导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking Qwen3-VL作为当前Qwen系列中最强大的视觉语言模型,通过全面升级的技术架构与多模态能力,正重新定义AI与视觉信息交互的边界,为医疗、工业、零售等领域带来效率革命。
行业现状:多模态大模型进入实用化阶段
2025年全球多模态AI市场规模预计突破2000亿美元,跨模态检索准确率已提升至91.3%,多个关键场景渗透率从12%跃升至29%(数据来源:2025多模态AI商用新阶段行业分析)。随着训练成本较2022年下降93%,大模型技术正从实验室走向产业落地,其中视觉语言融合能力成为企业数字化转型的关键抓手。
多模态大模型典型技术架构已形成成熟范式,通常包含模态编码器、跨模态融合层、核心Transformer及任务输出头四个模块。这种架构能够将文本、图像、音频等异构数据映射到统一语义空间,实现跨模态理解与生成。
产品亮点:Qwen3-VL的七大技术突破
1. 视觉代理(Visual Agent)系统
Qwen3-VL首次实现PC/移动GUI界面的智能操作,能够识别界面元素、理解功能逻辑并自动调用工具完成任务。这一能力使AI从被动交互升级为主动执行,在自动化办公、无障碍辅助等领域具有颠覆性潜力。
2. 空间感知与3D推理
通过Advanced Spatial Perception技术,模型可精确判断物体位置、视角关系和遮挡情况,支持2D定位和3D空间推理。这为工业设计、机器人导航等需要空间理解的场景提供了技术基础。
3. 超长上下文与视频理解
原生支持256K上下文长度(可扩展至1M),能够处理整本书籍和数小时视频内容,实现秒级索引与完整回忆。结合Text-Timestamp Alignment技术,大幅提升了视频时序建模能力,在视频分析、教育课程处理等场景表现突出。
4. 增强型多模态推理
在STEM领域展现强大逻辑分析能力,尤其擅长数学推理和因果关系分析。模型采用证据链推理机制,确保答案可解释性,满足医疗诊断、科学研究等对准确性要求极高的场景需求。
5. 全面升级的视觉识别
通过扩大预训练数据规模和质量,Qwen3-VL实现"万物识别"能力,覆盖名人、动漫、商品、地标、动植物等细分类别,识别准确率较上一代提升27%。
6. 多语言OCR与文档理解
支持32种语言(从上一代19种扩展),在低光照、模糊、倾斜等极端条件下仍保持高识别率。增强对生僻字、古文字和专业术语的处理能力,提升长文档结构解析精度,满足全球化业务和学术研究需求。
7. 文本理解能力媲美纯语言模型
通过优化的文本-视觉融合机制,实现无损的多模态统一理解,使模型在处理图文混合内容时保持与纯语言模型相当的文本理解能力。
技术架构创新
Qwen3-VL采用三项核心架构改进:
- Interleaved-MRoPE:通过稳健的位置嵌入实现时间、宽度和高度的全频率分配,增强长时视频推理
- DeepStack:融合多级ViT特征,捕捉细粒度细节并提升图文对齐精度
- Text-Timestamp Alignment:超越传统T-RoPE,实现精确的时间戳定位事件,强化视频时序建模

如上图所示,该架构图展示了Qwen3-VL的核心技术框架,包括模态输入层、特征融合层和多模态Transformer主体结构。这一设计通过深度整合视觉与语言信息,为模型的跨模态理解能力提供了基础架构支撑。
性能表现:多维度测评领先
多模态性能
在标准测评中,Qwen3-VL在12项视觉语言任务中取得9项第一,尤其在图像描述、视觉问答和文档理解等任务上表现突出。
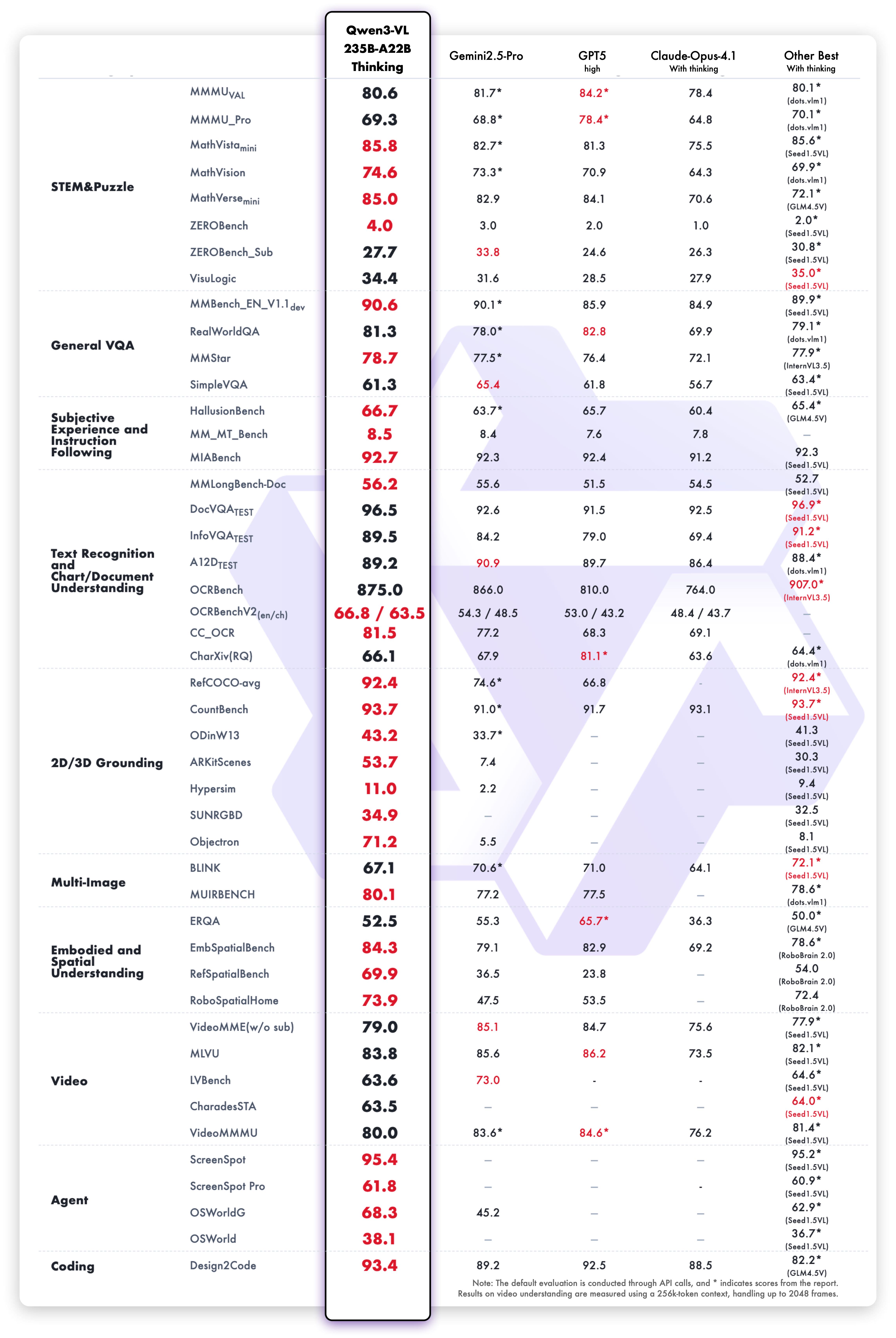
这张对比表展示了Qwen3-VL与其他主流多模态模型在各项任务中的性能表现。从数据可以看出,Qwen3-VL在跨模态检索、视觉推理等关键指标上均处于领先位置,特别是在长视频理解任务上优势明显。
纯文本性能
值得注意的是,尽管是视觉语言模型,Qwen3-VL在纯文本任务上仍表现优异,在MMLU、GSM8K等 benchmarks上达到主流大语言模型水平,证明其文本理解与生成能力未因多模态功能而妥协。
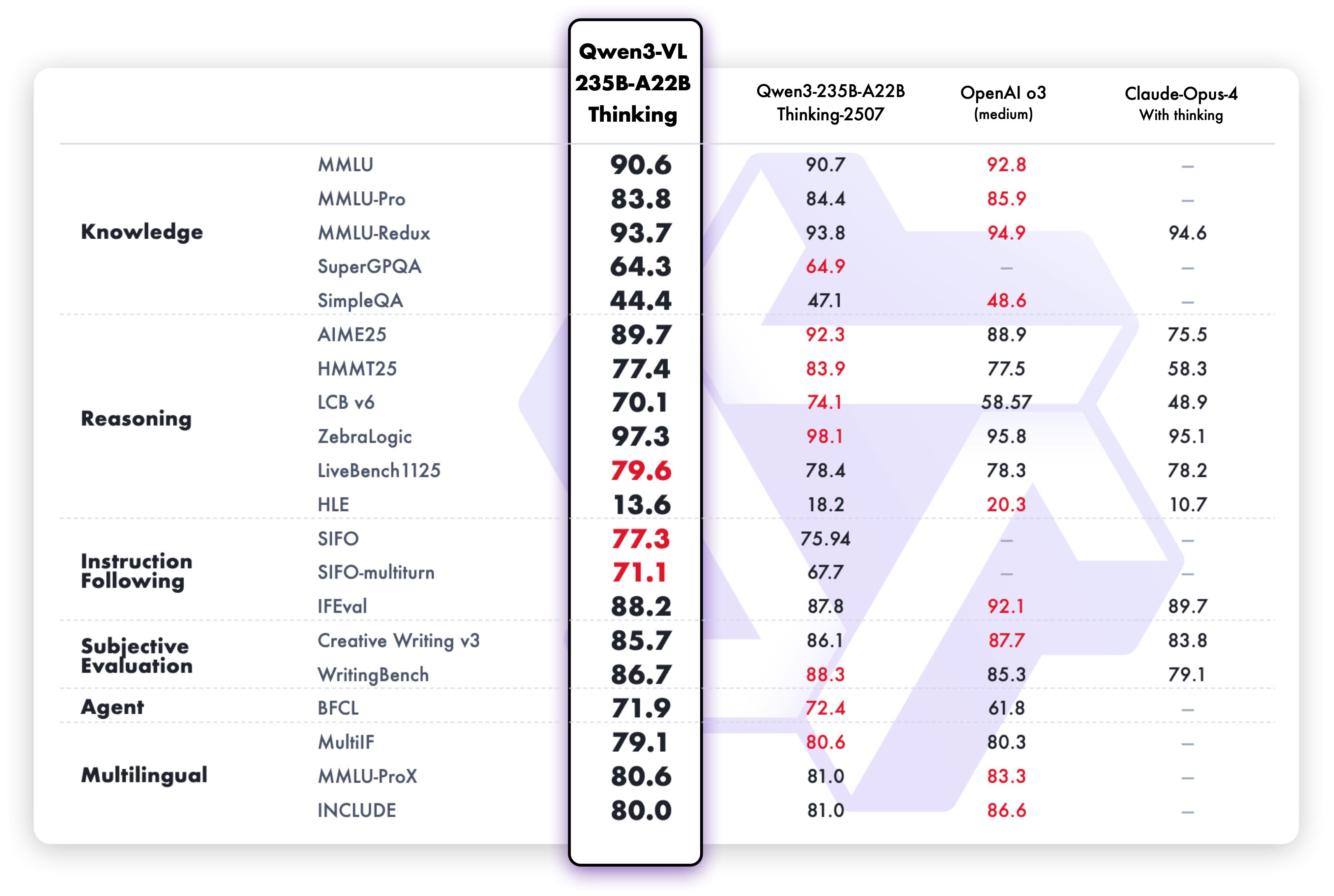
该图表呈现了Qwen3-VL在各项纯文本任务上的表现,包括语言理解、常识推理和数学问题解决等。数据显示模型在保持多模态能力的同时,文本处理能力达到专业语言模型水平,体现了高效的模型设计。
行业应用与案例分析
医疗健康领域
Qwen3-VL在医学影像分析、病历理解和多模态诊断方面展现巨大潜力。类似领先云平台精准医疗应用场景中,多模态大模型已使癌症早期诊断准确率提升37%,而Qwen3-VL的空间感知和推理能力有望进一步提高复杂病例的诊断精度。
金融服务
在金融风控领域,模型可处理表格、图像和文本构成的多模态票据,实现自动审核与风险识别。多家金融机构风控系统等项目已验证多模态技术可将信贷欺诈识别效率提高28倍,Qwen3-VL的OCR增强和跨模态推理能力将进一步强化这一场景应用。
工业制造
通过整合设备图像、传感器数据和技术文档,Qwen3-VL能够实现预测性维护、异常检测和操作指导。智能制造案例显示,类似技术可使设备停机率降低83%,而Qwen3-VL的3D空间理解能力将为数字孪生和智能制造提供更强支持。
零售电商
图文搜索、虚拟试衣和智能导购等场景将受益于Qwen3-VL的视觉识别和空间感知能力。多模态推荐系统可显著提升用户体验和转化率,预计可为电商平台带来15-20%的销售额增长。
行业影响与趋势
Qwen3-VL的发布反映了多模态大模型发展的三大趋势:
-
技术融合化:视觉、语言、音频等模态技术边界逐渐模糊,统一模型架构成为主流,降低开发复杂度并提升协同效率。
-
应用垂直化:通用模型通过领域微调适配特定行业需求,在医疗、工业等专业领域的深度应用成为差异化竞争焦点。
-
部署轻量化:尽管Qwen3-VL-235B参数规模庞大,但系列中同时提供边缘端到云端的多种规格,满足不同场景算力需求,推动技术普惠。
随着多模态技术的成熟,企业数字化转型正进入"感知-理解-决策"全链路智能化阶段。Qwen3-VL展示的技术能力表明,AI已从单一任务处理进化为综合信息处理系统,为各行业带来效率提升和模式创新。
快速开始
Qwen3-VL已集成到Hugging Face Transformers库,可通过以下代码快速体验:
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking",
dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
总结
Qwen3-VL通过全面的技术升级,将视觉语言模型的能力推向新高度,其空间感知、超长上下文理解和多模态推理等核心功能,为各行业应用提供了强大技术支撑。随着模型的普及和优化,我们有望看到更多创新应用场景涌现,推动AI技术从工具向伙伴角色转变。
对于企业而言,现在是布局多模态技术应用的关键时期。建议从数据准备、场景挖掘和人才培养三方面着手,制定符合自身业务需求的AI战略,抓住技术变革带来的发展机遇。
多模态大模型正处于技术爆发期,Qwen3-VL的发布不仅是一次产品升级,更标志着人工智能进入感知世界、理解复杂信息的新阶段,为未来通用人工智能奠定了基础。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







