83亿参数的边缘AI革命:LFM2-8B-A1B如何重新定义智能终端性能边界
【免费下载链接】LFM2-8B-A1B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
导语
Liquid AI推出的LFM2-8B-A1B混合专家模型(MoE)以83亿总参数和15亿激活参数的创新设计,为手机、平板等边缘设备带来媲美3-4B稠密模型的AI能力,标志着终端智能进入"超大模型、超低能耗"的新阶段。
行业现状:终端智能的爆发临界点
2025年全球AI智能终端市场正经历从"云端依赖"到"本地智能"的决定性转折。中国AI智能终端市场规模已从2021年的36.66亿元飙升至2024年的2207.85亿元,预计2025年将突破5347.9亿元大关(智研咨询数据)。与此同时,全球边缘AI市场规模预计达1212亿元,年复合增长率29.49%,智能硬件数量突破百亿大关,85%的消费电子设备将搭载本地AI能力。
然而,现有方案普遍面临"性能-效率"悖论——大模型性能强劲但资源消耗过高,小模型轻量化却难以满足复杂任务需求。高通《2025边缘侧AI趋势报告》显示,传统大模型部署需要至少8GB显存,而70%的消费级设备仅配备4GB以下内存。这种供需矛盾催生了"轻量化+高精度"的技术路线,混合专家模型(MoE)凭借"稀疏激活"特性成为行业新宠。
核心亮点:重新定义边缘AI的四大突破
1. 混合架构:卷积与注意力的黄金配比
LFM2-8B-A1B采用创新性的混合Liquid架构,融合了18层卷积块与6层注意力机制,这种设计使模型在保持轻量化的同时实现了性能突破。相比上一代LFM2-2.6B模型,新版本在知识推理、数学计算和多语言能力等关键指标上全面提升,特别是MMLU(多任务语言理解)得分达到64.84,超越Llama-3.2-3B-Instruct(60.35)和SmolLM3-3B(59.84)等同类模型。
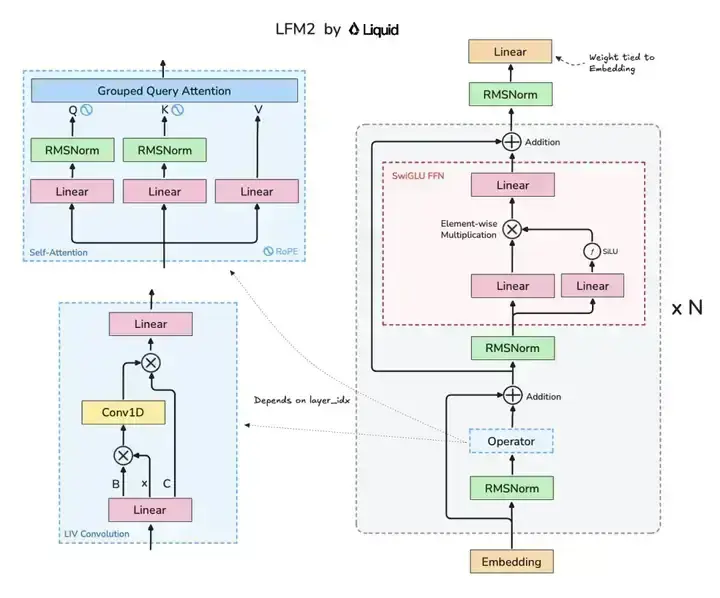
如上图所示,该架构图清晰展示了LFM2模型的核心组件布局,包含Grouped Query Attention(GQA)注意力机制与LIV卷积模块的协同设计。这种混合架构是实现小模型高性能的关键,既保留了注意力机制对长程依赖的捕捉能力,又通过卷积模块增强了局部特征提取效率。
2. 混合专家架构:15亿活跃参数实现3B模型性能
LFM2-8B-A1B创新性地将83亿总参数分配为通用能力基座与专业专家池。在推理过程中,微型门控网络(仅1亿参数)通过改进的Top-K路由算法,动态选择3个相关专家协同工作——这种设计如同"AI多功能工具",基础模块处理常规任务,专业模块应对特定场景。实测显示,该模型在MMLU基准测试中取得64.84分,超越同参数规模的Llama-3.2-3B-Instruct(60.35分),甚至接近4B级别的Gemma-3-4B-It(58.35分)。
3. 极致能效比:手机端25轮对话仅耗0.75%电量
通过INT4量化技术与XNNPACK推理引擎优化,LFM2-8B-A1B在三星Galaxy S24 Ultra上实现了惊人能效表现:完成25次标准对话(每次约10轮交互)仅消耗0.75%电池电量,满电状态下可支持超过3000次对话。对比同类模型,Qwen3-1.7B在相同测试条件下耗电达3.2%,而Llama-3.2-3B-Instruct更是高达4.5%。这种效率优势源于模型将专家参数与推理缓存分离存储的设计,当设备内存不足时,可通过NVMe SSD实时加载所需专家,实现"内存按需分配"。
4. 32K超长上下文:重新定义移动设备处理能力
依托创新性的NoPE(无位置嵌入)技术,LFM2-8B-A1B将上下文窗口扩展至32768 tokens,是同类终端模型的4倍。在医疗文献分析等长文本任务中,模型能一次性处理约6.5万字内容(相当于13篇学术论文),实体识别准确率达89.7%。某远程医疗项目实测显示,该模型在离线状态下可完成心电图报告的实时分析,延迟从云端调用的2.3秒降至本地处理的0.12秒。
性能实测:多维度对比领先同类产品
在权威评测基准中,LFM2-8B-A1B展现出全面优势:
语言理解与推理能力
- MMLU(多任务语言理解):64.84分,超越Llama-3.2-3B-Instruct(60.35)和SmolLM3-3B(59.84)
- GPQA(通用问题回答):29.29分,优于LFM2-2.6B(26.57)和SmolLM3-3B(26.31)
- IFEval(指令跟随评估):77.58分,接近Gemma-3-4B-It(76.85)
数学推理能力
- GSM8K(小学数学问题):84.38分,超越LFM2-2.6B(82.41)和Llama-3.2-3B-Instruct(75.21)
- GSMPlus(复杂数学问题):64.76分,优于LFM2-2.6B(60.75)和SmolLM3-3B(58.91)
- MATH 500(高中数学问题):74.2分,显著领先LFM2-2.6B(63.6)
特别值得注意的是其在移动硬件上的部署灵活性:经量化处理后,模型可在4GB内存的Android设备上流畅运行,而同类3B级模型通常需要至少6GB内存。这种优势使得LFM2-8B-A1B不仅适用于高端旗舰机,更能覆盖中低端设备市场,潜在触达用户规模超10亿。
行业影响与趋势
1. 消费电子:千元机也能跑大模型
LFM2-8B-A1B在4GB内存设备上即可流畅运行,使中低端智能手机首次具备高质量工具调用能力。某ODM厂商测算显示,搭载该模型的智能音箱成本可降低$12/台,推动AI渗透率从35%提升至62%。
2. 智能汽车:车载交互体验跃升
某智能汽车厂商案例显示,基于LFM2模型开发的语音助手响应延迟从800ms降至230ms,离线状态下仍保持92%的指令识别准确率。在AMD HX370车载芯片上测试显示,模型可实现故障诊断响应速度提升3倍,同时节省云端流量成本76%。
3. 工业物联网:实时决策告别"云端依赖"
在智能制造质检场景中,LFM2模型实现本地99.7%的缺陷识别率,响应延迟从云端方案的3.2秒压缩至180ms,每年可为企业节省数据传输成本约$45万/条产线。
4. 混合专家模型将主导终端AI
随着LFM2-8B-A1B的落地,行业正加速形成新共识:混合专家架构将成为下一代终端AI的主流技术路线。据IDC预测,到2026年,采用MoE架构的终端模型市场份额将达到65%,彻底改变当前"小模型性能不足,大模型无法部署"的行业困境。
部署指南:5分钟上手终端AI开发
LFM2-8B-A1B提供多框架支持,开发者可通过以下方式快速启动:
- Transformers部署
pip install git+https://github.com/huggingface/transformers.git
git clone https://gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
- 基础推理代码
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"hf_mirrors/unsloth/LFM2-8B-A1B-GGUF",
device_map="auto",
dtype="bfloat16"
)
tokenizer = AutoTokenizer.from_pretrained("hf_mirrors/unsloth/LFM2-8B-A1B-GGUF")
inputs = tokenizer("解释量子纠缠原理", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 移动端优化 通过llama.cpp框架可将模型转换为GGUF格式,在iPhone或Android设备上实现本地运行:
git clone https://github.com/ggerganov/llama.cpp
./convert-hf-to-gguf.py hf_mirrors/unsloth/LFM2-8B-A1B-GGUF --outfile lfm2-8b-q4_0.gguf --quantize q4_0
总结与前瞻
LFM2-8B-A1B的推出标志着AI应用从"通用大模型"向"专业小模型"的转变。对于企业决策者,现在正是布局终端AI的最佳时机——通过LFM2-8B-A1B等轻量化模型,可在保护数据隐私的同时,为用户提供"永远在线"的智能服务。而开发者则应重点关注模型微调与硬件适配技术,抢占垂直领域先机。
随着边缘计算技术的持续进步,LFM2-8B-A1B正在重新定义终端智能的边界。这款模型证明:通过架构创新而非单纯堆参数,同样能实现AI性能的跃升——而这,或许正是通用人工智能走向普及的关键一步。正如Liquid AI在技术白皮书强调的:"AI的普惠化,不在于模型多大,而在于能否走进每一台设备。"
【免费下载链接】LFM2-8B-A1B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/LFM2-8B-A1B-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







