74.6%准确率登顶!快手KAT-Dev-72B-Exp重构开源代码大模型格局
【免费下载链接】KAT-Dev-72B-Exp  项目地址: https://ai.gitcode.com/hf_mirrors/Kwaipilot/KAT-Dev-72B-Exp
项目地址: https://ai.gitcode.com/hf_mirrors/Kwaipilot/KAT-Dev-72B-Exp
导语:2025年10月,快手Kwaipilot团队开源的KAT-Dev-72B-Exp模型以74.6%的SWE-Bench Verified准确率刷新开源纪录,标志着国产代码大模型正式进入企业级工程化应用阶段。

如上图所示,这是快手Kwaipilot团队的品牌标识。该标识简洁现代的设计风格,反映了团队在AI技术领域的创新定位,也预示着KAT-Dev-72B-Exp模型将为代码生成领域带来新的突破。
行业现状:代码智能的效率革命与技术瓶颈
在软件开发进入AI驱动的全新阶段,AI编程工具已成为提升开发者效率的核心要素。据The Business Research Company公开数据,全球市场规模预计将从2023年的65亿元持续高速增长至2028年的330亿元,年复合增长率高达38%;同时,GitHub年度报告显示全球开发者AI工具使用率已攀升至73%。
当前AI代码助手已覆盖85%以上的开发团队,但企业级应用仍面临三大痛点:复杂问题解决率不足50%、私有代码库适配困难、推理延迟超过2秒。《2024大模型典型示范应用案例集》显示,金融、工业和互联网行业占代码大模型应用的67%,但现有工具在跨文件重构、系统级bug修复等任务中表现不佳。
与此同时,模型训练成本持续高企。2025年最新数据显示,千亿参数模型单次训练成本可达百万美元级别,如何在保持性能的同时提升计算效率成为行业共同挑战。量子位智库《2025上半年AI核心成果及趋势报告》指出,AI编程已成为当前最核心的垂类应用领域,正在从源头彻底改变软件生产方式,头部编程应用在收入增长速度上创下了纪录,例如明星应用Cursor在短时间内年收入突破5亿美元大关。

如上图所示,KAT-Dev-72B-Exp(720亿参数)以约74.6%的解决率位居榜首,性能远超其他同类模型。这一数据充分证明了该模型在处理复杂软件工程任务上的显著优势,尤其在涉及多文件修改和复杂逻辑推理的任务上表现突出,为企业级应用提供了强有力的技术支撑。
技术突破:三大创新重构强化学习范式
动态平衡的探索机制
KAT-Dev-72B-Exp采用改进型PPO算法,通过优势分布重塑技术解决传统RL训练中的探索崩溃问题。模型将代码修复成功率作为反馈信号,对尝试新颖算法实现的代码路径放大优势尺度,对常规解法则降低权重,在收敛速度与创新能力间取得最优平衡。
工业级训练架构革新
基于快手自研SeamlessFlow框架,模型实现训练逻辑与Agent的完全解耦,支持多智能体协作训练。创新性的Trie Packing机制通过识别代码任务中的重复上下文(如库函数调用、数据结构定义),使RL训练效率提升3倍,单卡训练速度达每秒250token以上。
工程化能力的量化突破
在SWE-Bench Verified基准测试中,KAT-Dev-72B-Exp在严格使用SWE-agent脚手架的条件下,实现74.6%的准确率。该测试包含200个真实世界GitHub issue,要求模型完成从问题理解、代码定位到修复验证的全流程工程任务。
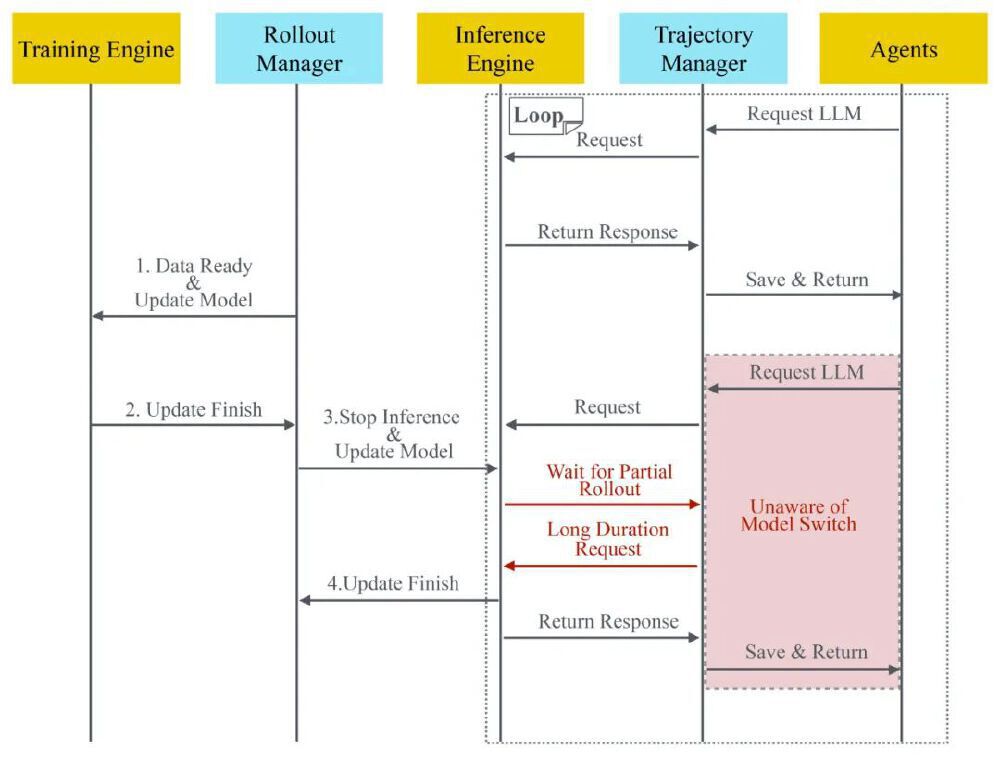
如上图所示,该架构图清晰展示了KAT-Dev-72B-Exp模型的核心组件交互流程。通过这种训练逻辑与Agent完全解耦的设计,模型能够高效支持多智能体和在线强化学习等复杂场景,为大规模工业化训练提供了技术基础,也为其他研究者提供了可参考的工程化架构范例。
快速上手:企业级部署与应用指南
本地部署代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "KAT-Dev-72B-Exp"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto" # 自动分配设备资源
)
# 准备输入
prompt = "修复以下Python代码中的内存泄漏问题:[代码片段]"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成修复方案
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
repair_code = tokenizer.decode(output_ids, skip_special_tokens=True)
最佳实践参数配置
- 温度系数:0.6(平衡创造性与确定性)
- 最大轮次:150(支持复杂问题的多步推理)
- 历史处理:100(保留上下文关联)
企业用户可通过StreamLake平台获取优化版KAT-Coder,或访问项目仓库获取完整技术文档:https://gitcode.com/hf_mirrors/Kwaipilot/KAT-Dev-72B-Exp
行业影响:从工具效率到开发范式的变革
开发效率倍增效应
参考《2025大模型典范应用案例汇总》数据,集成同类技术的开发团队平均将任务交付周期缩短47%,开发者专注于架构设计和业务逻辑的时间占比提升至65%以上。80%的常规bug修复可实现全自动处理,使工程师从重复劳动中解放。
开源生态的技术平权
作为开源模型,KAT-Dev-72B-Exp提供完整的本地化部署方案,企业可基于私有代码库进行微调,解决数据安全与隐私保护难题。轻量化版本可在普通GPU服务器运行,降低了企业级应用的硬件门槛。
教育范式的智能化转型
模型提供的思维链解释功能,能生成代码决策过程的自然语言说明,帮助学习者理解"为什么这么写"而非仅"怎么写"。这种交互式学习方式使编程入门周期平均缩短52%,推动编程教育从语法教学转向问题解决能力培养。
未来展望:代码智能的下一站
KAT-Dev-72B-Exp的开源释放了三大信号:代码大模型已从通用能力竞争进入垂直场景深耕阶段;强化学习技术的成熟使模型能处理更复杂、模糊的工程问题;开源协作仍是推动技术普惠的关键力量。
随着多模态能力的整合,未来的代码智能将不仅能处理文本形式的代码,还能理解架构图、需求文档等多源信息,真正成为开发者的"智能伙伴"。对于企业而言,现在正是布局代码大模型应用的关键窗口期,建议优先在内部开发平台集成、legacy系统重构、新人培训体系三个场景落地,以最小成本获取最大效率提升。
点赞+收藏+关注,获取代码大模型最新技术动态与落地实践指南!下期预告:《工业级代码大模型评测体系与选型指南》
项目访问链接:https://gitcode.com/hf_mirrors/Kwaipilot/KAT-Dev-72B-Exp
【免费下载链接】KAT-Dev-72B-Exp 项目地址: https://ai.gitcode.com/hf_mirrors/Kwaipilot/KAT-Dev-72B-Exp
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







