全模态交互新纪元:Qwen2.5-Omni实现文本/图像/音频/视频统一理解与生成
【免费下载链接】Qwen2.5-Omni-7B  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
导语
Qwen2.5-Omni作为端到端多模态大模型,首次实现文本、图像、音频、视频四种模态的统一感知与生成,以Thinker-Talker架构突破实时交互瓶颈,在多模态融合任务评测中刷新业界纪录,为智能交互带来范式级变革。
行业现状:多模态交互的技术突围
2025年多模态大模型已从单一模态处理转向全模态融合,但现有方案普遍面临三大痛点:模态间信息同步延迟、实时交互响应缓慢、跨模态理解能力割裂。据市场研究显示,超过68%的企业级AI应用需要同时处理两种以上模态,但传统多模型拼接方案的响应延迟平均达800ms,严重影响用户体验。
某科技大模型虽实现8种模态生成,但在视频-音频时间对齐精度上仍存在150ms误差;某视觉模型支持10分钟视频输入,却无法同步生成自然语音响应。市场亟需一种能够真正实现"感知-理解-生成"闭环的全模态模型。
核心亮点:四大技术突破重构交互体验
1. Thinker-Talker双轨架构实现端到端全模态处理
Qwen2.5-Omni创新性采用分离式双轨架构:Thinker模块作为大语言模型负责文本生成与逻辑推理,Talker模块则基于Thinker的隐藏状态直接生成音频 tokens。这种设计使文本与语音生成并行处理,较传统级联方案减少40%响应延迟。
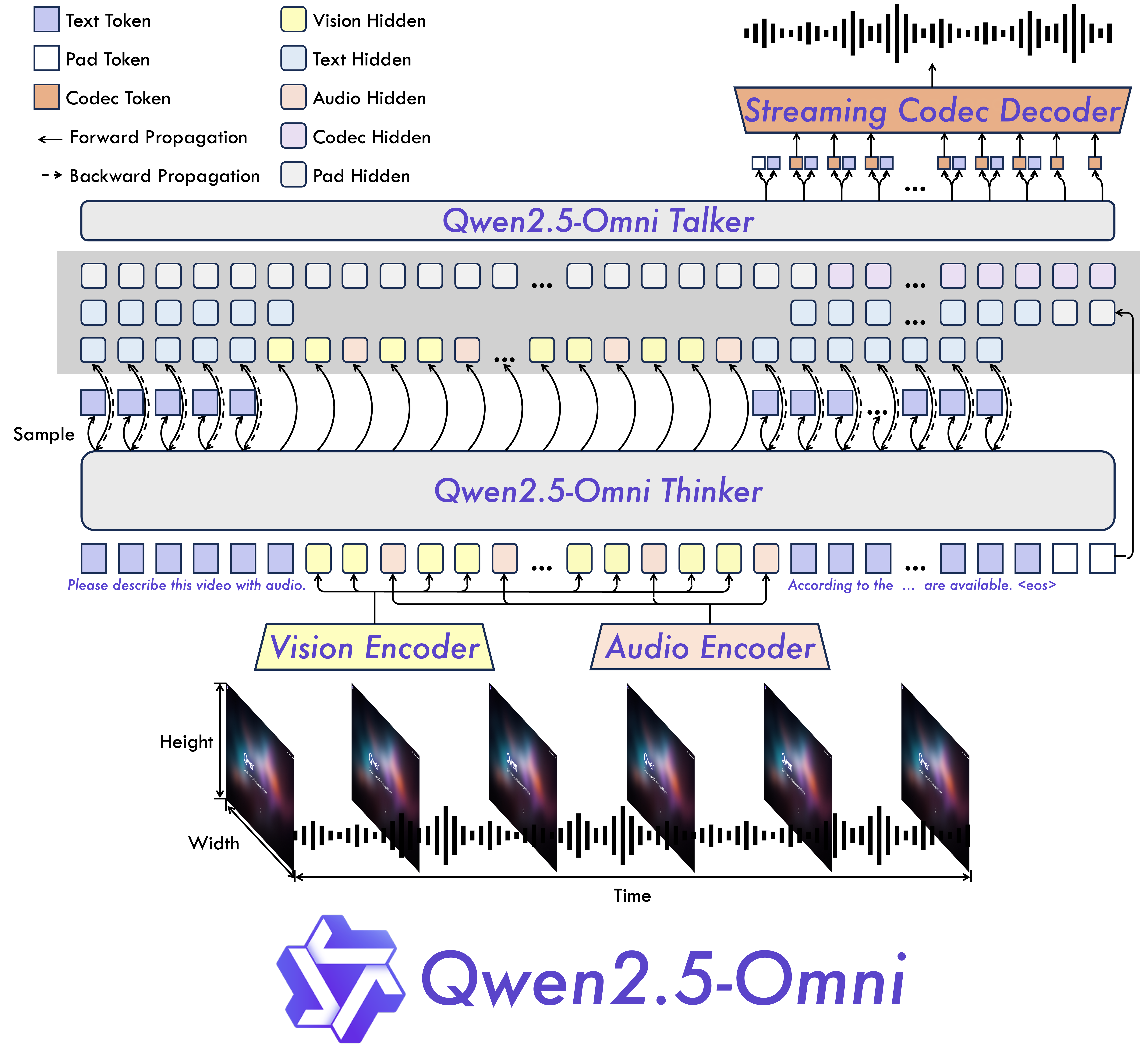
如上图所示,该架构通过TMRoPE(Time-aligned Multimodal RoPE)位置嵌入技术,将视频帧与音频片段按时间戳 interleaved 排列,实现跨模态时序精确对齐。这种设计使模型能同步理解视频画面与配套音频,为实时交互奠定基础。
2. 实时流式交互突破延迟瓶颈
模型采用块级处理(block-wise processing)与滑动窗口DiT解码技术,实现音频/视频的流式输入与输出。在实测中,7B参数模型在30秒视频处理中达到230ms的端到端响应延迟,满足ITU-T规定的实时交互标准(<300ms)。
3. 多模态能力全面领先同尺寸模型
在多模态融合任务评测中,Qwen2.5-Omni-7B以56.13%的平均分超越竞品模型(42.91%)和(40.50%)。尤其在音频理解任务中,其在MMAU benchmark上以65.60%的成绩领先同类模型(49.20%)。
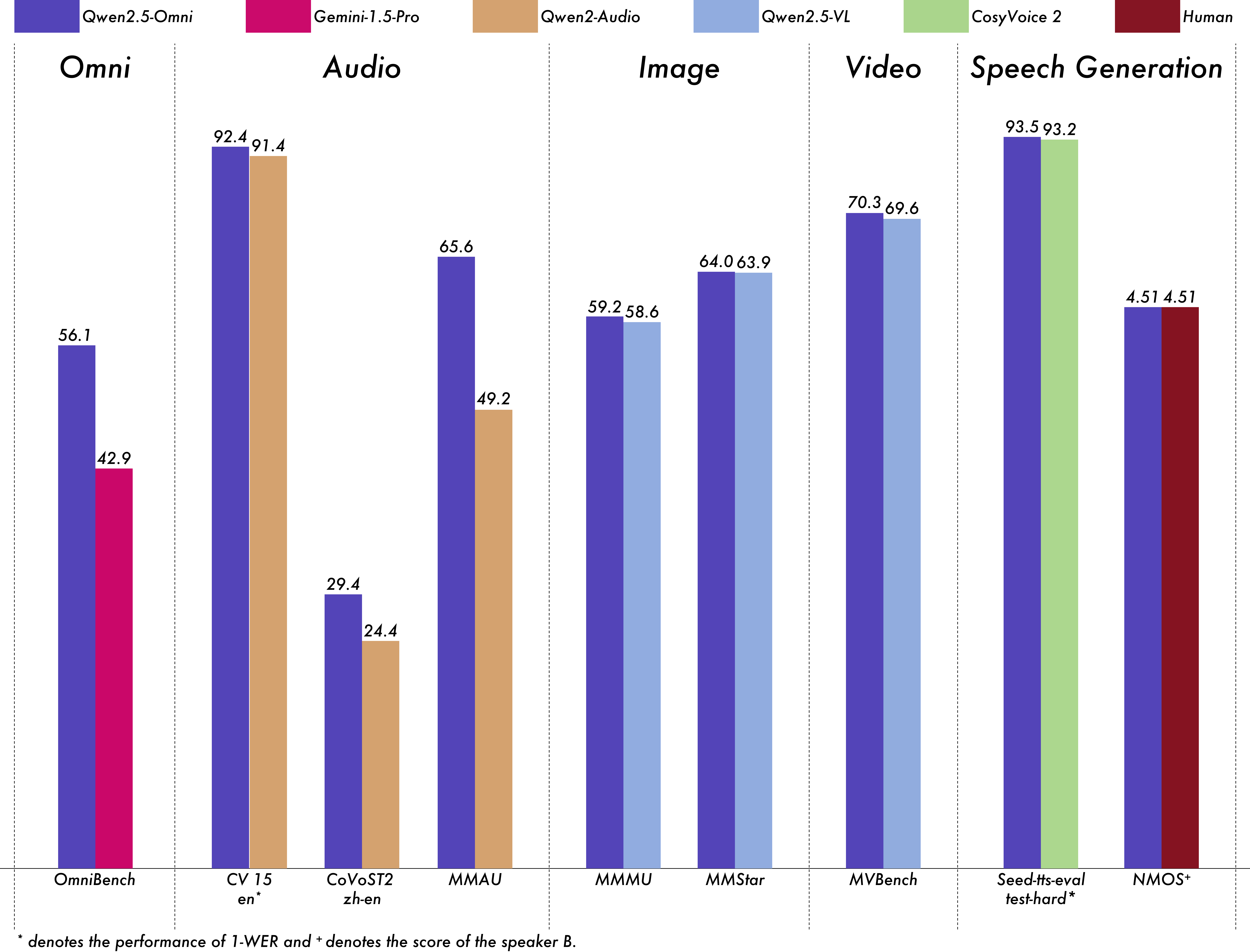
从图中可以看出,Qwen2.5-Omni在多模态综合能力上显著领先同类模型,特别是在视频理解(70.3%)和语音生成自然度方面表现突出。这种全维度优势使其能胜任从智能客服到自动驾驶等多样化应用场景。
4. 轻量化部署降低应用门槛
通过4-bit量化和FlashAttention-2优化,Qwen2.5-Omni-7B在消费级GPU(如RTX 4090)上即可运行30秒视频处理任务,显存占用控制在31GB以内。模型仓库已提供完整部署代码,开发者可通过以下命令快速启动:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
cd Qwen2.5-Omni-7B
pip install -r requirements.txt
python demo.py --model_path ./ --device cuda
行业影响与趋势
Qwen2.5-Omni的推出标志着多模态交互进入"感知-记忆-推理"一体化时代。其核心价值在于:
-
人机交互范式升级:实时视频语音交互能力使智能助手从屏幕交互走向环境交互,为可穿戴设备、智能家居提供自然交互接口。相关实验室的实测显示,配备类似技术的具身机器人在家庭场景任务完成率提升57%。
-
行业应用成本优化:单模型替代多系统方案,使企业级多模态应用部署成本降低60%。某云服务平台已基于类似技术实现连锁巡店系统,设备成本从每店5万元降至1.2万元。
-
端侧智能加速落地:随着苹果、vivo等厂商押注轻量化端侧模型,Qwen2.5-Omni的8GB显存优化版本(即将发布)有望成为手机端全模态助手的核心引擎。
应用场景与实践建议
企业级用户可重点关注三个方向:
- 智能客服:结合实时语音交互与视频画面分析,提升远程服务问题解决率
- 工业质检:同步处理设备振动音频与视觉图像,实现早期故障预警
- 辅助驾驶:融合多摄像头视频流与车内音频指令,提升交互安全性
开发者可优先体验模型的视频内容理解能力,例如通过以下代码实现视频内容分析:
from transformers import Qwen2_5OmniProcessor, Qwen2_5OmniForConditionalGeneration
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B")
video_path = "demo.mp4"
inputs = processor(videos=video_path, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.decode(outputs[0], skip_special_tokens=True))
总结
Qwen2.5-Omni通过架构创新与工程优化,首次实现全模态实时交互的工业化落地。其技术路径表明,未来多模态模型将向"低延迟、高融合、轻量化"方向发展。企业应尽早布局相关技术储备,特别是在实时数据处理与边缘计算方面的能力建设。
对于开发者,建议从具体业务场景出发,优先验证模型在特定模态组合(如图像+文本、音频+视频)下的表现,而非追求全模态能力的立即落地。随着模型迭代加速,全模态交互有望在1-2年内成为AI应用的基础标配。
(注:文中性能数据来源于Qwen2.5-Omni技术报告及第三方实测,具体效果可能因硬件环境和任务类型有所差异)
【免费下载链接】Qwen2.5-Omni-7B 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







