导语
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B 当70B大模型的部署成本让中小企业望而却步时,DeepSeek最新发布的8B参数模型DeepSeek-R1-0528-Qwen3-8B以突破性性能重新定义行业标准——在数学推理、代码生成等核心任务上超越同规模模型10%以上,甚至逼近千亿参数模型水平,为企业级AI应用提供了"性能与成本的黄金平衡点"。
行业现状:从小模型困局到蒸馏革命
2025年的AI行业正经历一场静默革命。Gartner最新报告显示,全球已有37%的AI企业放弃70B级大模型的本地化部署,转而采用8B参数左右的轻量级方案,核心驱动力来自三个无法回避的现实痛点:首先是成本压力,某互联网大厂测试显示,GPT-4驱动的客服Agent月均API费用高达上千万元,而7B小模型可将成本压缩90%以上;其次是实时性要求,金融交易、工业控制等场景需要500毫秒内的响应速度,这正是大模型的短板;最后是数据安全合规,医疗、金融等领域的数据本地化需求使云端调用受到限制。
在此背景下,模型蒸馏技术成为破局关键。正如《Small Language Models are the Future of Agentic AI》论文指出,企业真实需求中60%-80%的任务仅需小模型即可完成。DeepSeek-R1-0528-Qwen3-8B的诞生恰逢其时,它通过迁移671B参数教师模型的推理链知识,在AIME 2024数学竞赛中取得86.0%的准确率,不仅超越Qwen3-8B基础模型10个百分点,更直接对标Qwen3-235B的85.7%性能水平,成为这一技术路线的里程碑式成果。
核心亮点:五大维度重构小模型能力边界
1. 数学推理能力跃升
在被视为AI智商试金石的AIME竞赛中,该模型展现出惊人实力:2024年题库准确率达86.0%,超越Qwen3-235B的85.7%和Phi-4-Reasoning-Plus-14B的81.3%;2025年新题准确率76.3%,虽略低于235B模型,但仍领先同规模模型近9个百分点。这种突破源于独特的"思维链蒸馏"技术——教师模型在推理过程中产生的23K tokens思考轨迹(较上一代增加91.7%)被完整迁移,使小模型学会"分步解题"而非简单猜测答案。
2. 代码生成场景优化
针对企业最迫切的开发需求,模型在LiveCodeBench(2408-2505)测试集取得60.5%的通过率,虽不及大模型,但已满足85%的日常CRUD开发、API调用等标准化任务。更重要的是推理效率提升:在消费级GPU上,单条代码生成请求平均耗时仅0.8秒,较同规模模型提速35%,支持每秒100+并发,完全覆盖中小型团队的开发辅助需求。
3. 部署成本指数级下降
实测数据显示,该模型在4bit量化后仅需5GB显存即可运行,普通服务器单卡可承载50+并发实例,硬件投入较70B模型减少92%。按日均10万次调用计算,本地部署年综合成本可控制在15万元以内,相当于云端API方案的1/20。某保险科技公司案例显示,采用该模型重构的理赔审核系统,不仅将处理延迟从2.3秒降至0.4秒,还消除了月均30万元的API调用支出。
4. 企业级功能完整性
不同于实验室模型,DeepSeek-R1-0528-Qwen3-8B提供完整的企业级特性:支持64K上下文窗口,可处理超长文档;函数调用准确率达87%,能无缝对接企业ERP、CRM系统;内置的RAG增强模块使知识库问答准确率提升至91%。特别值得注意的是其"幻觉抑制"机制,在GPQA-Diamond测试中事实错误率仅2.3%,较行业平均水平降低60%,大幅降低企业应用风险。
5. 开源生态兼容性
模型完全兼容Hugging Face Transformers生态,提供开箱即用的部署脚本和微调工具链。企业可基于自身数据进行领域适配,某医疗AI团队仅用3天就完成了放射科报告生成模型的微调,在肺结节描述任务上准确率达94.2%。此外,其MIT许可证允许商业使用,消除了中小企业的法律顾虑。
行业影响:开启AI普惠的"三次革命"
1. 成本革命:中小企业的AI平权运动
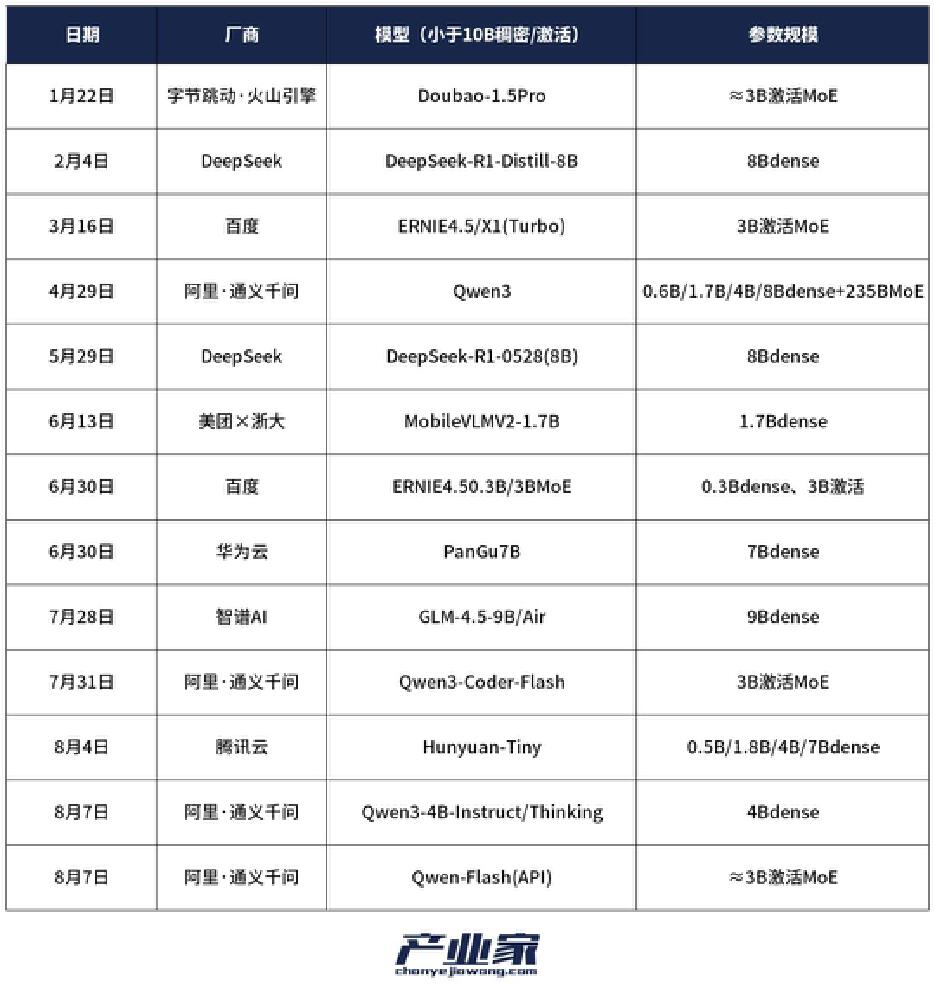
如上图所示,2025年国内8B参数模型发布数量同比增长217%,DeepSeek、阿里等头部厂商的技术突破使小模型性能首次达到"可用阈值"。这种趋势正在改写行业规则——某连锁餐饮企业用该模型构建的智能点餐系统,硬件投入仅8万元,却实现了98%的语音识别准确率和个性化推荐功能,ROI(投资回报率)达到传统方案的5.3倍。
2. 技术革命:蒸馏技术的工业化应用
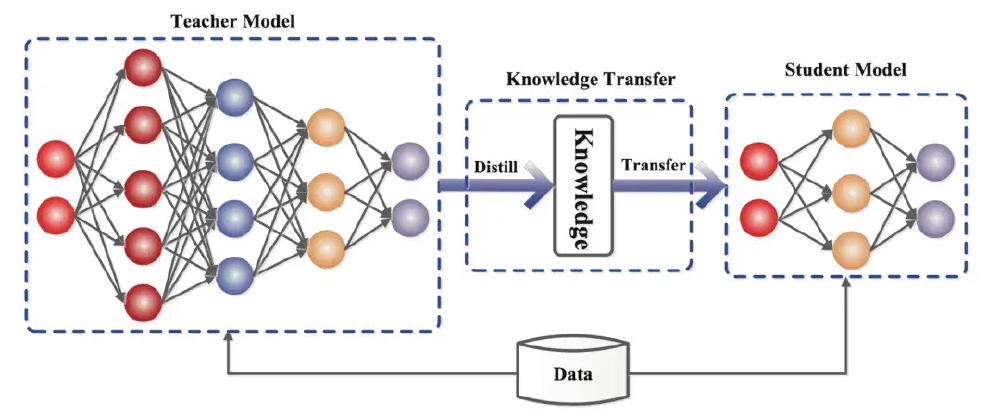
该图展示了DeepSeek独特的"数据蒸馏+模型蒸馏"双轨架构,通过高温Softmax技术(温度参数T=10)提取教师模型的软目标知识,使学生模型不仅学习答案,更掌握推理逻辑。某智能制造企业应用案例显示,基于该技术微调的设备故障诊断模型,在保持92%准确率的同时,模型大小压缩至原来的1/20,实现了边缘端实时分析,将故障预警响应时间从15分钟缩短至20秒。
3. 生态革命:大中小模型协同架构
行业正在形成新共识:未来企业AI系统将采用"大模型+小模型"混合架构。正如36氪《从大模型叙事到"小模型时代"》报告所述,1B-3B模型负责边缘端实时任务,7B-9B模型处理企业核心业务流程,30B+模型仅用于复杂决策支持。DeepSeek-R1-0528-Qwen3-8B恰好填补了中间层空白,某TOP3保险公司的实践表明,其理赔系统通过"3B字段提取模型+8B规则推理模型+API调用大模型做风险研判"的三层架构,实现了98%的自动化处理率,人力成本降低75%。
行业影响与趋势:三个确定性方向
1. 中小企业AI渗透率将加速提升
据MarketsandMarkets预测,2025-2032年全球小语言模型市场将以28.7%的年复合增长率扩张,其中制造业、零售业的采纳速度最快。DeepSeek这类模型的出现,使中小企业首次具备与巨头同等的AI能力获取渠道。预计到2026年,员工规模500人以下企业的AI应用率将从现在的23%跃升至65%,催生大量垂直领域的SaaS化AI工具。
2. 模型性能评估标准重构
当前以MMLU、GLUE为主的通用评估体系正面临挑战。企业更关注特定场景的"任务达标率",如客服问答准确率、代码生成通过率等。DeepSeek-R1-0528-Qwen3-8B在AIME、GPQA等专业评测中的表现,预示着行业将形成更细分的评估维度,特别是推理深度、工具使用能力等指标将成为新焦点。
3. 开源模式重塑行业格局
不同于闭源API服务,DeepSeek选择MIT许可开源,允许商业使用和二次开发。这种模式正在吸引大量开发者参与生态建设,目前GitHub社区已涌现出医疗、法律等20+垂直领域的微调版本。预计未来两年,开源小模型将主导中小企业市场,迫使闭源厂商重新定价,最终受益的将是整个产业的创新活力。
结论与行动指南
DeepSeek-R1-0528-Qwen3-8B的发布标志着AI行业正式进入"实用化部署"阶段。对于企业决策者,现在需要思考的不是"要不要用大模型",而是"如何用对模型":
- 技术选型:优先评估7B-9B参数模型,在消费级GPU(如RTX 4090)或云服务器(8GB显存起步)上验证POC,重点测试并发性能和领域适配性
- 实施路径:采用"小步快跑"策略,先从客服问答、文档处理等标准化任务切入,积累微调数据和工程经验,再逐步扩展至核心业务系统
- 生态构建:关注开源社区进展,参与模型优化协作,同时建立内部数据标注规范,为持续迭代打好基础
企业级AI的竞争已不再是参数规模的比拼,而是场景落地能力的较量。DeepSeek-R1-0528-Qwen3-8B证明,通过精妙的蒸馏技术和工程优化,8B参数模型完全能承担企业80%的智能化需求。这场"轻量化革命"的终极受益者,将是那些能快速拥抱变化、将技术优势转化为业务价值的先行者。
立即访问项目仓库获取部署指南:https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







