40%效率提升:verl异步离策略架构如何变革LLM训练?
 项目地址: https://gitcode.com/GitHub_Trending/ve/verl
项目地址: https://gitcode.com/GitHub_Trending/ve/verl 你是否正面临LLM训练中的GPU利用率难题?当模型等待长尾样本生成时,宝贵的计算资源正在闲置。本文将深入解析verl的新一代异步离策略架构,展示如何通过创新的并行化设计将训练效率提升40%,同时保持甚至提高模型性能。读完本文,你将掌握异步训练的核心原理、实施步骤以及资源配置的最佳实践。
传统同步训练的痛点与突破
在传统的强化学习训练流程中,verl实现的PPO、GRPO和DAPO等算法采用同步模式,每一步都需要最新模型生成训练样本,训练完成后才能更新模型。虽然这种方法符合离策略强化学习的算法流程并能稳定训练,但存在严重的效率问题。
模型更新必须等待生成阶段中最长输出完成,在长尾样本生成期间,GPU处于闲置状态,导致资源利用率显著下降。长尾样本问题越严重,整体训练效率越低。例如在DAPO 32B训练中,Rollout阶段约占总时间的70%,增加资源也无法缩短Rollout持续时间。
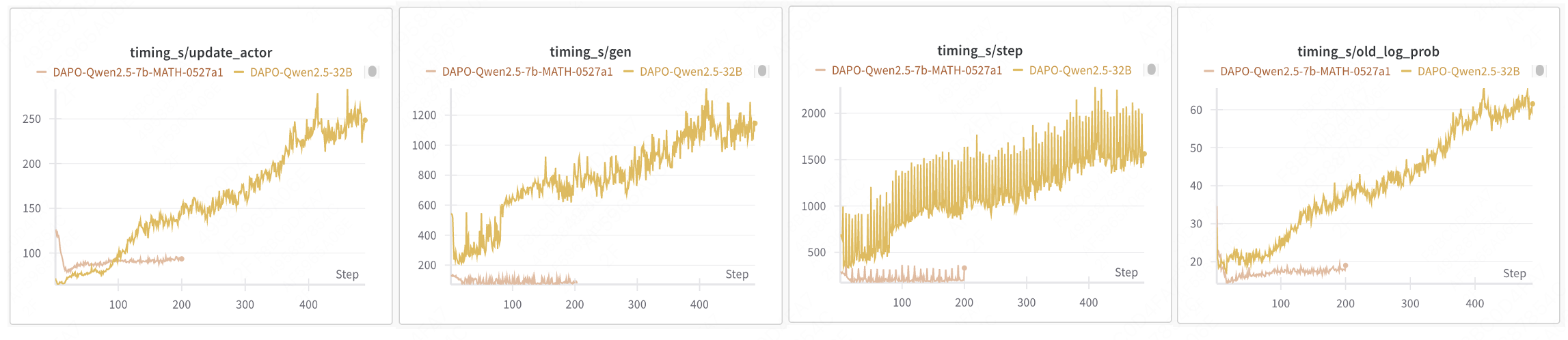
官方文档详细阐述了这一问题:docs/advance/one_step_off.md
异步离策略架构:核心创新与实现原理
为解决同步训练的效率瓶颈,verl团队开发了单步离策略异步训练器(One Step Off Async Trainer)。该架构通过并行化生成和训练过程,使用前一步生成的样本进行当前训练,同时合理划分资源,为生成分配专用资源,将剩余资源自动分配给训练。
核心创新点
- 并行生成与训练:当前批次训练时异步生成下一批次样本
- 资源隔离:与
hybrid_engine不同,明确为rollout分配资源,剩余资源自动分配给训练 - NCCL参数同步:采用NCCL通信原语实现生成与训练模块间的无缝参数传输

参考论文:AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
实现架构
异步离策略架构的核心机制是使用async_gen_next_batch进行异步rollout生成,同时通过create_continuous_iterator在epoch转换期间保持连续运行,无需额外的样本存储管理。
# 迭代器生成器,简化训练过程的单步集成
def _create_continuous_iterator(self):
for epoch in range(self.config.trainer.total_epochs):
iterator = iter(self.train_dataloader)
for batch_dict in iterator:
yield epoch, batch_dict
# 读取下一批次样本,参数同步并启动异步生成
def _async_gen_next_batch(self, continuous_iterator):
try:
epoch, batch_dict = next(continuous_iterator)
except StopIteration:
return None
batch = DataProto.from_single_dict(batch_dict)
gen_batch = batch_pocess(batch)
# 从actor同步权重到rollout
self.sync_rollout_weights()
# 异步生成
gen_batch_output = self.rollout_wg.async_generate_sequences(gen_batch)
# 封装future对象
return GenerationBatchFuture(epoch, batch, gen_batch_output)
continuous_iterator = self._create_continuous_iterator()
# 首次运行rollout以实现单步离策略
batch_data_future = self._async_gen_next_batch(continuous_iterator)
while batch_data_future is not None:
# 等待前一步的生成结果
batch = batch_data_future.get()
# 启动下一次异步生成调用
batch_data_future = self._async_gen_next_batch(continuous_iterator)
# 计算优势函数
batch = critic.compute_values(batch)
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch)
batch = compute_advantages(batch)
# 模型更新
critic_metrics = critic.update_critic(batch)
actor_metrics = actor.update_actor(batch)
实现代码位于:recipe/one_step_off_policy/main_ppo.py
参数同步机制
基于NCCL的rollout模型权重更新性能优异,大多数情况下延迟低于300ms,对于RLHF几乎可以忽略不计。
# 通过nccl同步参数的驱动过程
def sync_rollout_weights(self):
self.actor_wg.sync_rollout_weights()
ray.get(self.rollout_wg.sync_rollout_weights())
# FSDP模型参数同步
@register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=False)
def sync_rollout_weights(self):
params = self._get_actor_params() if self._is_actor else None
if self._is_rollout:
inference_model = (
self.rollout.inference_engine.llm_engine.model_executor.driver_worker.worker.model_runner.model
)
from verl.utils.vllm.patch import patch_vllm_moe_model_weight_loader
patch_vllm_moe_model_weight_loader(inference_model)
# 模型参数从actor逐张量广播到rollout
for key, shape, dtype in self._weights_info:
tensor = torch.empty(shape, dtype=dtype, device=get_torch_device().current_device())
if self._is_actor:
assert key in params
origin_data = params[key]
if hasattr(origin_data, "full_tensor"):
origin_data = origin_data.full_tensor()
if torch.distributed.get_rank() == 0:
tensor.copy_(origin_data)
from ray.util.collective import collective
collective.broadcast(tensor, src_rank=0, group_name="actor_rollout")
if self._is_rollout:
inference_model.load_weights([(key, tensor)])
详细实现可参考:recipe/one_step_off_policy/fsdp_workers.py
性能对比:异步架构的效率提升
实验配置:
- 机器配置:2个节点,每个节点16个H20 GPU
- 生成:4个GPU
- 训练:12个GPU
- 模型:Qwen2.5-Math-7B
- 算法:DAPO
- Rollout引擎:vLLM
| 训练模式 | 引擎 | 步数 | 生成时间 | 等待生成时间 | 总时间 | 准确率提升 |
|---|---|---|---|---|---|---|
| 协同同步 | VLLM+FSDP2 | 749 | 321 | - | 19h18m | 基准 |
| 单步重叠异步 | VLLM+FSDP2 | 520 | - | 45 | 15h34m(+23%) | +3.6% |
| 协同同步 | VLLM+Megatron | 699 | 207 | - | 18h21m | 基准 |
| 单步重叠异步 | VLLM+Megatron | 566 | - | 59 | 13h06m(+40%) | +8.6% |
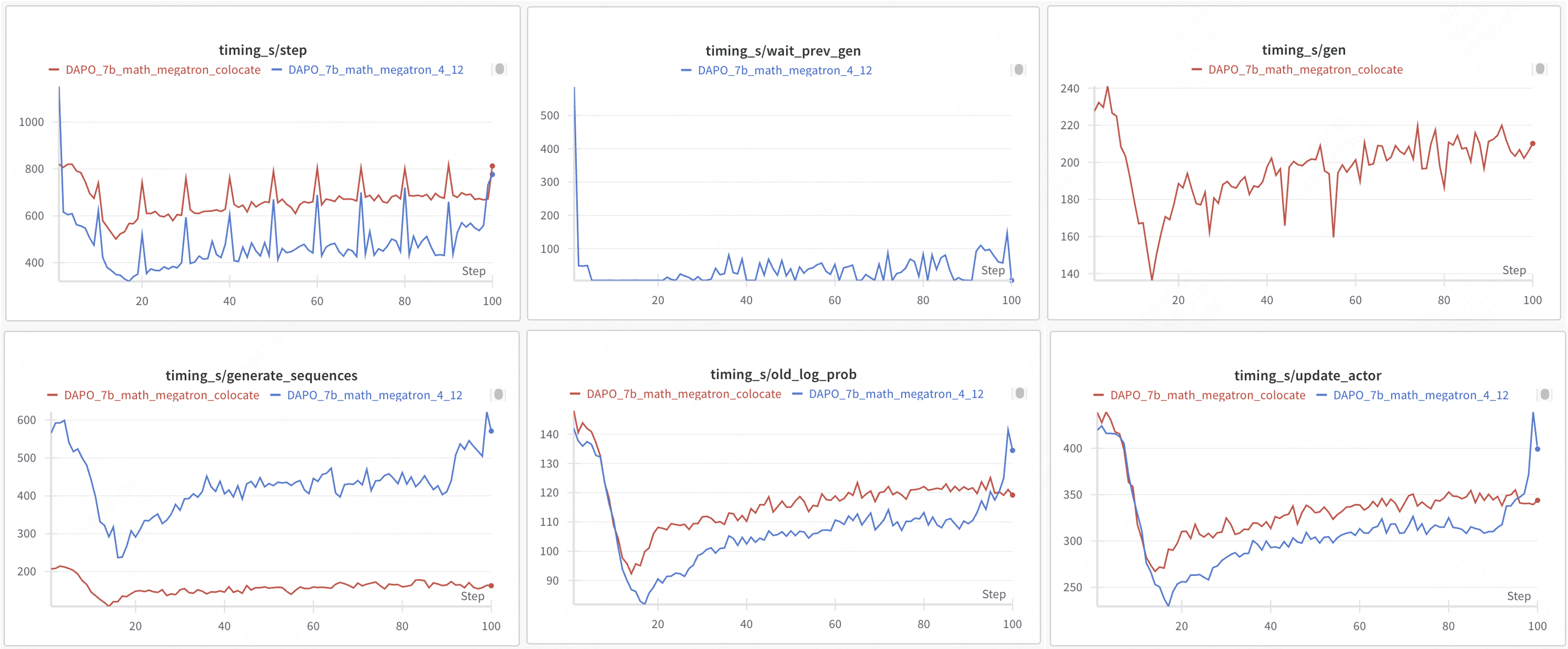
完整实验数据:docs/advance/one_step_off.md
快速上手:配置与使用指南
FSDP2配置示例
python3 -m recipe.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_trainer.yaml' \
actor_rollout_ref.actor.strategy=fsdp2 \
# 分离放置actor和rollout
actor_rollout_ref.hybrid_engine=False \
# actor和rollout资源配置
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2
配置文件模板:recipe/one_step_off_policy/config
Megatron配置示例
python3 -m recipe.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_megatron_trainer.yaml' \
actor_rollout_ref.actor.strategy=megatron \
# 分离放置actor和rollout
actor_rollout_ref.hybrid_engine=False \
# actor和rollout资源配置
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2
资源配置策略
-
卡数关系:
actor_rollout_ref.rollout.n应为trainer.n_gpus_per_node * trainer.nnodes的整数除数actor_rollout_ref.rollout.n * data.train_batch_size应能被trainer.n_gpus_per_node * trainer.nnodes整除
-
动态资源调整:
- 理想状态:Rollout和训练阶段持续时间相当
- 诊断指标:监控
wait_prev_gen持续时间和sequence_length分布 - 调整策略:
- 高
wait_prev_gen+均匀序列长度→增加rollout资源 - 高
wait_prev_gen+长尾序列→优化停止标准(增加资源无帮助)
- 高
-
资源配置公式:
- 当
trainer.n_gpus_per_node + rollout.n_gpus_per_node <= 物理每节点GPU数时,所需节点数为max(trainer.nnodes, rollout.nnodes) - 当
trainer.n_gpus_per_node + rollout.n_gpus_per_node > 物理每节点GPU数时,所需节点数为trainer.nnodes + rollout.nnodes
- 当
详细配置指南见:docs/advance/one_step_off.md
功能支持与兼容性矩阵
| 类别 | 支持情况 |
|---|---|
| 训练引擎 | FSDP2、Megatron |
| 生成引擎 | vLLM |
| 优势估计器 | GRPO、GRPO_PASSK、REINFORCE_PLUS_PLUS、RLOO、OPO、GPG |
| 奖励函数 | 全部支持 |
适用场景与限制
异步离策略架构特别适合:
- 长序列生成任务(>4k tokens)
- 具有明显长尾分布的数据集
- 需要最大化GPU利用率的场景
当前限制:
- 仅支持vLLM作为生成引擎
- 需要仔细调整资源分配比例
- 初始配置复杂度高于同步训练
未来展望与最佳实践
异步离策略架构代表了LLM强化学习训练的新一代范式,未来版本将进一步优化:
- 支持更多生成引擎(如SGLang)
- 自适应资源分配算法
- 多步离策略扩展
- 与动态批处理结合
最佳实践建议:
- 新任务先使用默认同步模式建立基准
- 当Rollout时间占比>50%时考虑切换异步模式
- 从保守资源分配开始(生成:训练 = 1:3)
- 使用性能分析工具监控:docs/perf/nsight_profiling.md
社区案例与教程:examples/grpo_trainer
通过采用verl的异步离策略架构,你可以在保持模型性能的同时显著提升训练效率。无论是学术研究还是工业级部署,这一创新架构都能帮助你充分利用计算资源,加速LLM的强化学习训练过程。
欢迎通过CONTRIBUTING.md参与项目贡献,或在examples目录下探索更多使用案例。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







