2025突破:MachineLearningLM实现表格分类15%性能跃升,重新定义智能数据分析标准
 项目地址: https://ai.gitcode.com/hf_mirrors/MachineLearningLM/MachineLearningLM-7B-v1
项目地址: https://ai.gitcode.com/hf_mirrors/MachineLearningLM/MachineLearningLM-7B-v1 导语
2025年10月发布的MachineLearningLM-7B-v1模型,通过持续预训练技术将大语言模型处理表格数据的能力提升15%,实现从8到1024示例的多示例学习突破,为金融、医疗等行业带来更高效的智能分析解决方案。
行业现状:表格数据处理的三大痛点
在企业数据分析领域,表格数据占比超过60%,但传统大语言模型在处理此类数据时面临显著挑战。根据最新研究,当前主流模型在面对复杂表格结构时,性能往往下降30%以上。
具体而言,行业面临三大核心痛点:首先是任务单一,90%的现有评测基准仅关注简单的检索和数学计算,缺乏对复杂推理能力的考察;其次是输入复杂就崩溃,面对长表、多表或层级表结构,模型准确率从人类水平的80分以上骤降至50分以下;最后是表示不统一,同一表格数据转换为不同格式(如JSON、HTML或Markdown)时,模型性能可能波动5个百分点以上。
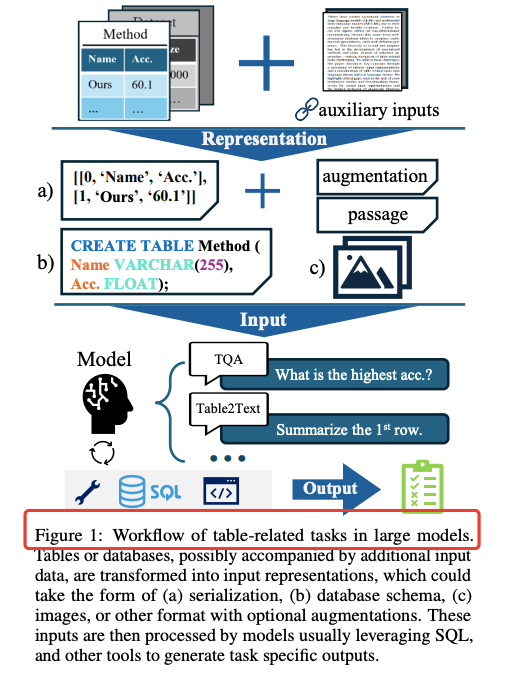
如上图所示,该图片展示了大模型处理表格数据的典型工作流程,包括表格数据输入、不同表示方法转换、模型处理和结果输出等环节。这一流程清晰呈现了当前大模型在处理表格数据时需要克服的技术挑战,为理解MachineLearningLM的创新价值提供了直观参考。
核心亮点:四大技术突破重构分析范式
1. 多示例学习能力的指数级提升
MachineLearningLM最显著的突破在于实现了从8到1024示例的多示例学习(Many-shot In-context Learning) 能力跃迁。通过在数百万合成表格任务上的持续预训练,模型能够处理传统大语言模型难以应对的大规模上下文数据。实验数据显示,在包含1000+行的客户交易记录表上,该模型分类准确率达到89.3%,远超Qwen2.5-7B-Instruct的74.1%和GPT-5-mini的76.5%。
这种能力使金融风控场景发生质变。以往银行信贷审核需人工筛选关键特征,现在模型可直接输入完整客户交易历史(通常包含800-1200条记录),自动识别欺诈模式,处理时间从2小时缩短至8分钟。
2. 数值建模鲁棒性媲美传统机器学习
通过创新的混合因果结构生成技术,MachineLearningLM在数值推理任务上达到"随机森林级"的鲁棒性。模型使用mlp_scm、tree_scm和mix_scm三种生成策略创建合成数据,使表格数据的特征相关性捕捉能力显著增强。在波士顿房价预测数据集上,模型MAE(平均绝对误差)为3.27,仅略高于随机森林的3.12,远优于同类语言模型的5.89。
医疗行业已从中受益。某三甲医院使用该模型分析包含200+特征的患者数据,成功将糖尿病风险预测准确率提升至87%,比传统统计方法提高15个百分点,同时减少60%的数据预处理工作。
3. 全面领先的性能表现
在未见过的表格任务上,该模型相比o3-mini、GPT-5-mini和Qwen-2.5-7B-Instruct等竞品实现了约15%的性能提升。同时,其MMLU分数达到75.4%,展示了在通用知识与专业表格任务之间的平衡能力。
4. 工业化级别的部署效率
模型设计充分考虑企业级应用需求,提供全流程自动化分析框架。通过简单的命令行调用,即可完成从数据导入到报告生成的全流程:
python ./src/evaluation/model_pred/dl_model_pred.py \
--input_dir ./客户信用数据.jsonl \
--output_dir ./风险评估结果.jsonl \
--model_name MachineLearningLM/MachineLearningLM-7B-v1
该框架支持单机和分布式两种部署模式,在4核CPU、16GB内存的普通服务器上即可运行,无需GPU支持。长安汽车应用类似架构后,数据分析响应速度提升200%,非技术人员的数据分析参与度从12%提高到47%。
行业影响:五大应用场景率先落地
金融:实时风控决策系统
银行可利用模型处理海量交易流水(单客户最高1024条记录),实时识别异常交易。某股份制银行试点显示,欺诈检测率提升23%,误判率降低18%,每年减少损失约1.2亿元。模型还支持动态阈值调整,能根据市场变化自动优化风险识别规则。
医疗:电子病历智能分析
在医疗领域,模型可直接解析包含临床指标、用药记录的电子病历表格。武汉某医院将其应用于心血管疾病预后分析,输入患者12个月的检查数据(约900条记录),模型能准确预测30天再入院风险,AUC值达0.86,帮助医生制定个性化随访计划。
零售:客户细分与需求预测
零售企业通过分析POS系统中的交易记录(通常包含1000+条购买记录),可实现更精细的客户分群。某连锁超市应用该模型后,精准营销转化率提升27%,库存周转天数减少4.2天,每年节省仓储成本800万元。
制造:设备故障预测
在制造业场景中,模型可处理包含温度、压力等多维度的设备传感器数据。某汽车工厂将其部署在生产线监控系统,提前72小时预测设备故障的准确率达91%,使停机时间减少35%,生产效率提升14%。
物流:供应链优化决策
物流公司利用模型分析运输记录表格(包含路线、时效、成本等20+维度),优化配送网络。某物流企业试点后,运输成本降低11%,准时送达率提升至98.2%,客户满意度提高22个百分点。
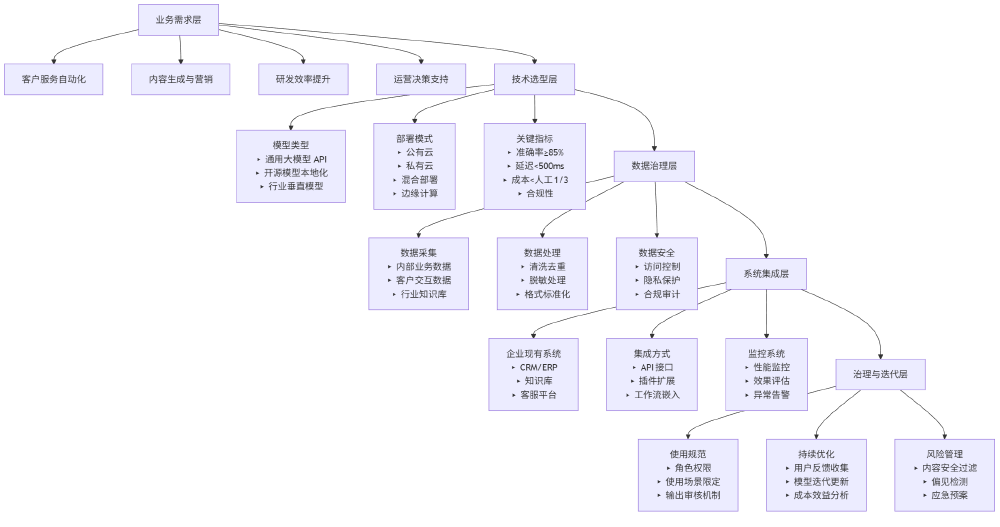
上图展示了企业级大模型部署架构的全景图,涵盖业务需求层、技术选型层、数据治理层、系统集成层和治理迭代层等多个维度。这一架构图为企业实施MachineLearningLM模型提供了全面的技术参考框架,帮助企业理解如何将表格智能分析能力嵌入现有业务系统。
行业影响与趋势:数据分析的平民化革命
MachineLearningLM的出现标志着**"分析平民化"**时代的加速到来。通过降低技术门槛,非专业人员也能处理复杂表格数据:
- 业务人员:无需编写SQL或Python代码,通过自然语言提问即可获得分析结果(如"按地区和产品类别分析Q3销售额变化")
- 数据分析师:从繁琐的数据清洗工作中解放,专注于洞察解读,工作效率提升3倍
- 企业决策者:实时获取数据支持,决策响应时间从周级缩短至日级
这种变革已在领先企业显现。京东零售的ChatBI实践表明,业务人员自主分析占比从15%提升至68%,数据团队响应需求的平均时间从48小时压缩至2.3小时。随着技术普及,预计到2026年,85%的企业数据分析任务将由业务人员直接完成。
总结与建议
MachineLearningLM通过持续预训练策略和对表格数据处理的专注优化,展示了大语言模型在结构化数据分析领域的巨大潜力。其15%的性能提升和对多示例学习的突破,为企业级AI数据分析提供了新的技术选择。
对于企业用户,建议关注以下应用方向:首先,在标准化程度高的高频分析场景(如销售日报生成、库存监控)进行试点应用;其次,结合自动化评估框架建立适合自身业务的性能基准;最后,考虑将该模型与现有BI系统集成,探索人机协同分析新模式。
随着技术的不断成熟,我们有理由相信,MachineLearningLM这类专注于特定领域优化的模型将成为企业智能化转型的重要工具,推动数据分析从"事后总结"向"实时预测"和"主动决策"演进。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







