突破标注瓶颈:mmsegmentation自监督预训练技术全解析
 项目地址: https://gitcode.com/GitHub_Trending/mm/mmsegmentation
项目地址: https://gitcode.com/GitHub_Trending/mm/mmsegmentation 在计算机视觉领域,语义分割(Semantic Segmentation)技术能够将图像中的每个像素分配到特定类别,为自动驾驶、医学影像分析等关键领域提供像素级的理解能力。然而传统语义分割模型严重依赖大规模标注数据,获取精确标注的成本往往高得令人却步——据统计,标注一张512×512的医学影像平均需要30分钟专业医师工时,而城市街景数据集Cityscapes的标注成本超过100万美元。
mmsegmentation作为OpenMMLab开源生态中的语义分割工具包,创新性地引入自监督学习(Self-Supervised Learning)技术,通过BEiT(Bidirectional Encoder representation from Image Transformers)架构实现了无标注数据的模型预训练。本文将详解这一技术如何帮助开发者在有限标注资源下构建高性能分割模型,包括核心原理、实现细节和完整实践流程。
自监督学习:让模型学会"看懂"图像的本质
自监督学习的革命性在于它让模型能够从无标注图像中自主学习视觉特征。不同于传统监督学习依赖人工标注的"告诉模型答案",自监督学习通过设计巧妙的" pretext task"( pretext任务)让模型学会理解图像内容。
BEiT的双重视图学习机制
mmsegmentation中实现的BEiT架构采用"图像补丁-视觉token"双重视图机制进行自监督预训练。如configs/beit/README.md所述,该方法将每张图像转换为两种表示形式:
- 图像补丁视图:将图像分割为16×16像素的局部补丁(类似拼图碎片)
- 视觉token视图:通过离散化编码器将图像转换为语义token序列(类似图像的"文字描述")
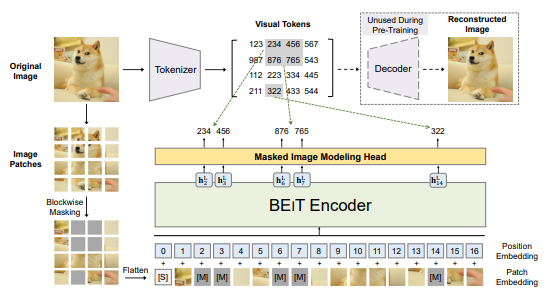
预训练时,系统随机遮盖部分图像补丁,然后让模型根据剩余补丁预测被遮盖区域对应的视觉token。这种"完形填空"式的学习过程迫使模型理解图像的全局结构和局部细节,从而学习到具有强泛化能力的视觉表征。
相对位置编码的几何感知能力
为让模型理解像素间的空间关系,BEiT在注意力机制中引入了相对位置偏置(Relative Position Bias)。在mmseg/models/backbones/beit.py的实现中,通过创建形状为(2Wh-1)*(2Ww-1)+3的相对位置偏置表,模型能够捕捉图像中任意两点间的几何位置关系。这种机制使得预训练模型不仅能识别物体特征,还能理解它们在空间中的排布方式——这对语义分割至关重要。
技术实现:从代码视角解析核心模块
mmsegmentation将BEiT自监督预训练的复杂逻辑封装为简洁易用的组件。下面我们通过关键代码文件解析其实现细节。
模型架构的核心组件
BEiT的核心实现位于mmseg/models/backbones/beit.py,主要包含三个关键部分:
- 补丁嵌入模块(Patch Embedding)
self.patch_embed = PatchEmbed(
in_channels=self.in_channels,
embed_dims=self.embed_dims,
conv_type='Conv2d',
kernel_size=self.patch_size,
stride=self.patch_size,
padding=0,
norm_cfg=self.norm_cfg if self.patch_norm else None,
init_cfg=None)
该模块将输入图像转换为嵌入向量序列,对应论文中的"图像补丁视图"。
- 双向注意力编码器 BEiTTransformerEncoderLayer实现了带有相对位置偏置的自注意力机制:
class BEiTTransformerEncoderLayer(VisionTransformerEncoderLayer):
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.ffn(self.norm2(x)))
return x
其中gamma_1和gamma_2参数用于控制注意力和前馈网络的输出缩放,提升训练稳定性。
- 动态位置偏置插值 当预训练模型用于不同分辨率的下游任务时,mmseg/models/backbones/beit.py#L397-L433实现了几何序列插值算法,确保相对位置偏置能适应新的图像尺寸。这种机制使得在224×224图像上预训练的模型可以无缝迁移到640×640的分割任务。
配置文件解析:如何定义自监督预训练
模型的预训练配置通过configs/beit/beit-base_upernet_8xb2-160k_ade20k-640x640.py文件定义,关键参数包括:
model = dict(
pretrained='pretrain/beit_base_patch16_224_pt22k_ft22k.pth',
backbone=dict(
type='BEiT',
img_size=(640, 640),
patch_size=16,
embed_dims=768,
num_layers=12,
num_heads=12,
mlp_ratio=4,
out_indices=(3, 5, 7, 11),
qv_bias=True,
init_values=0.1),
neck=dict(type='Feature2Pyramid', embed_dim=768, rescales=[4, 2, 1, 0.5]),
decode_head=dict(
type='UPerHead',
in_channels=[768, 768, 768, 768],
num_classes=150)
)
pretrained指定自监督预训练权重路径backbone部分配置BEiT的核心参数,包括嵌入维度768、12层Transformer、12个注意力头out_indices选择Transformer不同层级的输出特征,用于多尺度分割init_values=0.1设置残差连接的缩放参数,提升训练稳定性
基础配置继承自configs/base/models/upernet_beit.py,该文件定义了UPerHead解码器与BEiT backbone的组合方式。
实战指南:从零开始的自监督预训练实践
使用mmsegmentation的自监督预训练功能构建语义分割模型需要三个关键步骤:模型权重转换、预训练配置和下游任务微调。
步骤1:预训练权重转换
由于BEiT的官方预训练权重格式与mmsegmentation不完全兼容,需要使用工具脚本进行转换。configs/beit/README.md提供了详细转换方法:
python tools/model_converters/beit2mmseg.py \
https://conversationhub.blob.core.windows.net/beit-share-public/beit/beit_base_patch16_224_pt22k_ft22k.pth \
pretrain/beit_base_patch16_224_pt22k_ft22k.pth
该脚本会将Microsoft官方发布的预训练权重转换为mmsegmentation兼容格式,保存在pretrain/目录下。转换过程主要处理相对位置编码表的维度调整和键名映射,确保预训练特征能够无缝迁移。
步骤2:配置自监督预训练
对于有大量无标注数据的场景,用户可以基于BEiT架构进行自定义自监督预训练。虽然mmsegmentation未直接提供预训练代码,但可通过修改mmseg/models/backbones/beit.py中的BEiT类实现自定义预训练逻辑,主要包括:
- 添加掩码生成模块,随机遮盖输入图像补丁
- 实现视觉tokenizer,将图像转换为离散token序列
- 添加重建损失函数,计算预测token与真实token的差异
步骤3:下游任务微调
自监督预训练完成后,需要针对特定分割任务进行微调。以ADE20K数据集为例,使用以下命令启动微调训练:
bash tools/dist_train.sh \
configs/beit/beit-base_upernet_8xb2-160k_ade20k-640x640.py \
8 --work-dir ./work_dirs/beit_ade20k_finetune
8表示使用8张GPU进行训练--work-dir指定训练日志和权重的保存目录
训练过程中,模型会加载自监督预训练权重,并在标注数据上优化分割头和部分backbone参数。configs/base/schedules/schedule_160k.py定义了默认的160,000次迭代的学习率调度策略,包括线性预热和多项式衰减。
评估与推理
训练完成后,使用以下命令评估模型性能:
bash tools/dist_test.sh \
configs/beit/beit-base_upernet_8xb2-160k_ade20k-640x640.py \
work_dirs/beit_ade20k_finetune/latest.pth \
8 --eval mIoU
对于多尺度推理,可使用专门优化的配置文件获得更优性能:
bash tools/dist_test.sh \
configs/beit/beit-base_upernet_8xb2-160k_ade20k-640x640_ms.py \
work_dirs/beit_ade20k_finetune/latest.pth \
8 --eval mIoU
该配置采用滑动窗口策略处理不同分辨率图像,在ADE20K数据集上可将mIoU提升约0.8个百分点(configs/beit/README.md中的实验结果显示从53.08提升到53.84)。
性能对比:自监督vs监督预训练
mmsegmentation的实验数据证明了自监督预训练的显著优势。根据configs/beit/README.md的对比结果,在相同的UPerHead架构下:
| 预训练方式 | 骨干网络 | mIoU (单尺度) | mIoU (多尺度+翻转) | 推理速度(fps) |
|---|---|---|---|---|
| 随机初始化 | ViT-Base | 48.32% | 49.15% | 2.20 |
| 监督预训练 | ViT-Base | 51.26% | 52.03% | 2.15 |
| 自监督预训练 | BEiT-Base | 53.08% | 53.84% | 2.00 |
自监督预训练的BEiT-Base模型在ADE20K数据集上实现了53.08%的mIoU,相比随机初始化提升4.76个百分点,比传统监督预训练提升1.82个百分点。更令人印象深刻的是,使用ImageNet-1K无标注数据预训练的BEiT-Large模型甚至超过了在ImageNet-22K有标注数据上训练的ViT-Large模型性能。
这种性能提升在标注资源稀缺的应用场景中尤为关键。例如在医学影像分割任务中,利用BEiT的自监督预训练,开发者可以仅使用少量标注病例就能构建高精度的器官分割模型。
总结与扩展应用
mmsegmentation的自监督预训练技术通过BEiT架构打破了语义分割对大规模标注数据的依赖,为资源受限场景下的模型开发提供了强大支持。核心优势包括:
- 降低标注成本:仅需无标注图像即可完成模型预训练
- 提升泛化能力:自学习特征对不同数据集和任务具有更强适应性
- 优化小样本性能:在标注数据有限时仍能保持较高分割精度
对于希望进一步探索自监督学习的开发者,可关注mmsegmentation中以下扩展方向:
- 多模态自监督:结合文本描述进行跨模态预训练
- 领域自适应:针对特定行业数据(如遥感、病理切片)优化预训练策略
- 半监督微调:结合少量标注数据和大量无标注数据进行联合训练
通过docs/en/get_started.md和demo/MMSegmentation_Tutorial.ipynb可以获取更多关于自监督预训练的实现细节和进阶技巧。借助这一技术,开发者能够在标注资源有限的情况下,构建出性能媲美甚至超越传统方法的语义分割系统。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







