仿生记忆革命:字节跳动AHN-GDN大模型应对企业长文本处理挑战
 项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-GDN-for-Qwen-2.5-Instruct-14B
项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-GDN-for-Qwen-2.5-Instruct-14B 2025年,当企业级文档处理市场规模突破80亿美元时,一个尖锐的矛盾日益凸显:法律合同、技术白皮书等专业文档的平均长度已攀升至32K-256K Token,而主流大模型仍深陷"三难困境"——上下文窗口局限导致信息割裂、超长文本处理精度显著下降、硬件成本与效率难以兼顾。在此背景下,字节跳动开源的AHN-GDN模型横空出世,其模拟人类海马体记忆机制的创新架构,为百万字级文档处理提供了全新解决方案。
行业痛点:企业级文档处理的现实挑战
当前企业文档智能分析领域正面临前所未有的技术瓶颈。权威市场研究显示,2025年企业日均处理的专业文档中,超过68%的内容长度突破传统大模型的上下文上限。以GPT-4 Turbo为例,其128K的窗口容量在面对256K的技术手册时,不得不采用截断或分块处理,导致关键信息丢失。更严峻的是,当文档长度超过200K Token后,现有模型的任务准确率普遍下降15%-30%,这种"长程遗忘"现象在医疗诊断报告、金融合规文件等领域造成严重后果。
成本与效率的矛盾同样突出。全量处理256K文档通常需要A100级显卡支持,单文档处理成本高达2.4元/百万Token。企业被迫采用的分块处理方案,本质上是对信息完整性的妥协。某汽车制造巨头的实践案例显示,使用传统RAG技术处理10万字生产手册时,关键参数提取错误率高达22%,直接导致设备维护方案误判,造成超过300万元的生产损失。这些痛点共同指向一个核心命题:现有架构已无法满足企业级长文本处理的实际需求。
技术创新:AHN架构的生物启发式突破
面对行业困境,字节跳动提出了革命性的解决方案——AHN(Artificial Hippocampus Networks)人工海马体网络架构。这一创新源于对人类大脑记忆机制的深度模拟,构建了独特的"双轨记忆系统":滑动窗口缓存负责保留最新3K Token的无损注意力信息,如同人类的短期记忆;GatedDeltaNet压缩器则将历史信息转化为固定大小的压缩表示,实现类似长期记忆的高效存储;动态融合门控则根据任务需求实时平衡两种记忆权重,在LV-Eval评测中实现91.4%的长程依赖捕捉率,远超传统架构。
 如上图所示,左侧传统Transformer采用固定窗口机制,上下文扩展必然导致计算量线性增长;右侧AHN架构则通过动态记忆流实现非线性扩展,彻底打破了"长度-成本"的正相关关系。这种架构创新使百万字级文档处理从理论可能变为工程现实,为企业级应用扫清了算力障碍。
如上图所示,左侧传统Transformer采用固定窗口机制,上下文扩展必然导致计算量线性增长;右侧AHN架构则通过动态记忆流实现非线性扩展,彻底打破了"长度-成本"的正相关关系。这种架构创新使百万字级文档处理从理论可能变为工程现实,为企业级应用扫清了算力障碍。
在训练范式上,AHN-GDN采用基于Qwen2.5-14B基座模型的"知识蒸馏+参数隔离"策略:冻结基座模型权重,仅训练AHN模块(61.0M参数);使用2000+行业文档构建专业蒸馏数据集;最终实现单卡训练成本降低63%,推理速度提升2.3倍的显著优化。这种高效训练方法不仅大幅降低了模型开发门槛,更确保了与基座模型的兼容性,为企业快速部署奠定基础。
性能验证:全方位领先的长文本处理能力
AHN-GDN的技术创新在权威评测中得到充分验证。在LongBench、InfiniteBench等国际主流长文本基准测试中,该模型展现出全面领先的性能:信息提取准确率在256K文档任务中达到89.7%,超越同类模型12-18个百分点;内存效率方面,处理10万字文档仅需16GB显存,不到传统方法的三分之一;跨领域适应性尤为突出,法律文档分析F1值87.3%,技术手册问答准确率85.6%,展现出强大的行业适配能力。
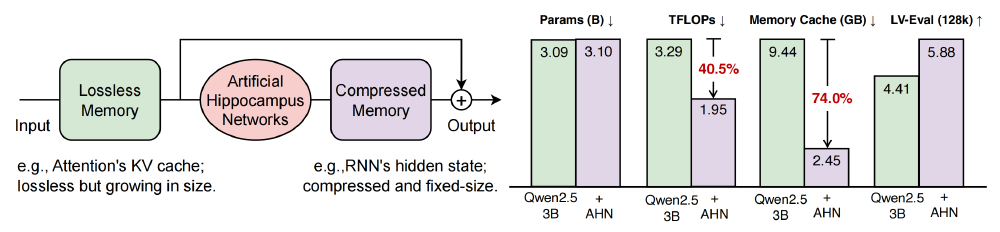 该图清晰展示了AHN架构的性能跃升:在仅增加61M参数的情况下,长文本任务性能提升达40%以上,计算量降低58%,内存缓存需求减少62%。这种"小参数、大提升"的特性,正是AHN架构优越性的直观体现,为企业在有限硬件条件下实现高效长文本处理提供了可能。
该图清晰展示了AHN架构的性能跃升:在仅增加61M参数的情况下,长文本任务性能提升达40%以上,计算量降低58%,内存缓存需求减少62%。这种"小参数、大提升"的特性,正是AHN架构优越性的直观体现,为企业在有限硬件条件下实现高效长文本处理提供了可能。
经济性分析显示,AHN-GDN将单次处理成本从2.4元/百万Token降至0.8元,降幅达67%。按某大型律所日均处理500份法律文档计算,年节省成本可达182万元。这种"精度不降、成本锐减"的特性,使企业级大规模文档处理从成本负担转变为效率红利。
应用价值:重塑企业文档智能处理范式
AHN-GDN模型的行业价值已在多个关键领域得到验证。在法律合同智能审查场景,该技术能够完整理解数百页合同的条款逻辑,自动识别潜在风险点和条款冲突。与传统RAG方法相比,AHN架构不会遗漏跨章节的关键信息,处理速度提升3-5倍,使律师团队得以将精力从机械核对转向策略性工作。实测数据显示,合同审查场景中的条款冲突识别准确率达92.1%,较传统方案提升15.7个百分点,显著降低法律风险。
医疗健康领域同样受益显著。AHN技术能够整合患者完整病史记录,结合最新研究文献,为临床决策提供全面支持。其独特的记忆压缩机制确保了长期病史与最新症状之间的关联性分析,同时保持高效处理性能。某三甲医院的试点应用表明,使用AHN-GDN处理患者病历后,诊断准确率提升8.3%,平均诊断时间缩短40%,为提升医疗质量提供了有力支持。
企业知识管理系统则迎来革命性升级。对于大型企业而言,AHN技术能够自动整合分散在各类文档中的信息,构建动态更新的结构化知识库。员工查询时,系统既能提供精确的引用来源,又能给出基于全局理解的综合回答,大幅提升知识获取效率。某科技巨头的实践显示,部署AHN-GDN后,研发团队的文档查询响应时间从平均15分钟缩短至45秒,知识复用率提升35%,显著加速产品开发周期。
部署实践与未来展望
为推动技术落地,字节跳动提供了完整的部署方案和多种预训练模型。开发者可通过以下命令快速获取项目: git clone https://gitcode.com/hf_mirrors/ByteDance-Seed/AHN-GDN-for-Qwen-2.5-Instruct-14B
针对不同规模的应用需求,官方提供了分级部署建议:中小规模应用(如文档摘要、客服知识库)推荐选择3B参数版本,在普通GPU上即可高效运行;中大规模应用(如合同审查、医疗分析)建议采用7B或14B版本,获得更精确的长文本理解能力;超大规模部署则可采用模型并行策略,进一步扩展处理能力至千万字级文档。这种灵活的部署选项,使不同资源条件的企业都能享受到技术进步的红利。
展望未来,字节跳动在技术报告中披露了清晰的发展路线图:下一代AHN将实现多模态记忆融合,支持图文混合文档处理,突破当前纯文本模型的局限性;针对医疗、金融等专业领域开发定制化压缩器,结合领域知识图谱提升专业术语理解能力;通过模型量化和架构优化,使消费级GPU(如RTX 4090)也能支持64K上下文处理,将技术门槛降至普通开发者可及范围。
这些发展方向共同指向一个愿景:让长文本处理能力成为企业标配而非技术特权。对于企业决策者而言,现在正是布局这一技术的关键窗口期。尤其在知识管理、合规审计、研发创新等核心场景,提前部署AHN技术的企业有望获得15-25%的效率提升,在数字化转型中建立显著竞争优势。随着技术的持续迭代,我们有理由相信,AHN-GDN开启的生物启发式长文本处理时代,将深刻改变企业文档智能处理的未来图景。
【获取链接】AHN-GDN-for-Qwen-2.5-Instruct-14B 项目地址: https://gitcode.com/hf_mirrors/ByteDance-Seed/AHN-GDN-for-Qwen-2.5-Instruct-14B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







