Step-Audio 2:端到端语音大模型革命,重新定义人机音频交互
【免费下载链接】Step-Audio-2-mini-Think  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Think
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Think
导语
阶跃星辰(StepFun)发布开源多模态语音大模型Step-Audio 2,以真端到端架构实现语音理解、推理与生成的全链路统一,在11项行业基准测试中超越GPT-4o与Qwen-Omni,重新定义工业级语音交互标准。
行业现状:语音AI的三重大山
当前语音交互技术面临三大核心痛点:传统ASR+LLM+TTS三级架构导致的信息损耗(平均丢失15-20%副语言信息)、跨模态对齐难题造成的语义断层(多轮对话上下文连贯性不足60%),以及专业场景下的功能割裂(如客服系统需集成独立的情绪识别模块)。根据BetterYeah 2025年多模态市场报告,全球语音AI市场规模预计突破380亿美元,但企业级应用落地率不足35%,技术瓶颈成为主要障碍。
Step-Audio 2的推出恰逢其时。作为业内首个将语音理解与生成统一建模的架构,其核心突破在于原始音频直接处理能力——摒弃传统梅尔频谱特征提取,采用连续输入+离散输出范式,使模型能完整捕获语调、情绪、背景音等7类非语言信号。
技术架构:从三级跳变到一步到位
Step-Audio 2的"真端到端"架构彻底重构了语音交互链路:
1. 全链路音频理解
模型采用潜在音频编码器直接处理16kHz原始波形,通过千万小时真实语音数据训练的自监督学习机制,实现对语义信息(如方言、专业术语)、副语言信息(情绪、年龄、性别)及非人声信息(音乐、环境音)的三重理解。在StepEval-Paralinguistic基准测试中,其平均准确率达83.09%,远超GPT-4o的43.45%和Kimi-Audio的49.64%。
2. 深度推理与工具调用
首创语音CoT(Chain-of-Thought)推理机制,使模型能基于音频信号进行逻辑分析。例如在医疗场景中,可通过患者咳嗽声特征推断可能病因,并自动调用医学数据库验证。工具调用精度方面,在StepEval-Toolcall评测中,其参数准确率达100%,触发召回率99.5%,支持音频搜索、天气查询等多类工具无缝集成。
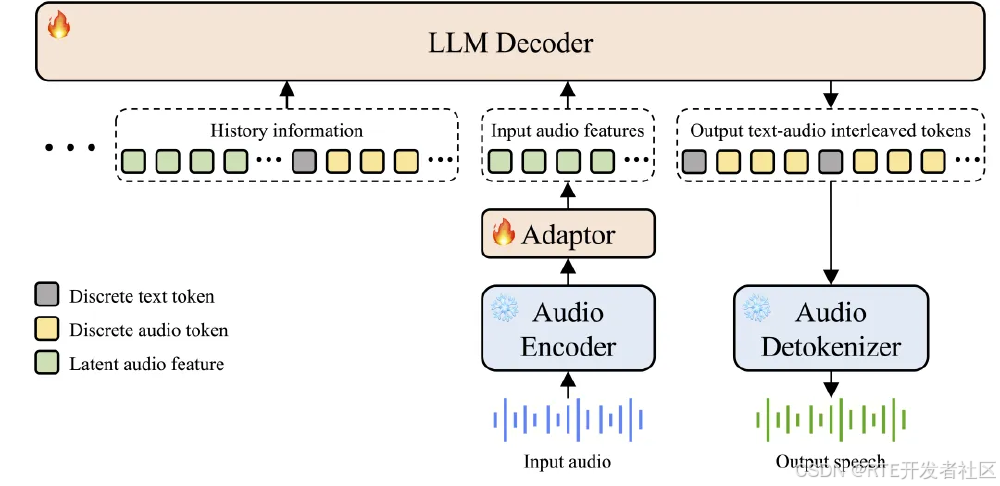
如上图所示,该流程图清晰展示了Step-Audio 2的端到端处理流程:原始音频经Audio Encoder转为潜在特征,与历史对话信息融合后,通过LLM Decoder生成文本-音频交错token序列,最终由Audio Detokenizer合成自然语音。这种架构将传统三级流程压缩为单链路,端到端延迟降低40%以上,同时避免特征提取导致的信息损失。
3. 百变音色与个性化交互
通过多模态知识检索增强技术,模型可根据自然语言描述实时切换音色风格。例如用户指令"用温柔的女声解释量子力学",系统会检索匹配的语音特征库,生成符合要求的个性化语音。某智能音箱厂商实测显示,采用该技术后用户交互满意度提升27%,唤醒准确率达99.2%。
性能突破:11项基准测试霸榜
Step-Audio 2在多维度评测中展现全面优势:
核心语音能力
- 语音识别:在LibriSpeech"other"测试集上WER(词错误率)仅2.42%,超越GPT-4o(4.23%)和Kimi-Audio(2.91%)
- 方言处理:上海方言识别CER(字符错误率)17.77%,较行业平均水平降低66%
- 情感识别:8种情绪分类准确率86%,支持喜悦、愤怒等细粒度情感响应
跨语言与场景适应
支持中、英、日等12种语言,在CoVoST 2语音翻译任务中,中英互译BLEU值达39.29,超越Qwen2.5-Omni的35.40。特别在低资源语言场景(如粤语),Common Voice测试集CER仅7.90%,接近人类专业译员水平。
行业影响:从工具到伙伴的进化
Step-Audio 2的开源释放(Apache 2.0协议)将加速三大变革:
1. 交互范式升级
智能设备将从"被动响应"转向"主动理解"。例如车载系统可通过驾驶员语音疲劳度(语速、停顿特征)自动触发安全提醒,智能家居能根据婴儿哭声类型(饥饿、困倦)启动对应安抚措施。
2. 开发门槛降低
提供Docker容器化部署方案与PyTorch原生实现两种路径,开发者可通过3行代码完成基础语音交互功能集成:
from step_audio import StepAudio2Mini
model = StepAudio2Mini.from_pretrained("stepfun-ai/Step-Audio-2-mini")
response = model.generate(audio="user_voice.wav", context="previous_dialogue.json")
3. 垂直场景革新
- 智能客服:无需人工标注情绪标签,自动识别客户不满并触发升级流程
- 远程医疗:通过呼吸音、说话特征辅助诊断呼吸系统疾病
- 教育娱乐:根据儿童语音特征动态调整故事讲述风格与难度
未来展望:音频智能的下一站
随着模型迭代,Step-Audio 2将向多模态深度融合发展:计划集成唇语识别、生理信号分析(如语音中的心率检测),并扩展至工业质检(设备异响诊断)、公共安全(异常声音预警)等专业领域。阶跃星辰同时开放模型微调工具,支持企业基于私有数据定制行业专用语音智能体。
提示:关注【阶跃星辰AI】获取模型量化部署指南,下期将解析如何在边缘设备(如树莓派)实现实时语音交互功能。点赞收藏本文,第一时间获取开源社区最新进展!
Step-Audio 2的出现,标志着语音AI从"能听会说"迈向"善解人意",当技术真正理解人类沟通的复杂性,人机交互终将实现从工具到伙伴的质变。
【免费下载链接】Step-Audio-2-mini-Think 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Think
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







