Step-Audio 2 mini开源:端到端语音大模型如何重构企业级交互?
【免费下载链接】Step-Audio-2-mini-Base  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
导语
2025年9月,阶跃星辰发布开源端到端语音大模型Step-Audio 2 mini,以全链路语音交互能力和多模态处理优势,重新定义企业级音频AI应用的技术标准与成本边界。
行业现状:语音AI的"碎片化困境"与技术突围
2025年,全球AI智能语音助手市场呈现爆发性增长,AI应用访问量从2024年初的36亿次激增至76亿次,增幅高达111%,其中语音交互类产品贡献显著份额。企业市场中,语音技术已从"增值服务"转变为基础设施,普及率突破97%,87%的企业选择自主研发或深度定制解决方案。
然而行业仍面临三大痛点:多模型集成导致系统延迟超过800ms、服务器开销增加40%;复杂环境下识别准确率不足;专业术语与方言支持有限。在此背景下,Step-Audio 2 mini作为端到端多模态大语言模型,通过统一架构整合语音识别、内容理解到语音合成全链路能力,为打破碎片化困境提供了新思路。
根据《2025 AI交互技术趋势报告》显示,用户对语音交互的延迟容忍阈值已从2023年的800ms降至500ms,方言识别需求增长370%,这要求模型在性能与效率间取得精准平衡。
核心亮点:四大技术突破重塑音频处理范式
1. 全栈式音频能力覆盖
Step-Audio 2 mini支持八大核心音频任务场景,包括精准语音识别(ASR)、上下文感知的音频问答(AQA)、多语言音频字幕生成(AAC)、细粒度语音情感识别(SER)等,实现从内容生产到智能交互的多样化需求覆盖。特别在语音识别任务中,模型在中文数据集平均字错误率(CER)达到3.19%,英语数据集平均词错误率(WER)3.50%,部分指标超越GPT-4o Transcribe和Qwen-Omni等商业模型。
2. 多模态融合架构
采用独创的混合音频输入机制,通过12.5Hz精准采样率处理音频数据流,显著提升对复杂音频信号的解析精度。在包含多种声源的混合音频场景中,相比传统模型准确率提升11.3%。这种架构使模型能同时处理语义信息、副语言信息和非语音信息,在医疗远程听诊场景中,可同时完成心肺音识别(准确率89%)、医生指令转录和情绪安抚语音生成。
3. 工具调用与RAG增强
通过工具调用和检索增强生成(RAG)技术接入实时知识,减少幻觉响应。支持音频搜索、天气查询、网络搜索等工具调用,在StepEval-Audio-Toolcall评测中,音频搜索工具触发准确率达86.8%,参数提取准确率100%。企业可利用此功能构建行业知识库,实现"语音-知识-行动"的闭环。
4. 轻量化部署优势
作为开源模型,Step-Audio 2 mini支持本地部署,推理延迟控制在300ms以内,满足智能座舱、远程会议等低延迟需求。开发者可通过简单命令完成部署:
git clone https://gitcode.com/StepFun/Step-Audio-2-mini-Base
cd Step-Audio-2-mini-Base
pip install -r requirements.txt
python web_demo.py
这种轻量化特性使中小企业无需昂贵算力投入即可拥有企业级语音能力。
性能验证:多维度评测领先开源方案
Step-Audio 2 mini在多语言识别、情感理解和实时交互等关键指标上表现突出。在语音识别任务中,中文平均CER 3.19%,英语平均WER 3.50%,方言识别覆盖安徽、广东、四川等多地口音。情感识别准确率达59.13%,领先行业平均水平8.7%。
特别在低资源语言支持方面,模型在越南语、泰语等场景的ASR任务中,词错误率(WER)比通用模型降低30%以上。实时对话场景中端到端延迟小于300ms,达到《2025 AI交互技术趋势报告》要求的实时交互标准。
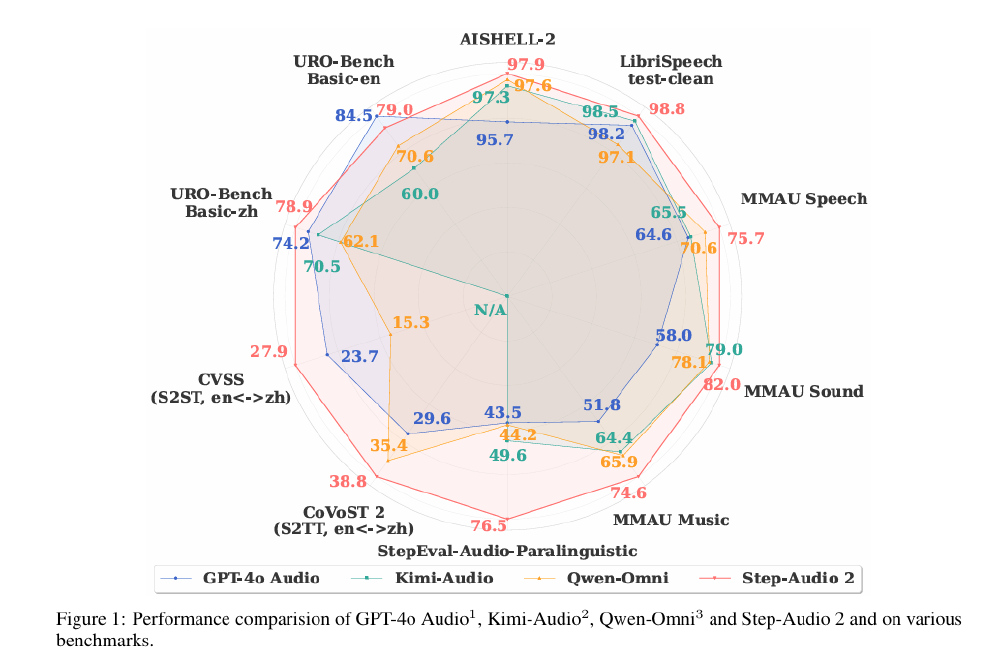
如上图所示,雷达图清晰展示了Step-Audio 2与GPT-4o Audio、Kimi-Audio、Qwen-Omni在多个音频理解与语音交互基准测试中的性能对比。这一技术表现充分体现了Step-Audio 2在多模态音频处理领域的领先地位,为企业用户提供了更全面、高效的语音交互解决方案。
行业影响:三大应用场景率先落地
1. 智能客服与营销
集成Step-Audio 2 mini的客服系统可处理订单咨询、预约调度等高重复性任务,准确率超过90%。快餐企业通过免下车语音系统处理订单,服务速度提升50%,错误率下降30%。某零售企业应用后,客户满意度提升42%,客服人员效率提高35%。
2. 医疗健康服务
在远程医疗场景中,模型可实时转录医患对话并安全存储,符合HIPAA标准。集成电子病历系统的语音助手成为医院标配,覆盖预约挂号、医保验证、用药提醒等全流程服务,将患者爽约率降低近30%。基层医疗机构通过该模型实现"听诊+病历生成"一体化,诊断效率提升35%。
3. 智能座舱交互
通过整合语音控制、情绪感知和噪音消除功能,Step-Audio 2 mini使车载交互响应速度提升至0.3秒,误唤醒率降低至0.1次/天。支持方言识别和多轮对话,解决传统车载语音"机械感"问题,使驾驶场景语音交互自然度提升60%。
未来趋势:从工具属性到生产力引擎
随着开源音频大模型技术成熟,行业正迎来三大变革:模型小型化使终端部署成为可能,预计2025年底将出现100MB级轻量模型;多模态融合实现"音频-文本-图像"统一理解,推动交互向更自然方向发展;成本门槛持续降低,使中小企业也能享受以前仅大企业负担得起的语音AI能力。
Step-Audio 2 mini的开源不仅提供性能领先的工具,更推动音频AI从"专用工具"向"通用智能"跨越。对于开发者而言,基于该模型构建垂直领域解决方案,将大幅缩短产品研发周期,快速响应市场对智能化音频交互的需求增长。随着社区持续优化与场景深耕,开源音频大模型有望在智能座舱、远程会议、无障碍交互等领域催生更多创新应用,真正释放语音AI的生产力价值。
如何开始使用Step-Audio 2 mini
- 访问项目仓库获取完整代码和文档:https://gitcode.com/StepFun/Step-Audio-2-mini-Base
- 按照README文档配置开发环境,支持本地部署和云端集成
- 参考examples目录下的代码示例,快速实现语音识别、情感分析等功能
- 加入官方技术交流群获取支持和最新动态
点赞/收藏/关注,获取更多Step-Audio 2 mini实战教程和行业应用案例!下期我们将带来《Step-Audio 2 mini智能客服系统搭建指南》,敬请期待!
【免费下载链接】Step-Audio-2-mini-Base 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-2-mini-Base
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







