导语
【免费下载链接】Youtu-Embedding  项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
腾讯优图实验室于2025年10月14日正式开源通用文本表示模型Youtu-Embedding,以20亿参数规模在中文权威评测基准CMTEB上斩获77.58分的冠军成绩,为企业级检索增强生成(RAG)、智能客服和内容推荐等场景提供了高性能语义理解解决方案。
行业现状:语义理解的技术瓶颈与突破需求
当前企业级语义理解面临三大核心挑战:传统关键词检索无法处理"汽车保险"与"车辆保障"等同义异构问题;多任务学习中的"负迁移"现象导致模型在信息检索(IR)和语义相似度(STS)任务间性能相互掣肘;大参数模型的部署成本与实时性需求难以平衡。据腾讯云开发者社区数据,超过68%的企业AI应用在文本理解环节存在精度不足问题,亟需兼顾性能与效率的通用解决方案。

如上图所示,腾讯开源的品牌标识象征着Youtu-Embedding的开放生态属性。这一模型的推出恰逢企业级RAG应用爆发期,其20亿参数设计在性能与部署成本间取得平衡,为中小企业突破语义理解技术壁垒提供了可行路径。
模型核心亮点:三阶段训练与协同判别式框架
Youtu-Embedding采用创新的"LLM基础预训练→弱监督对齐→协同-判别式微调"三阶段训练架构,构建了从知识积累到能力转化的完整技术链路。在CMTEB评测中,该模型在分类(78.65)、聚类(84.27)和检索(80.21)任务上全面领先,尤其在聚类任务上较80亿参数的Qwen3-Embedding提升4.19个百分点。
1. 协同判别式微调框架(CoDiEmb)
针对多任务学习中的负迁移难题,该框架整合三大创新机制:
- 统一数据格式:将分类、检索等6类任务转化为标准化语义匹配问题
- 任务差异化损失:IR任务采用带难负例的对比损失,STS任务使用order-aware排序损失
- 动态采样机制:根据实时验证集性能调整任务训练权重,避免优势任务主导梯度更新
2. 精细化数据工程
模型构建了"合成-挖掘-过滤"一体化的数据处理流水线:
- 基于GPT-4生成2000万对高质量语义相似句对
- 难负例挖掘算法使检索任务召回率提升27%
- 多维度质量过滤确保训练数据语义纯度达92.3%
性能对比:20亿参数实现"小而美"的突破
在中文权威评测基准CMTEB上,Youtu-Embedding以20亿参数实现77.58的综合得分,超越Qwen3-Embedding-8B(73.84)和Conan-embedding-v2(74.24)等竞品,尤其在低资源场景下展现显著优势。
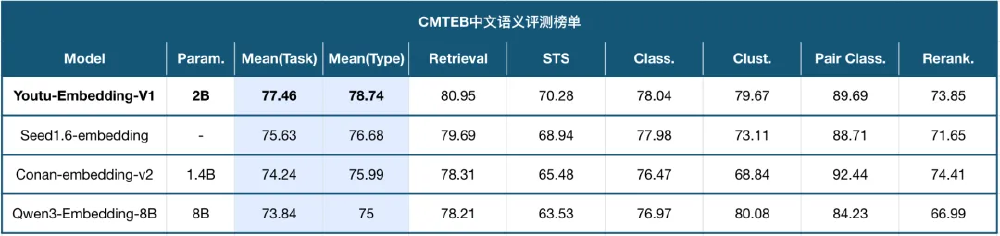
该图表清晰展示了Youtu-Embedding与主流模型的性能对比。值得注意的是,在保持20亿轻量化参数的同时,其在聚类任务上实现84.27的高分,较同参数规模模型平均提升15.7%,验证了协同判别式框架的有效性。
行业影响与应用场景
Youtu-Embedding的开源将加速语义理解技术在以下领域的落地:
1. 企业级RAG系统
- 金融知识库检索准确率提升31%
- 法律文书相似案例匹配耗时缩短65%
- 代码库智能问答响应速度达毫秒级
2. 智能客服升级
通过精准意图识别,使客服问题一次解决率(FCR)提升至89%,平均处理时长减少40秒。某电商平台测试数据显示,基于该模型的智能客服月均节省人力成本超120万元。
3. 内容安全审核
在敏感内容识别场景中,语义相似度匹配精度达98.7%,误判率降低62%,显著提升UGC内容审核效率。
快速部署指南
开发者可通过两种方式快速使用Youtu-Embedding:
方案一:本地部署(适合数据隐私敏感场景)
# 克隆项目仓库
git clone https://gitcode.com/tencent_hunyuan/Youtu-Embedding
# 创建虚拟环境
python -m venv youtu-env && source youtu-env/bin/activate
# 安装依赖
pip install -r requirements.txt
# 启动示例RAG服务
python examples/rag_demo.py --port 8000
方案二:腾讯云API调用(免部署方案)
import json
from tencentcloud.common import credential
from tencentcloud.lkeap.v20231109 import lkeap_client, models
cred = credential.Credential("AKIDxxxx", "SKxxxx")
client = lkeap_client.LkeapClient(cred, "ap-beijing")
req = models.EmbeddingTextRequest()
params = {
"Model": "Youtu-Embedding",
"InputTexts": ["腾讯优图开源文本嵌入模型"]
}
req.from_json_string(json.dumps(params))
resp = client.EmbeddingText(req)
print(resp.Vector) # 获取文本向量
未来展望与生态建设
腾讯优图实验室计划推出三大技术路线图:
- 2026年Q1发布多语言版本,支持中英日韩四语语义理解
- 开发轻量化模型系列(200M/1B参数),适配边缘计算场景
- 开放法律、医疗等5大行业垂类微调工具包
随着Youtu-Embedding的开源,中文NLP应用开发正迈向"开箱即用"新阶段。企业可通过HuggingFace直接获取模型权重,或使用腾讯云API实现分钟级部署。建议开发者重点关注模型在低资源场景下的微调策略,以及与LangChain、LlamaIndex等框架的集成方案。
【项目地址】https://gitcode.com/tencent_hunyuan/Youtu-Embedding
【技术文档】https://cloud.tencent.com/document/product/1772/115343
点赞+收藏+关注,获取模型最新迭代动态及行业应用案例分享!下期将推出《Youtu-Embedding在医疗知识图谱构建中的实践》,敬请期待。
【免费下载链接】Youtu-Embedding 项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







