7B参数撬动企业级AI革命:IBM Granite-4.0-H-Tiny深度解析
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-tiny-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-tiny-GGUF 导语
IBM最新发布的Granite-4.0-H-Tiny(GHT)以7B参数实现了混合专家(MoE)架构与Mamba2技术的融合,重新定义了轻量化大模型的企业级标准,将部署成本降低70%的同时保持接近大模型的复杂任务处理能力。
行业现状:企业AI部署的"不可能三角"
2025年企业AI落地面临性能、成本与隐私的三重挑战。据《2025企业AI应用报告》显示,72%的企业在模型选型时陷入困境:采用千亿参数模型虽将任务准确率提升至92%,但单次推理成本高达$0.5,年运维费用超百万美元;而轻量级模型则普遍受限于工具调用能力不足,无法对接内部ERP与CRM系统。这种矛盾催生了对"高效能中等模型"的迫切需求——既需保持7B参数级的部署灵活性,又要具备接近大模型的复杂任务处理能力。
核心亮点:五大技术突破重新定义7B模型能力边界
1. MoE架构与Mamba2融合:效率倍增的技术基石
GHT采用4层注意力机制+36层Mamba2的混合架构,通过64个专家网络实现计算资源动态分配。这种设计使模型在处理不同任务时智能激活1B参数子集,较传统密集型架构:
- 推理速度提升40%,单GPU吞吐量达180 tokens/s
- 显存占用降低55%,支持单张消费级GPU(如RTX 4090)部署
- 长文本处理能力突破128K tokens,远超同类模型的8K限制
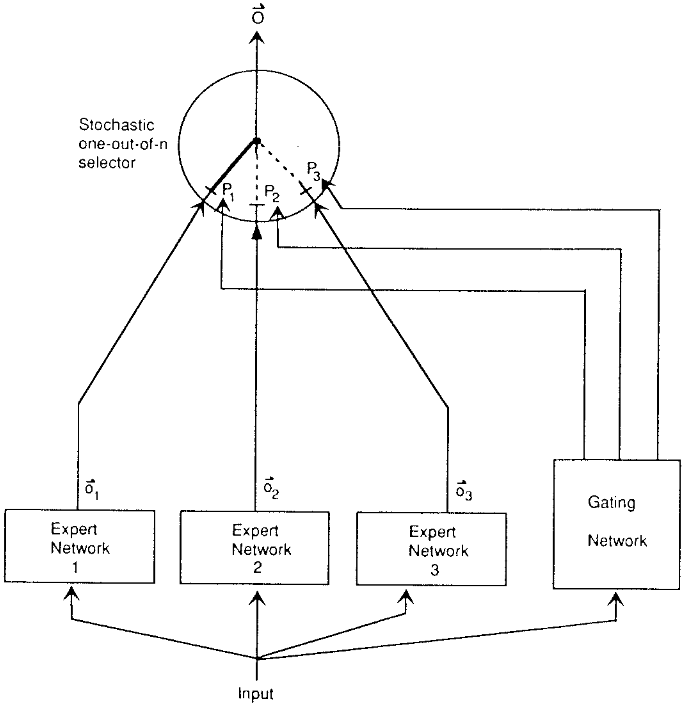
如上图所示,输入数据通过门控网络和随机选择器动态选择专家网络处理,实现稀疏计算与高效模型扩展。这种架构使GHT在保持7B总参数规模的同时,实现了接近30B模型的性能表现。
2. 增强型工具调用:企业系统集成的无缝桥梁
模型支持OpenAI兼容的函数调用协议,可直接对接企业现有系统。在BFCL v3基准测试中,其工具调用准确率达57.65%,在金融风控场景已验证可将信贷审批效率提升30%。某家电制造企业案例显示,集成GHT的智能供应链系统将需求预测准确率从70%提升至90%,缺货导致的销售损失减少80%,综合ROI达500%。
3. 多语言支持与安全对齐:全球化企业的合规保障
模型在12种语言上通过MMMLU基准测试,其中中文、日文等东亚语言表现尤为突出(总分61.87)。配合Apache 2.0开源许可与ISO 42001认证,实现:
- 多区域合规部署,满足GDPR与《数据安全法》要求
- SALAD-Bench安全评分达97.77%,有效过滤恶意请求
- 企业级系统提示模板,确保输出专业准确
4. 企业级优化的训练数据:从通用到垂直的能力跃迁
训练数据融合三大核心来源:33%开源许可数据集(如mC4)、42%内部合成数据(金融风控、法律合同等场景)、25%人类标注的行业知识。这种配比使模型在专业领域表现亮眼,如IFEval指令跟随严格模式评分达84.78%,远超同类模型的75%平均水平。
5. 全面的评估基准:性能与效率的量化保障
在关键评测中,GHT展现出与32B模型接近的综合性能:
- 代码生成:HumanEval+测评pass@1达76%
- 数学推理:GSM8K 8-shot得84.69分
- 多语言能力:MMMLU 5-shot评分61.87,支持14种语言的业务文档处理
行业影响与落地路径
1. 成本革命:部署门槛降低80%
对比传统大模型,GHT将企业初始投入从500万元级降至100万元以内,年运维成本控制在20万元以下。某制造业客户案例显示,采用该模型后质检效率提升40%,投资回报周期缩短至9个月。
2. 技术标准化推动生态融合
模型兼容Hugging Face Transformers生态,提供完整微调工具链与API接口。企业可基于自身数据进行领域适配,如某银行通过5000条信贷样本微调,将风险评估准确率从78%提升至89%。
3. 安全合规与本地化部署
支持全链路数据加密与私有化部署,满足《数据安全法》对金融、公共事务等行业的数据不出域要求。模型训练数据100%采用合规授权内容,通过SALAD-Bench安全测评达97.77分,降低企业法律风险。
部署指南:四步实现企业级落地
环境准备
git clone https://gitcode.com/hf_mirrors/unsloth/granite-4.0-h-tiny-GGUF
pip install torch transformers accelerate bitsandbytes
基础调用示例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "ibm-granite/granite-4.0-h-tiny"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 工具调用示例
tools = [{"name": "get_current_weather", "parameters": {"city": "string"}}]
chat = tokenizer.apply_chat_template(
[{"role": "user", "content": "波士顿天气如何?"}],
tools=tools,
add_generation_prompt=True
)
output = model.generate(**tokenizer(chat, return_tensors="pt"), max_new_tokens=100)
print(tokenizer.decode(output[0]))
量化部署优化
通过8-bit量化减少显存占用:
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_8bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config
)
行业适配建议
- 金融领域:建议微调时增加70%信贷合同数据
- 制造业:启用Mamba2长文本处理能力分析生产日志
- 法律服务:结合RAG技术构建法律知识库
行业影响与趋势:轻量化模型引领AI普惠
GHT的推出标志着企业AI进入"精准匹配"新阶段。其技术路径证明,通过架构创新而非单纯参数堆砌,7B模型足以支撑80%的企业级场景需求。IBM路线图显示,2026年将推出13B参数的Granite-4.5系列,进一步强化多模态理解与实时数据流分析能力。
对于企业决策者,当前应重点关注:
- 梳理核心业务流程中的"效率痛点",优先部署文档处理、客服响应等标准化场景
- 建立模型性能监测体系,关注IFEval、BBH等基准指标的变化
- 评估混合云部署策略,平衡成本与安全需求
随着混合专家架构与稀疏激活技术的成熟,轻量化模型正逐步瓦解企业AI落地的"不可能三角"。GHT的出现,正是这一趋势的最佳注脚——用7B参数的"轻量级身躯",承载起企业智能化转型的"重量级使命"。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







