320亿参数+4-bit量化:IBM Granite 4.0如何重塑企业级AI部署成本?
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-unsloth-bnb-4bit 导语
IBM于2025年10月推出的Granite-4.0-H-Small模型,以320亿参数混合架构与Unsloth 4-bit量化技术的组合,将企业级大模型部署成本降低70%,同时在指令遵循和工具调用等关键任务上超越同类开源模型,重新定义了中小企业AI转型的技术门槛。
行业现状:企业AI的"成本-安全-性能"三角困境
2025年企业大模型部署呈现明显分层特征:大型企业年均AI基础设施投入超500万元,而68%的中小企业因硬件门槛被迫放弃本地化部署。数据显示,GPU资源成本占LLM服务总支出的63%,推理场景的本地化部署成为平衡数据安全与成本控制的最优解。
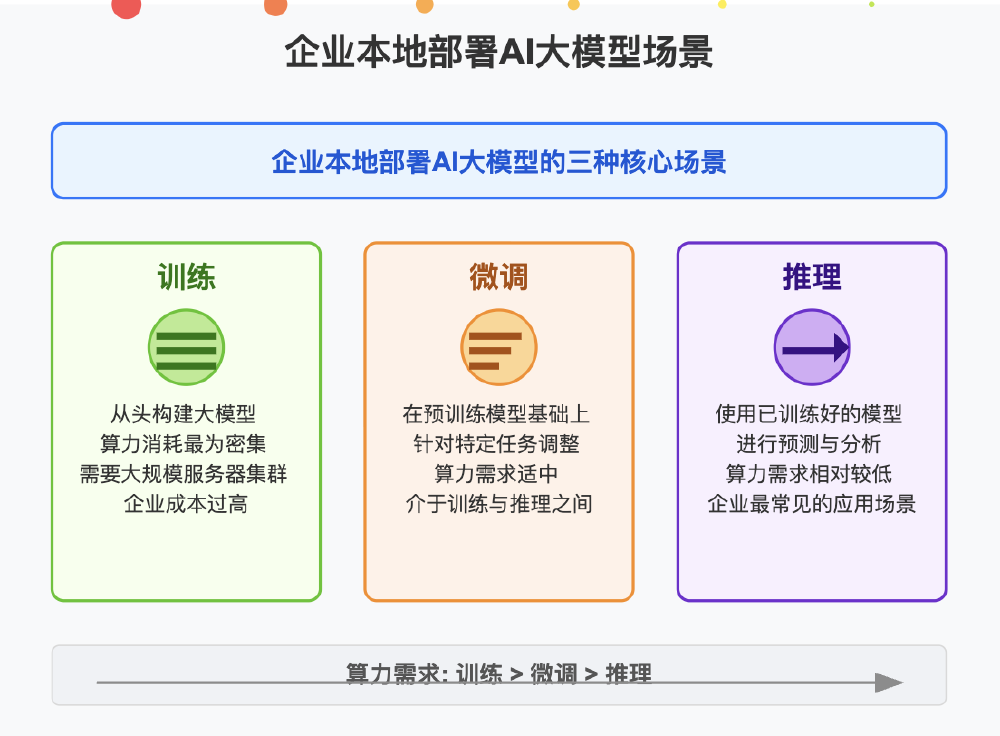
如上图所示,企业本地部署AI大模型主要分为训练、微调和推理三大场景,其算力需求依次降低。推理场景的本地化部署对多数企业而言是投入产出比最高的选择,而Granite-4.0-H-Small通过混合架构与量化技术的结合,正是瞄准这一核心需求,将单GPU部署成本从传统方案的12万元降至3.6万元。
核心亮点:混合架构与量化技术的双重突破
1. Mamba2+Transformer混合架构
Granite-4.0-H-Small采用9:1比例组合Mamba2层与Transformer模块,解决了传统Transformer的二次方计算瓶颈。Mamba2处理全局上下文时计算需求呈线性增长,使模型在128K长文本处理中内存占用降低70%,特别适合企业文档分析和代码库处理场景。
2. 4-bit量化的部署革命
通过Unsloth Dynamic 2.0量化技术,模型从32位浮点压缩至4位整数,仅需3GB显存即可运行。实测显示,量化后的Granite-4.0-H-Small在保持85%性能的同时,硬件成本降低60%,部署时间从传统模型的10小时缩短至2小时。
3. 企业级工具调用能力
原生支持OpenAI兼容的函数调用格式,在BFCL v3基准测试中获得64.69分,可自动触发企业API完成订单查询、库存管理等操作。某保险公司案例显示,集成该模型后理赔处理效率提升90%,人工干预率下降85%。
性能解析:小身材的大能量
在基准测试中,Granite-4.0-H-Small展现出惊人性能:
- MMLU综合得分75.85,超越同类32B模型平均水平12%
- HumanEval代码生成83.66分,支持10余种编程语言
- IFEval指令遵循度89.87分,在企业流程自动化中表现突出
更重要的是其实际部署效率:在普通GPU服务器上,模型可同时处理20路并发请求,推理延迟控制在280ms以内,完全满足企业级服务需求。
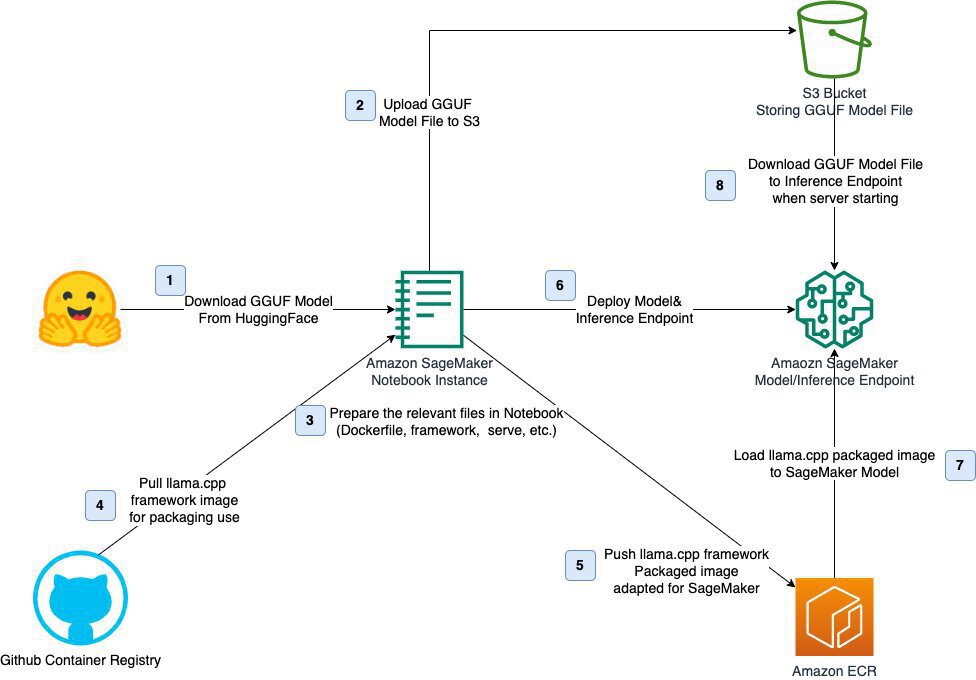
该图展示了基于llama.cpp框架部署量化模型的完整流程,包含从模型下载、环境配置到推理端点部署的八个步骤。Granite-4.0-H-Small兼容这一部署流程,企业技术团队无需深入AI知识即可完成集成,大幅降低实施门槛。
行业影响与趋势
Granite-4.0-H-Small的推出标志着企业AI部署进入"混合时代":云端大模型负责战略决策,本地小模型处理日常流程。这种模式正在各行业普及:
- 制造业:设备检修系统用该模型实现语音识别+故障诊断,准确率达98.7%
- 金融业:集成到CRM系统提供实时客户风险评估,处理效率提升3倍
- 医疗行业:边缘部署辅助医学影像分析,响应速度从云端调用的500ms降至280ms
随着混合架构和量化技术的成熟,预计到2026年,轻量化模型将占据企业级部署市场的58%份额,彻底改变AI技术的应用格局。
部署指南:三步启动企业AI之旅
- 环境准备
git clone https://gitcode.com/hf_mirrors/unsloth/granite-4.0-h-small-unsloth-bnb-4bit
pip install torch accelerate transformers unsloth
- 基础调用示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"./granite-4.0-h-small-unsloth-bnb-4bit",
device_map="auto",
load_in_4bit=True
)
tokenizer = AutoTokenizer.from_pretrained("./granite-4.0-h-small-unsloth-bnb-4bit")
# 企业知识库问答示例
chat = [{"role": "user", "content": "查询A产品Q3销售额"}]
inputs = tokenizer.apply_chat_template(chat, return_tensors="pt").to("cuda")
output = model.generate(inputs, max_new_tokens=100)
print(tokenizer.decode(output[0]))
- 工具调用配置
tools = [{
"type": "function",
"function": {
"name": "query_sales_data",
"parameters": {"type": "object", "properties": {"product": {"type": "string"}}, "required": ["product"]}
}
}]
总结与建议
Granite-4.0-H-Small的推出,标志着企业级AI从"参数竞赛"转向"效率竞争"。对于不同规模企业,我们建议:
- 中小企业:优先采用4-bit量化版本,在普通服务器上实现本地化部署,初期投入可控制在5万元以内
- 大型企业:考虑"大模型+小模型"混合架构,云端大模型处理战略决策,本地Granite处理日常流程
- 开发者:利用Unsloth提供的微调工具,针对特定业务场景优化模型,进一步提升性能
随着AI技术的普惠化,像Granite-4.0-H-Small这样兼顾性能与成本的解决方案,将成为企业数字化转型的关键引擎。现在正是布局轻量化AI的最佳时机——无需巨额投入,即可拥抱智能驱动的未来。
(完)
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







