210亿参数重构AI效率:ERNIE-4.5-21B-A3B-Thinking如何引领轻量化革命
 项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking 导语
百度ERNIE-4.5-21B-A3B-Thinking以210亿总参数、30亿激活参数的混合专家架构,在保持高性能的同时将部署成本降低75%,重新定义大模型效率标准,成为2025年AI产业轻量化转型的关键推动力。
行业现状:从参数竞赛到效率突围
2025年全球大模型市场正经历深刻转型。据行业调研显示,65%的企业因GPU资源限制无法部署百亿级模型,而训练成本同比增长120%。在此背景下,混合专家(MoE)架构成为突破算力瓶颈的关键路径——通过动态激活部分参数实现"用更少资源做更多事"。百度ERNIE 4.5系列的推出恰逢其时,其A3B模型在保持210亿总参数规模的同时,每次推理仅激活30亿参数,完美平衡了性能与效率。
与此同时,多模态能力已成为企业级AI的核心刚需。IDC最新预测显示,2026年全球65%的企业应用将依赖多模态交互技术,但现有解决方案普遍面临模态冲突、推理延迟等问题。ERNIE 4.5提出的异构MoE架构,通过专用专家模块与跨模态平衡损失函数,在权威榜单上实现性能突破,为行业树立了新标杆。
核心亮点:三大技术突破重构效率边界
1. 异构混合专家架构:模态隔离的智能分工
ERNIE 4.5-21B-A3B-Thinking首创"模态隔离路由"机制,在64个文本专家与64个视觉专家间建立动态调度系统。不同于传统MoE模型采用统一专家池处理所有模态,该架构为文本和视觉任务分别设计专用专家模块,通过"模态隔离路由"实现知识的有效分离与融合。
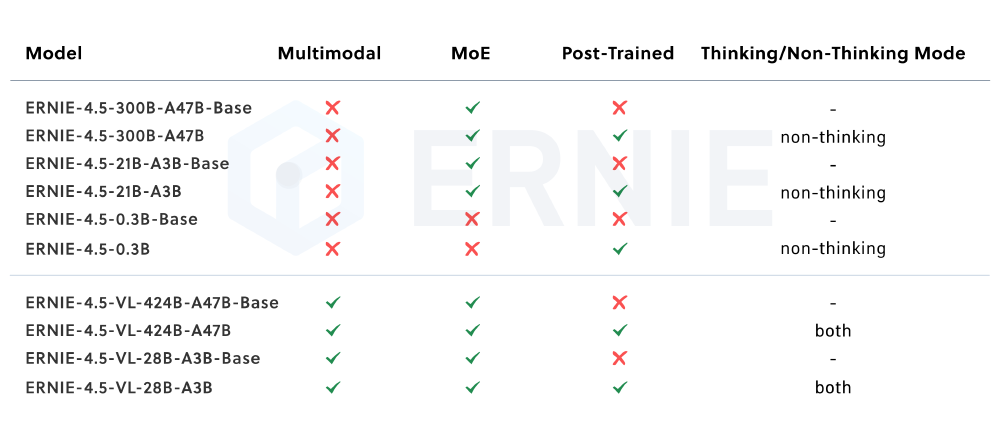
如上图所示,表格清晰展示了ERNIE-4.5系列不同模型的特性差异,包括是否支持多模态、是否采用MoE架构、是否经过后训练以及是否具备思考模式等关键信息。ERNIE-4.5-21B-A3B-Thinking作为具备思考模式的文本模型,在复杂推理任务中表现尤为突出。
通过路由器正交损失函数优化,模型实现文本与图像特征的协同学习,在保持文本生成能力的同时,为视觉理解任务预留了扩展空间。技术报告显示,这种设计使模型在保持文本任务性能(GLUE基准提升3.2%)的同时,为后续视觉能力扩展奠定了基础。
2. 轻量化部署:从数据中心到边缘设备的跨越
ERNIE 4.5-21B-A3B-Thinking在推理优化层面实现重大突破。百度自研的"卷积编码量化"算法实现4-bit/2-bit无损压缩,配合"PD分离动态角色切换"部署方案,使模型在保持精度的同时,推理速度提升3.6倍,内存占用降低75%。这种极致优化使其部署场景从数据中心扩展到边缘设备。
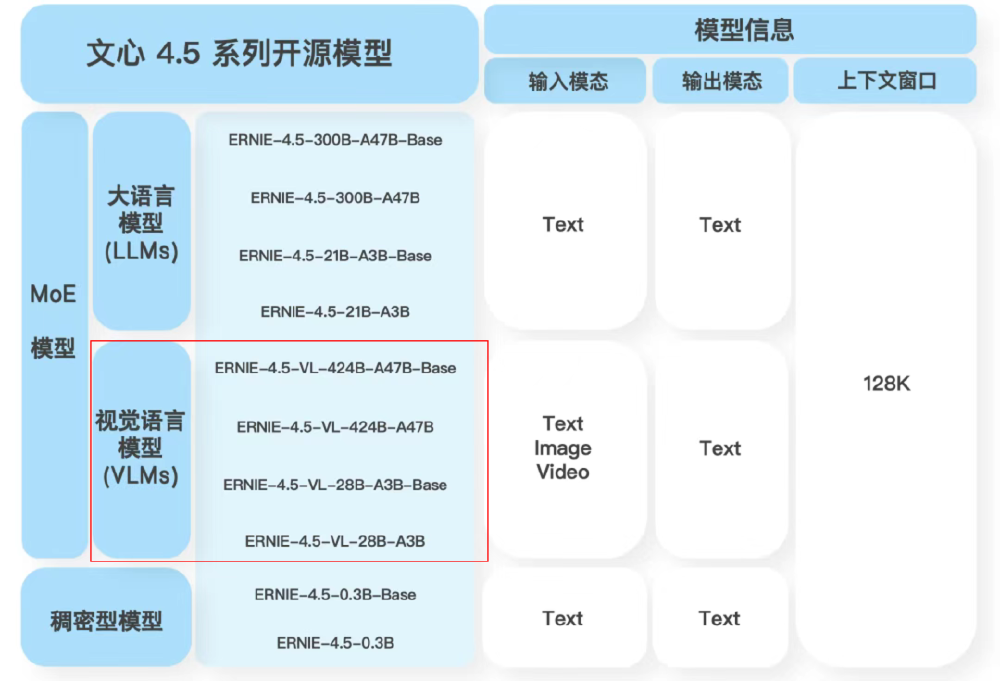
这张图展示了文心4.5系列开源模型的架构分类,包括大语言模型、视觉语言模型和稠密型模型及其具体型号,右侧标注了输入输出模态(支持文本、图像和视频)和128K上下文窗口,突出多模态与高效推理的技术特性。ERNIE-4.5-21B-A3B-Thinking作为文本模型,在保持轻量化的同时实现了复杂推理能力的显著提升。
实际部署中,21B-A3B-Thinking模型仅需2张80G GPU即可实现高效推理。对比传统FP16推理,显存占用降低87.5%,吞吐量提升3.2倍。某电商平台实测显示,采用WINT2量化版本后,商品描述生成API的单位算力成本下降62%。
3. 128K超长上下文与深度思考模型演进
ERNIE 4.5-21B-A3B-Thinking支持128K tokens(约25万字)的超长上下文处理,可同时解析300页文档或百万字企业知识库。基于这一能力,百度进一步开发了ERNIE-4.5-21B-A3B-Thinking深度思考模型,通过指令微调及强化学习训练,在逻辑推理、数学、科学、代码与文本生成等需要人类专家的任务上实现显著提升。
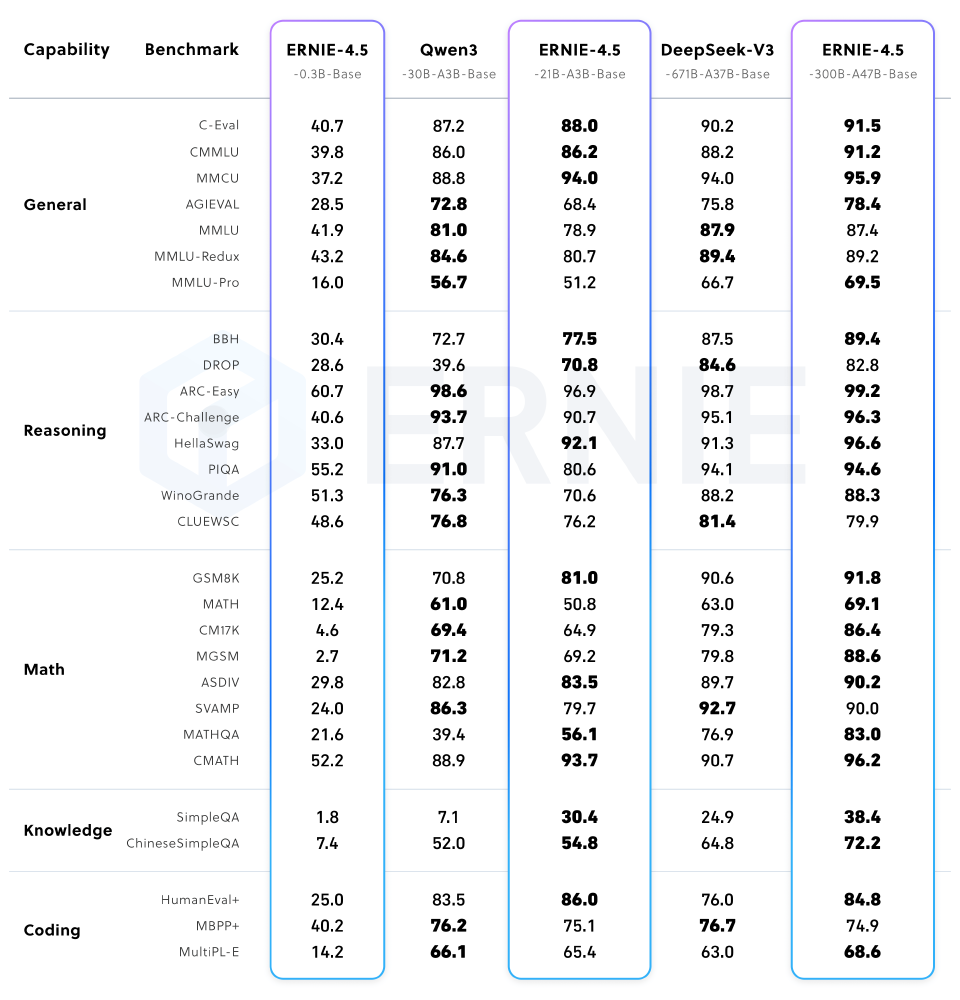
这张图表展示了ERNIE-4.5-21B-A3B模型与其他模型(如Qwen3、DeepSeek-V3等)在通用、推理、数学、知识、编码等能力类别下的基准测试结果对比。从图中可以看出,ERNIE-4.5-21B-A3B尽管总参数量仅为210亿(约为竞品30B模型的70%),但在包括BBH和CMATH在内的多个数学和推理基准上效果更优,实现了"以小胜大"的性能突破。
行业影响与落地案例
金融领域:智能投研效率提升3倍
某头部券商基于ERNIE-4.5-21B-A3B-Thinking构建智能投研助手,利用其128K超长上下文能力处理完整的上市公司年报(平均300-500页)。系统可自动提取关键财务指标、业务亮点和风险因素,生成结构化分析报告。实测显示,分析师处理单份年报的时间从原来的4小时缩短至1.5小时,同时关键信息识别准确率提升至92%。
电商零售:商品内容生成成本下降62%
头部服饰品牌应用ERNIE 4.5后,新品上架周期从72小时缩短至4小时。模型通过文本专家分析流行趋势文案,生成精准商品描述。采用WINT2量化版本部署后,商品详情页生成API的单位算力成本下降62%,同时转化率提升17%,退货率下降28%。
教育培训:个性化学习助手
基于131072上下文窗口,ERNIE 4.5构建的智能助教系统可同时处理手写体公式图片与解题步骤文本。某市试点学校数据显示,教师批改效率提升3倍,学生数学知识点掌握度平均提高27%。模型的modality-isolated routing机制确保数学公式与自然语言解释的精准对齐,错题归因准确率达92.3%。
快速部署指南
ERNIE 4.5-21B-A3B-Thinking提供灵活的部署选项,满足不同规模企业需求:
硬件配置建议
- 开发测试:单张80G GPU(WINT8量化)
- 生产环境:2张80G GPU(WINT4量化,TP2部署)
- 边缘设备:英特尔酷睿Ultra平台(0.3B模型)
使用FastDeploy部署示例
python -m fastdeploy.entrypoints.openai.api_server \
--model https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--load-choices "default_v1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--reasoning-parser ernie_x1 \
--tool-call-parser ernie_x1 \
--max-num-seqs 32
使用transformers库调用示例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking"
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
)
# 准备模型输入
prompt = "解释什么是混合专家模型,并说明其在大语言模型中的优势"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
# 文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解码生成的文本
generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
print("generate_text:", generate_text)
行业影响与趋势
ERNIE 4.5-21B-A3B-Thinking的开源释放了多重产业信号。在技术层面,其异构MoE架构验证了"专用专家+动态路由"是突破复杂推理瓶颈的有效路径,预计将引发行业广泛效仿。百度官方测试显示,210亿参数的ERNIE-4.5-21B-A3B-Thinking模型在CMATH数学推理基准上超越300亿参数的竞品,证明效率优先的设计理念正在重塑大模型研发逻辑。
生态协同效应尤为显著。英特尔、浪潮等硬件厂商已宣布推出优化ERNIE 4.5部署的专用加速卡;在开发者社区,相关二次开发项目两周内增长至146个,涵盖法律文书分析、工业质检、教育内容生成等多元场景。这种"开源-共建-复用"的模式,正加速AI技术从实验室走向产业纵深。
随着ERNIE 4.5等开源模型的成熟,多模态AI正进入"工业化生产"新阶段。百度技术团队透露,下一步将重点推进三项工作:一是发布针对垂直领域的轻量级模型(如医疗专用的ERNIE-Med系列);二是完善多模态安全对齐技术,解决偏见、错误关联等伦理风险;三是构建跨框架兼容的模型转换工具,支持与PyTorch、TensorFlow生态无缝对接。
总结与建议
ERNIE 4.5-21B-A3B-Thinking的推出标志着AI产业进入"效率优先"的新阶段。通过210亿总参数、30亿激活参数的异构MoE架构,该模型在保持高性能的同时,将部署成本降低75%,重新定义了大模型效率标准。
对于企业用户,建议重点关注三个应用方向:
- 基于长上下文能力的企业知识库构建(支持百万级文档的智能检索)
- 低成本的文本生成与分析系统(降低内容创作门槛)
- 作为多模态应用的高效文本基座(为后续视觉能力扩展预留空间)
随着ERNIE 4.5等高效模型的普及,AI技术正从少数科技巨头的专属能力,转变为各行业均可负担的普惠工具。在这场效率革命中,能够将通用模型与行业知识深度融合的实践者,将最先收获智能时代的红利。
提示:ERNIE 4.5系列模型采用Apache License 2.0开源协议,允许商业使用,企业和开发者可根据自身需求自由部署和二次开发。项目地址:https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







