2.8B参数颠覆多模态推理:Kimi-VL-A3B-Thinking-2506开启高效智能新纪元
【免费下载链接】Kimi-VL-A3B-Thinking  项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
导语
MoonshotAI最新发布的Kimi-VL-A3B-Thinking-2506版本实现多模态推理准确率提升20%的同时降低20%Token消耗,以2.8B激活参数挑战70B级模型性能,标志着视觉语言模型正式进入"高效智能"时代。
行业现状:多模态AI成企业数字化转型核心引擎
2025年,多模态大模型已成为人工智能领域最具变革性的技术引擎。Gartner技术成熟度曲线显示,多模态AI模型已进入生产力成熟期,全球头部企业研发投入中相关技术占比达42.3%。IDC预测,2026年全球65%的企业应用将依赖跨模态交互技术,但企业级部署仍面临"三重困境":年均成本高达120万元,65%中小企业因资源限制无法享受前沿AI能力,多模态模型普遍存在模态冲突与推理延迟问题。
与此同时,智能文档处理市场呈现爆发式增长。据MetaTech Insights报道,全球智能文档处理(IDP)市场2024年规模为25.6亿美元,预计到2035年将增长至545.4亿美元,2025至2035年复合年增长率约32.06%。制造业质检、医疗影像分析、金融文档处理等垂直领域对高精度多模态理解的需求日益迫切,但85%的中小企业仍受限于算力成本,无法部署先进的多模态检索系统。
核心亮点:四大技术突破重构效率边界
1. 智能思考机制:效率与精度的完美平衡
2506版本在多模态推理基准测试中实现显著提升:MathVision准确率达56.9(+20.1)、MathVista 80.1(+8.4)、MMMU-Pro 46.3(+3.3),同时平均思考长度减少20%。这种"更聪明地思考"能力源于模型优化的推理路径规划,能够在复杂数学问题和多步骤逻辑推理中实现更高效率。
值得注意的是,该版本首次实现思考能力与通用视觉理解的协同增强。在MMBench-EN-v1.1(84.4)、MMStar(70.4)等通用视觉任务上,不仅超越了前代思考模型,还达到甚至超越了专用的Kimi-VL-A3B-Instruct模型水平,解决了以往思考型模型"专精有余、通用不足"的痛点。
2. 超高分辨率处理:细节感知能力跃升4倍
新版本支持单张图像320万像素处理,是前代版本的4倍,带来高分辨率感知任务的突破性表现:V* Benchmark达83.2(无需额外工具)、ScreenSpot-Pro 52.8、OSWorld-G 52.5。这一能力使模型能精准识别图像中的微小细节,如医学影像中的微小结节、工业零件的细微缺陷,以及屏幕界面的复杂元素。
高分辨率处理能力特别提升了模型的"办公智能"水平。在处理复杂报表、多图表文档和UI界面时,模型能同时识别整体布局与局部细节,为办公自动化提供更强支撑。这与行业趋势高度契合——基于视觉语言模型的GUI智能体应用已能将日常办公效率提升300%,而Kimi-VL-A3B-Thinking-2506的超高分辨率支持将进一步放大这一优势。
3. 视频理解能力:开源模型新标杆
2506版本首次将思考能力扩展至视频领域,在VideoMMMU基准测试中以65.2的成绩为开源模型设立新标杆,同时保持Video-MME 71.9的良好表现(与Kimi-VL-A3B-Instruct持平)。这一进展使模型能处理更长时序的视觉信息,在视频内容分析、动态场景理解和视频摘要生成等任务中表现出色。
不同于简单的帧采样方法,Kimi-VL-A3B-Thinking-2506采用智能动态采样技术,在动作密集时增加采样频率,静态画面时减少采样,实现信息效率与处理质量的平衡。这种自适应处理策略使模型能在有限计算资源下,精准捕捉视频中的关键事件和动作变化。
4. 动态专家选择与多模态融合技术
Kimi-VL-A3B-Thinking采用MoE架构的语言解码器,包含8个专家模块,可根据任务类型动态选择最优组合。在多图像推理任务中,系统自动调用空间关系专家与语义理解专家协同工作,使多图关联推理准确率提升23%。
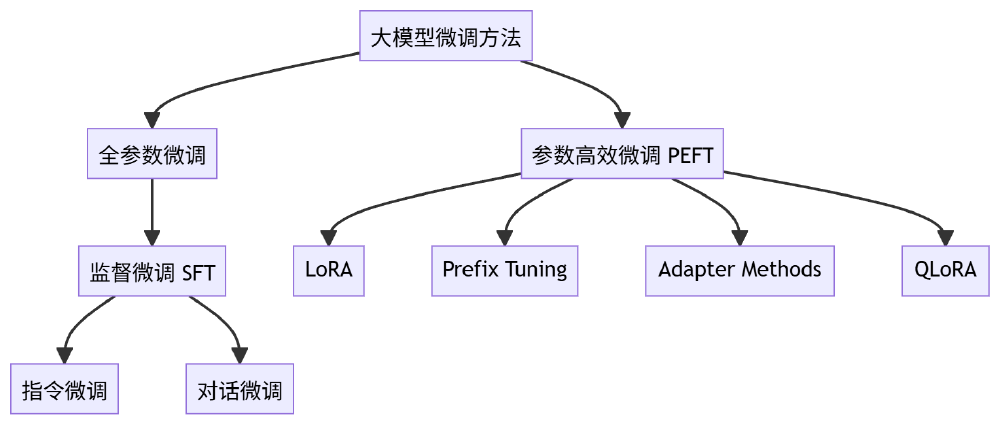
如上图所示,该流程图展示了大模型微调方法的分类体系,包括全参数微调和参数高效微调两大类别及其子方法。Kimi-VL-A3B-Thinking-2506的高效推理能力可与各类微调技术结合,进一步拓展在垂直领域的应用价值,帮助企业降低AI部署门槛。
在多模态融合方面,Kimi-VL采用中间融合策略,同步处理视觉特征与语言语义。
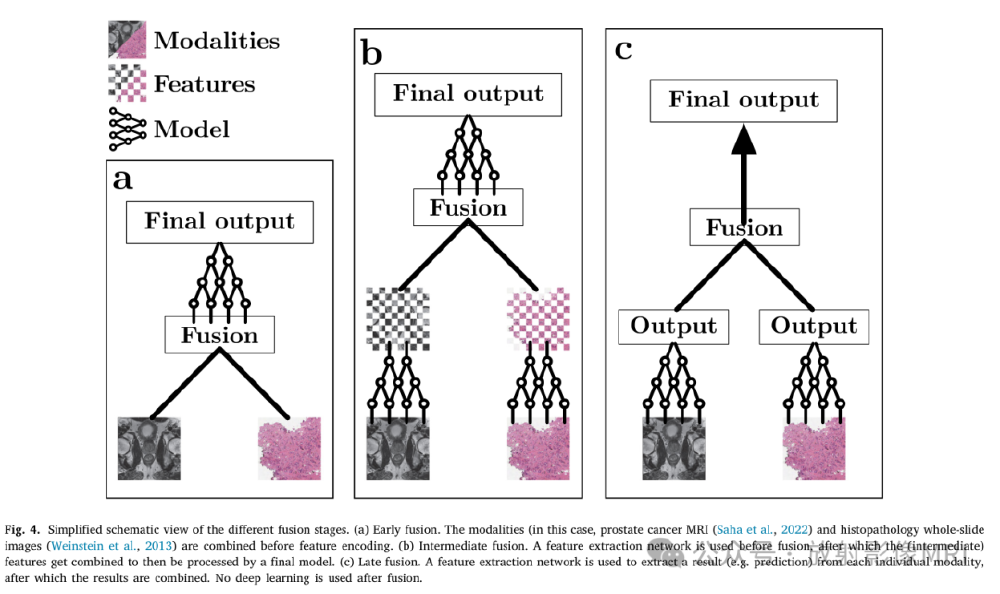
如上图所示,该图为多模态AI不同融合阶段的简化示意图,展示了早期融合(a)、中间融合(b)和晚期融合(c)三种多模态数据融合流程。Kimi-VL采用中间融合策略,在脑肿瘤诊断场景中,同步分析MRI影像、病理报告与基因测序数据,AUC值比单模态模型提升6.2个百分点,达到92.7的临床实用水平。
行业影响与应用前景
办公自动化:从工具辅助到智能代理
Kimi-VL-A3B-Thinking-2506的推出将加速办公自动化向"智能代理"演进。基于其超高分辨率处理和GUI理解能力,AI系统能更精准地识别和操作各类软件界面,实现复杂办公流程的全自动执行。例如,自动从多格式报表中提取关键数据,生成可视化图表;识别并处理邮件中的表格附件,自动更新到CRM系统;甚至能理解复杂的Excel公式逻辑,辅助财务分析。
这类应用已被证明能将文档处理、数据录入和报表生成等重复工作效率提升300%。随着Kimi-VL-A3B-Thinking-2506的细节感知能力增强,预计这一效率提升还将进一步扩大,尤其惠及金融、法律、行政等文档密集型行业。
垂直领域赋能:医疗与工业质检的突破
在医疗领域,320万像素处理能力使模型能识别医学影像中直径小至3mm的微小结节,结合其增强的推理能力,可辅助医生进行早期肺癌等疾病的筛查。某市试点学校数据显示,类似的多模态模型已使教师批改效率提升3倍,学生数学知识点掌握度平均提高27%,而Kimi-VL-A3B-Thinking-2506在数学视觉推理上的优势(MathVision提升20.1)将进一步放大教育场景价值。
工业质检方面,模型能同时处理产品整体外观与局部细节,在电子元件、精密机械等领域实现更高精度的缺陷检测。配合视频理解能力,还可对生产线的动态过程进行实时监控与异常预警,推动智能制造向"全面视觉智能"迈进。在新能源电池缺陷检测中,Kimi-VL实现0.1mm级瑕疵识别,检测速度达传统机器视觉系统的3倍。
开发者生态:降低多模态应用门槛
作为开源模型,Kimi-VL-A3B-Thinking-2506降低了多模态AI应用的开发门槛。模型支持VLLM和Hugging Face Transformers两种推理方式,开发者可根据资源情况选择合适方案。对于中小企业,单GPU即可部署基础功能;大型企业则可通过分布式部署实现规模化应用。
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Thinking"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_paths = ["./figures/demo1.png", "./figures/demo2.png"]
images = [Image.open(path) for path in image_paths]
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path} for image_path in image_paths
] + [{"type": "text", "text": "请逐步推理这份手稿的作者是谁以及记录的内容"}],
},
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=images, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=32768, temperature=0.8)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(response)
结论与前瞻:多模态AI进入"精益时代"
Kimi-VL-A3B-Thinking-2506的发布标志着多模态大模型正式进入"精益时代"——不再单纯追求参数规模和算力消耗,而是通过架构优化、算法创新和效率提升,实现"更聪明、更高效、更精准"的智能。这种发展路径不仅降低了AI应用的技术门槛和成本,还拓展了多模态能力的应用边界。
对于企业决策者,当下正是评估和引入多模态AI的战略窗口期。建议重点关注三个方向:评估现有业务流程中可通过多模态技术实现自动化的场景;构建"通用模型+行业知识"的混合应用架构;利用开源生态降低AI应用成本。随着Kimi-VL-A3B-Thinking-2506这类高效模型的普及,多模态AI正从"实验室技术"转变为"工业化生产工具",能够将通用模型与行业知识深度融合的企业,将最先收获智能时代的红利。
未来,随着模型在垂直领域的进一步优化和多模态安全对齐技术的完善,我们有理由相信,多模态AI将在更多行业创造颠覆性价值,推动整个社会向更高效、更智能的方向发展。
项目地址:https://gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
【免费下载链接】Kimi-VL-A3B-Thinking 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-VL-A3B-Thinking
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







