例
from transformers import AutoProcessor, AutoModelForImageTextToText
model_id = "ServiceNow-AI/Apriel-1.5-15b-Thinker"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_id)
行业影响:中小企业的AI普惠时代
Apriel-1.5-15B-Thinker的出现正在重塑企业AI应用格局:
1. 部署成本下降90%
某制造业案例显示,基于该模型构建的质检系统硬件投入减少75%,仍保持92%的识别准确率,缺陷识别效率提升3倍。这种"低成本高精度"特性使中小企业首次具备AI落地能力。
2. 垂直领域应用加速渗透
- 金融服务:合同审查、财报分析效率提升40%
- 智能制造:设备故障诊断响应时间缩短至秒级
- 医疗健康:便携式影像分析工具成本降低80%
未来趋势:从"大而全"到"专而精"
如上图所示,曲线揭示了AI模型正从"参数军备竞赛"转向"效率优化"的发展趋势。Apriel-1.5-15B-Thinker证明,通过精心设计的训练策略和高质量数据,中等规模模型完全能达到甚至超越大模型性能。ServiceNow团队表示,未来将进一步优化低光照图像识别和多语言视觉推理能力,推动模型向边缘计算场景拓展。
对于企业而言,现在正是布局轻量级AI的战略窗口期。建议优先聚焦质检、文档分析等高价值场景,采用"混合部署"策略(核心业务本地化+非核心业务API调用),逐步构建AI能力闭环。随着开源生态的完善,轻量级多模态模型有望成为企业数字化转型的新基建。
结语
Apriel-1.5-15B-Thinker以150亿参数撬动千亿级能力,不仅是技术突破,更代表着AI普惠化的必然趋势。当中小企业也能以"万元级"成本部署企业级推理能力,AI技术将真正从实验室走向生产一线,催生更多行业创新应用。正如ServiceNow研究者所言:"未来的AI竞争,将是智慧设计而非蛮力扩张的竞争。"
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







