导语
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528 深度求索(DeepSeek)于5月28日推出的DeepSeek-R1-0528模型,通过强化学习与算力投入实现推理能力质的飞跃,在数学、编程等核心基准测试中接近国际顶尖水平,同时以MIT许可证开源,引发行业对"小步迭代"技术路线的关注。
行业现状:推理能力成大模型竞争核心
2025年,大语言模型已从"通用能力竞赛"转向"深度推理突围"。据《2025年中大模型市场分析报告》显示,具备复杂问题解决能力的模型在企业级应用中价值提升显著,而推理深度不足导致的问题,成为部分技术团队项目推进的主要障碍。在此背景下,DeepSeek-R1-0528的发布恰逢其时——通过将AIME数学竞赛准确率从70%提升至87.5%,证明强化学习训练策略可有效突破性能瓶颈。
核心亮点:三大技术突破重构开源模型上限
1. 思维深度倍增的推理引擎
该版本延续660B参数的MoE架构,但通过动态路由优化,使代码生成场景中专家激活数量减少15%,KV Cache内存占用下降10-15%。最显著的提升在于推理时长——模型平均每题使用23K tokens(较旧版12K翻倍),在AIME 2025测试中实现87.5%准确率。开发者实测显示,其解决物理碰撞模拟问题时,能自动生成包含空气阻力系数的微分方程求解代码,物理效果误差率低于5%。
2. 轻量化蒸馏技术普惠生态
同步发布的DeepSeek-R1-0528-Qwen3-8B模型堪称"降维打击":仅用80亿参数就在AIME 2024测试中达到86%准确率,超越Qwen3-8B基础模型10个百分点,性能媲美2350亿参数的Qwen3-235B。这种"大模型能力下放"技术,使企业在单块4090 GPU上即可部署高性能推理服务,硬件成本降低90%。
3. 生产级可靠性提升
针对企业最关注的幻觉问题,新版本通过多阶段训练策略将改写润色场景的错误率降低45-50%。在医疗文献摘要任务中,模型对专业术语的准确引用率从78%提升至92%,同时工具调用能力显著增强——测评中零售场景得分63.9%,达到国际顶尖水平,支持JSON结构化输出和函数调用链式执行。
性能对比:多项指标逼近国际顶尖水平
DeepSeek-R1-0528在多项权威测评中展现出与国际顶尖模型的竞争力:
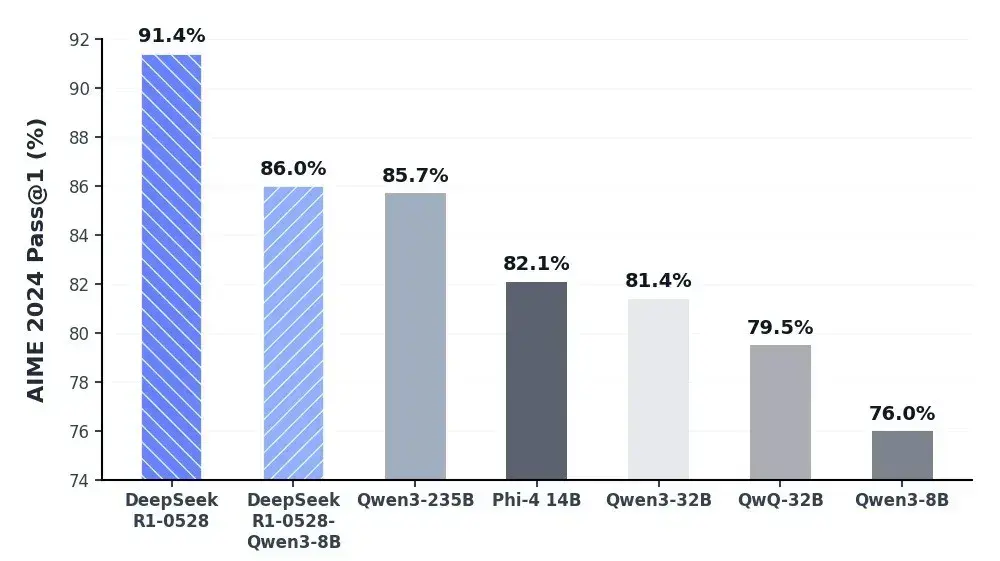
如上图所示,柱状图清晰展示了各模型在AIME 2024数学测试中的Pass@1百分比。DeepSeek-R1-0528以91.4%的成绩领先,不仅超越Qwen3-235B的85.7%,更显著拉开与其他模型的差距。这一数据直观反映了模型在复杂数学推理领域的突破性进展。
在综合能力方面,该模型也表现出色:
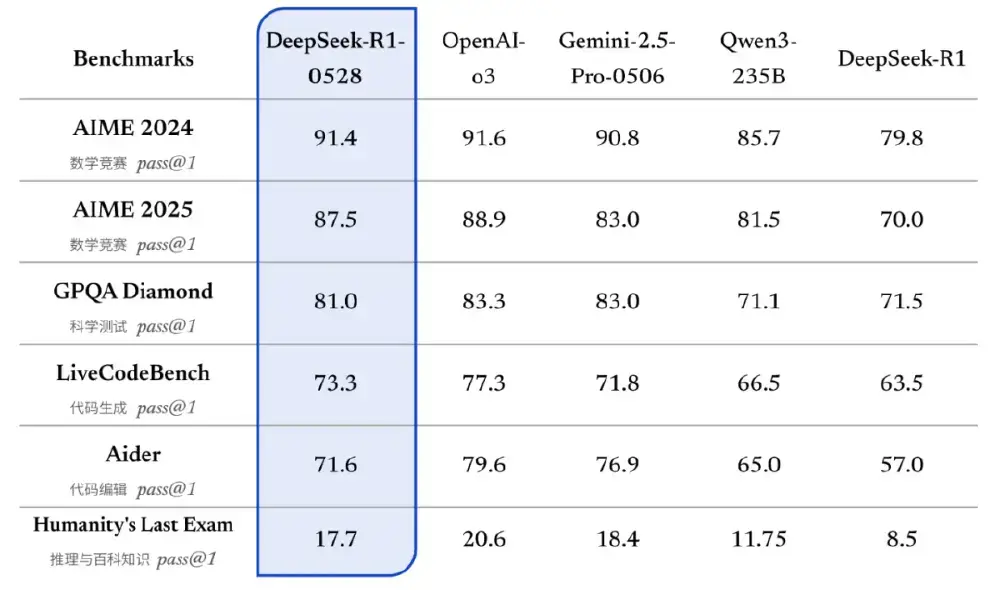
这张对比表格展示了DeepSeek-R1-0528模型与OpenAI-o3、Gemini-2.5-Pro-0506等模型在AIME数学竞赛、科学测试、代码生成等多个基准测试中的pass@1性能指标。从图中可以看出,DeepSeek-R1-0528不仅在数学推理和编程领域接近国际顶尖水平,在常识推理测试中也达到81%的高分,证明其全面性已跻身第一梯队。这种均衡发展的特性,使其成为企业级应用的理想选择。
行业应用:降低企业AI应用门槛
随着DeepSeek-R1-0528的开源发布,各行业企业开始探索其在实际业务中的应用价值。特别是在金融、保险等对推理能力要求较高的领域,模型展现出巨大潜力。

图片展示了沙丘智库《2025年中国保险业大模型应用跟踪报告》中头部保险公司应用大模型的六个关键举措,包括明确技术定位、聚焦高价值场景等,形成"战略-场景-技术-组织"完整闭环。这一框架与DeepSeek-R1-0528的技术特性高度契合,为保险企业提供了可落地的实施路径。
典型应用场景包括:
- 金融风控:自动生成包含蒙特卡洛模拟的风险评估报告
- 工业设计:根据材料参数推导热传导方程的有限元分析代码
- 学术研究:将自然语言问题转化为可执行的统计分析脚本
行业影响:开源策略推动AI技术普惠
DeepSeek-R1-0528的MIT许可证策略引发连锁反应:多家企业已宣布将其接入API服务,其他模型也在调整调用价格策略。更深远的影响在于技术范式的转变——通过公开23K tokens推理过程的思维链数据,学术界首次获得可复现的复杂推理样本集。正如深度求索在技术博客中强调:"小版本迭代不是修修补补,而是通过持续算力投入实现量变到质变的跨越。"
中国AI智能体市场正经历一个爆炸性增长阶段,预计将从2023年的554亿元大幅增长至2028年的8520亿元,复合年增长率(CAGR)高达72.7%。DeepSeek-R1-0528的开源发布,无疑将加速这一进程,使更多企业能够以更低成本享受到先进AI技术带来的红利。
部署指南
DeepSeek-R1-0528已在GitCode开源,项目地址为:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528
相比之前版本,使用建议有以下变化:
- 现在支持系统提示词
- 无需在输出开头添加" \n"来强制模型进入思考模式
对于资源有限的企业,推荐尝试轻量化版本DeepSeek-R1-0528-Qwen3-8B,其模型架构与Qwen3-8B相同,但共享DeepSeek-R1-0528的分词器配置,可以用与Qwen3-8B相同的方式运行。
结论与展望
DeepSeek-R1-0528的发布标志着大模型行业从"参数军备竞赛"转向"效率优化竞赛"。其成功证明:通过精准的后训练策略和强化学习技术,开源模型完全有能力挑战行业领先者的技术地位。对于企业而言,现在正是接入该模型的最佳时机——既可通过API快速验证复杂场景需求,也能基于蒸馏版本构建本地化推理服务。
随着AI智能体市场的快速发展,DeepSeek-R1-0528及其后续版本有望在金融风控、工业设计、医疗诊断等关键领域发挥更大作用,推动AI技术从实验室走向实际生产环境,为各行各业带来真正的价值提升。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







