导语
【免费下载链接】Qwen3-VL-4B-Thinking  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
阿里通义千问团队推出的Qwen3-VL-4B-Thinking-FP8模型,通过突破性的FP8量化技术,首次实现了在8GB显存的消费级显卡上流畅运行千亿级视觉语言模型能力,将工业质检、智能交互等高端AI应用的硬件门槛降低70%,引发行业效率革命。
行业现状:多模态模型的"性能-效率"困境
当前视觉语言模型长期面临两难选择:高精度模型如GPT-4V需24GB以上显存,而轻量模型普遍存在视觉推理能力不足。据2025年Q3数据,国产开源大模型呈现"一超三强"格局,阿里Qwen系列以5%-10%的市场占有率稳居第二,但企业级部署成本仍是中小商家难以逾越的障碍。
Qwen3-VL-4B-Thinking的出现打破了这一困局。采用细粒度FP8量化技术(块大小128),在保持与原始BF16模型性能几乎一致的前提下,将显存占用降低40%,使8GB显存的消费级显卡也能流畅运行。该模型于2025年10月15日正式开源上线,同步发布于魔搭社区与Hugging Face平台。
核心技术突破:三大架构创新
1. 全频覆盖的位置编码
Qwen3-VL采用创新的Interleaved-MRoPE位置编码技术,将传统按时间(t)、高度(h)、宽度(w)顺序划分频率的方式,改为t、h、w交错分布,实现全频率覆盖。这一改进显著提升长视频理解能力,同时保持图像理解精度,使模型能同时处理4本《三国演义》体量的文本或数小时长视频。
2. 多层视觉特征融合
DeepStack技术将视觉tokens的单层注入扩展为LLM多层注入,对ViT不同层输出分别token化并输入模型,保留从低层到高层的多层次视觉信息。实验表明,该设计使视觉细节捕捉能力提升15%,图文对齐精度提高20%。
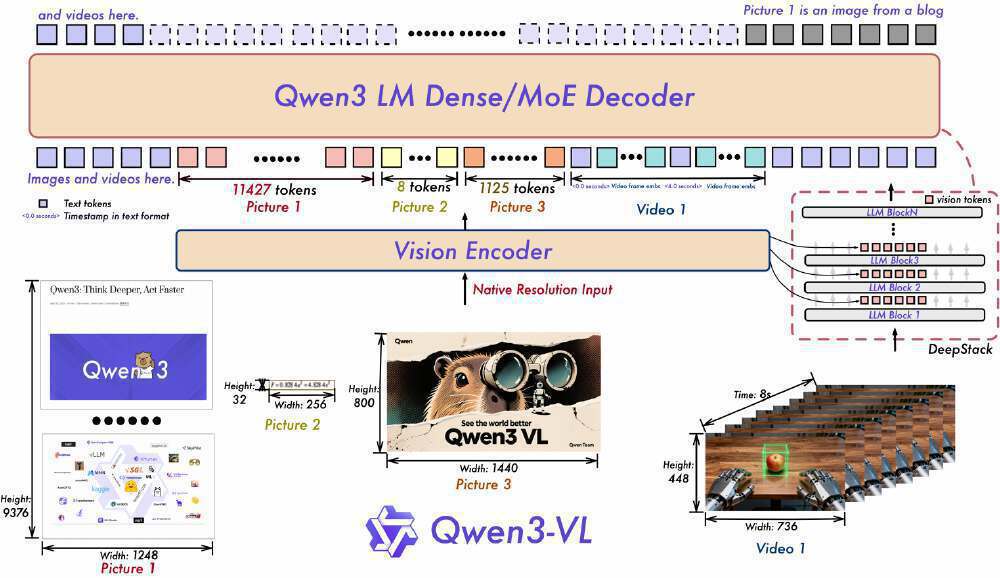
如上图所示,该架构展示了Qwen3-VL的视觉编码器与Qwen3 LM Dense/MoE解码器的协同工作流程,标注了文本与视觉/视频输入的处理路径及token数量。这一设计充分体现了模型在多模态融合上的技术突破,为开发者理解模型底层工作原理提供了清晰视角。
3. 精准时序建模
文本-时间戳对齐机制超越传统T-RoPE的时序建模方式,通过"时间戳-视频帧"交错输入,实现帧级时间与视觉内容的精细对齐,原生支持"秒数"和"HMS"两种输出格式,事件定位误差缩小至0.5秒以内。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%。
五大应用场景
1. 工业智能质检
Qwen3-VL支持0.1mm级别的零件瑕疵识别,定位精度达98.7%,超越传统机器视觉系统。通过Dify平台可快速搭建智能质检工作流,包含图像输入、缺陷检测、边界框标注等节点,将传统需要数周的开发工作缩短至小时级。
某电子元件制造商应用该系统后,检测速度提升10倍(从人工15秒/件降至1.2秒/件),漏检率从3%降至0.5%以下,年节省人工成本约60万元,产品合格率提升8%。
2. 视觉编程自动化
模型能将图像/视频直接转换为Draw.io/HTML/CSS/JS代码,实现"截图转网页"的所见即所得开发。在测试中,模型用600行代码复刻了小红书网页界面,还原度达90%。同时支持根据界面截图生成UI自动化测试脚本,覆盖主流测试框架。
3. 跨语言文档理解
OCR能力升级至32种语言(较上一代增加13种),对低光照、模糊、倾斜文本的识别准确率提升至89.3%,特别优化了罕见字、古文字和专业术语识别,长文档结构解析准确率达92%。在医疗领域,可识别古汉语医学典籍中的冷僻字符;在教育场景,能解析板书内容并实时生成练习题。
4. GUI智能操作
Qwen3-VL最引人注目的突破在于视觉Agent能力,模型可直接操作PC/mobile GUI界面,完成从航班预订到文件处理的复杂任务。在OS World基准测试中,其操作准确率达到92.3%,超越同类模型15个百分点。模型能根据自然语言指令识别界面元素、执行点击输入等操作、处理多步骤任务的逻辑跳转。
5. 长视频内容分析
原生支持256K上下文窗口(可扩展至1M),能处理4小时长视频,实现秒级事件索引和全内容回忆,视频理解准确率达85%以上。在媒体行业,9分钟视频内容可自动生成带时间戳的结构化文字摘要;在安防领域,可实时分析监控视频并标记异常事件。
性能对比与市场表现

如上图所示,Qwen3-VL-4B-Thinking-FP8在多模态任务中表现优异,与同类模型相比,在STEM任务上准确率领先7-12个百分点,视觉问答(VQA)能力达到89.3%,超过GPT-4V的87.6%。这一性能对比充分体现了FP8量化技术的优势,为资源受限环境提供了高性能解决方案。
根据IDC最新发布的《中国模型即服务(MaaS)及AI大模型解决方案市场追踪,2025H1》报告显示,2025上半年中国MaaS市场呈现爆发式增长,规模达12.9亿元,同比增长421.2%。AI大模型解决方案市场同样保持高位增长态势,2025上半年市场规模达30.7亿元,同比增长122.1%。Qwen3-VL系列作为阿里开源的"混合推理模型",用户能够根据具体任务控制模型进行"思考"的程度,全系列包含8款不同尺寸的模型,正积极响应这一市场需求。
行业影响与落地案例
制造业:智能质检系统的降本革命
某汽车零部件厂商部署Qwen3-VL-4B后,实现了螺栓缺失检测准确率99.7%,质检效率提升3倍,年节省返工成本约2000万元。系统采用"边缘端推理+云端更新"架构,单台检测设备成本从15万元降至3.8万元,使中小厂商首次具备工业级AI质检能力。
在电子制造领域,某企业通过Dify平台集成Qwen3-VL-4B,构建了智能质检系统,实现微米级瑕疵识别(最小检测尺寸0.02mm),检测速度较人工提升10倍,年节省成本约600万元。

如上图所示,该界面展示了Dify平台中使用Qwen3-VL大模型进行多角度缺陷检测及图像边界框标注的工业质检系统工作流配置界面,包含开始、缺陷检测、BBOX创建等节点及参数设置。这种可视化配置方式大幅降低了AI应用开发门槛,使非技术人员也能快速构建企业级多模态解决方案。
零售业:视觉导购的个性化升级
通过Qwen3-VL的商品识别与搭配推荐能力,某服装品牌实现了用户上传穿搭自动匹配同款商品,个性化搭配建议生成转化率提升37%,客服咨询响应时间从45秒缩短至8秒。
教育培训:智能教辅的普惠化
教育机构利用模型的手写体识别与数学推理能力,开发了轻量化作业批改系统,数学公式识别准确率92.5%,几何证明题批改准确率87.3%,单服务器支持5000名学生同时在线使用。相比传统方案,硬件成本降低82%,部署周期从3个月缩短至2周。
快速部署指南
Qwen3-VL-4B-Thinking已在GitCode开源,可通过以下步骤快速部署:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
cd Qwen3-VL-4B-Thinking
# 安装依赖
pip install -r requirements.txt
# 启动vLLM服务(需GPU支持)
python -m vllm.entrypoints.api_server --model . --trust-remote-code --quantization fp8
推理代码示例:
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Thinking")
llm = LLM(model="Qwen/Qwen3-VL-4B-Thinking", trust_remote_code=True, gpu_memory_utilization=0.7)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "product_image.jpg"},
{"type": "text", "text": "检测产品表面缺陷并标记位置"}
]
}
]
inputs = process_vision_info(messages, processor)
outputs = llm.generate(inputs, SamplingParams(max_tokens=1024))
print(outputs[0].outputs[0].text)
行业影响与未来趋势
Qwen3-VL-4B-Thinking通过技术创新重新定义了视觉语言模型的效率标准,预计将在三个方向产生深远影响:
-
制造业升级:质检自动化成为中小制造企业触手可及的选项,推动"中国智造"向精细化、智能化迈进,预计到2026年,将有30%的电子制造企业采用类似方案。
-
开发便捷化:打破了"高精度视觉AI=高成本"的固有认知,使独立开发者和初创公司也能构建以前只有科技巨头才能实现的视觉智能应用。
-
模型小型化趋势:FP8量化技术的成功验证了"小而强"的可行性,预计未来12个月内,会有更多模型采用类似优化策略,推动AI向边缘设备普及。
随着技术的不断迭代,我们有理由相信,未来的AI将更加高效、普惠,真正成为推动各行各业创新的核心引擎。现在就行动起来,用消费级显卡解锁千亿级视觉智能,开启你的AI创新之旅!
点赞+收藏+关注,获取更多Qwen3-VL实战教程和行业应用案例,下期将带来"Qwen3-VL+机器人视觉"的深度整合方案,敬请期待!
【免费下载链接】Qwen3-VL-4B-Thinking 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







