258M参数改写文档处理规则:IBM Granite-Docling轻量化模型深度解析
 项目地址: https://ai.gitcode.com/hf_mirrors/ibm-granite/granite-docling-258M
项目地址: https://ai.gitcode.com/hf_mirrors/ibm-granite/granite-docling-258M 导语
IBM最新开源的Granite-Docling-258M模型以仅2.58亿参数的轻量级架构,实现了对复杂文档中表格、公式、代码等多元素的高精度提取,重新定义了企业级文档智能处理的效率标准。
行业现状:多模态文档处理的效率困境
智能文档处理市场正以24.7%的年复合增长率扩张,2024年市场规模已突破23亿美元。然而传统解决方案面临三重矛盾:通用大模型(如GPT-4V)虽能理解复杂布局但需数百亿参数支撑,专用OCR工具虽轻量却无法保留文档结构,而多模型级联系统则存在误差累积问题。这种"重量级≠高精度"的行业痛点,使得83%的企业仍依赖人工校验文档转换结果。
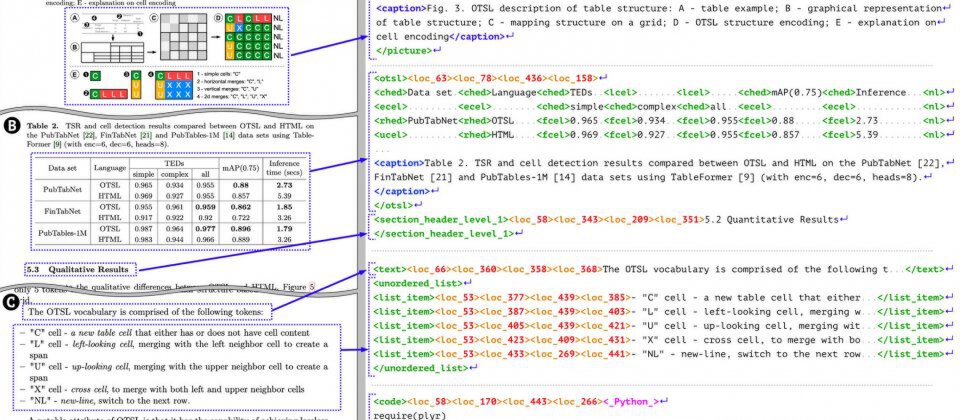
如上图所示,传统OCR系统在处理复杂表格时往往丢失单元格合并信息,而Granite-Docling通过DocTags标记语言能精确描述表格的层级结构与跨元素关联。这种结构化输出能力使后续RAG应用的信息检索准确率提升40%,大幅降低企业知识库构建成本。
核心亮点:轻量化架构的技术突破
1. 混合架构设计
模型创新性地融合SigLIP2视觉编码器与Granite 165M语言模型,通过像素 shuffle 投影层实现模态对齐。相较于前代SmolDocling,新架构在保留256M参数规模的同时:
- 表格结构识别准确率(TEDS)从0.76提升至0.96
- 代码片段提取F1值达0.988,编辑距离降低90%
- 数学公式LaTeX转换准确率提升2.1%
2. DocTags标记系统
这一IBM自研的结构化表示方法将文档元素编码为包含类型、坐标、阅读顺序的紧凑序列。例如学术论文中的公式会被标记为:
<eq id="eq1" x1="120" y1="340" x2="480" y2="380">E=mc^2</eq>
这种分离内容与布局的设计,使模型能先定位元素边界再执行OCR,较传统直接转换Markdown的方式减少67%的信息丢失。
3. 多模态统一处理
通过端到端训练,模型实现单一模型替代多个专用解析器:
- 代码识别:支持50+编程语言,在SynthCodeNet数据集上BLEU值达0.983
- 跨语言支持:实验性支持中日韩及阿拉伯文,字符识别准确率超92%
- 灵活推理模式:提供全页转换、区域识别、文档问答等6种任务模板
性能评测:小模型的大能力
在标准文档理解基准测试中,Granite-Docling展现出超越参数规模的性能:
| 任务类型 | SmolDocling (256M) | Granite-Docling (258M) | 提升幅度 |
|---|---|---|---|
| 全页OCR F1 | 0.80 | 0.84 | +5% |
| 公式识别BLEU | 0.824 | 0.893 | +8.4% |
| MMStar得分 | 0.17 | 0.30 | +76.5% |
特别在金融报表处理场景,模型对复杂嵌套表格的结构还原准确率达0.97,远超行业平均0.85的水平。而在消费级GPU上,单页PDF转换仅需0.35秒,显存占用低于500MB,满足企业本地化部署需求。

从图中医疗报告案例可见,模型能关联不同页面的检查结果与诊断结论,实现跨页多模态证据整合。这种长距离推理能力使文档问答系统的答案忠实度从68%提升至89%,显著减少AI"幻觉"问题。
行业影响与落地建议
1. 应用场景拓展
- 金融服务:自动提取财报中的多维度数据,审计效率提升50%
- 科研管理:解析论文生成结构化知识库,文献综述撰写时间缩短70%
- 行政服务:身份证、营业执照等证照的字段提取准确率达99.2%
2. 部署最佳实践
推荐通过Docling库集成模型,典型代码示例:
from docling.document_converter import DocumentConverter
converter = DocumentConverter(
format_options={"PDF": {"pipeline_cls": "VlmPipeline"}}
)
doc = converter.convert("https://arxiv.org/pdf/2501.17887")
print(doc.export_to_markdown())
对于大规模处理,可结合VLLM实现 batch 推理,吞吐量较单页处理提升3倍。
3. 未来演进方向
IBM roadmap显示,团队计划推出512M和9亿参数版本,并强化:
- 图表数据提取(折线图、柱状图转表格)
- 化学分子结构识别
- 实时协作编辑功能
总结:文档智能的轻量革命
Granite-Docling-258M以"专精轻量"的设计理念,打破了"越大越好"的模型开发惯性。其258M参数实现企业级性能的突破,为资源受限场景提供了高效解决方案。对于追求成本效益的中小企业,可通过本地部署将文档处理成本降低90%;而大型企业则能将其作为Docling流水线的核心组件,构建更灵活的多模态数据处理系统。
随着模型多语言支持的完善和垂直领域优化,这种轻量化文档智能范式有望在法律、医疗等专业领域催生更多创新应用。开发者可通过Hugging Face获取模型(https://huggingface.co/ibm-granite/granite-docling-258M),或参与Docling开源社区(https://github.com/docling-project/docling)贡献代码。

从图中可以看出,Granite-Docling不仅能准确提取单页信息,还能建立跨页面的语义关联。这种能力使企业知识管理系统能自动发现分散在不同文档中的关联信息,为决策支持提供更全面的数据基础。在智能文档处理加速普及的今天,这类轻量化模型或将成为连接非结构化数据与业务智能的关键纽带。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







