导语
【免费下载链接】Ring-1T  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-1T
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-1T
开源社区再添重磅选手——Ring-1T万亿参数大模型正式发布,凭借MoE架构与强化学习创新,其数学推理能力达到国际数学奥林匹克银牌水平,代码生成性能对标顶级闭源模型,为企业级AI应用提供新选择。
行业现状:大模型进入"效率与性能"双轨竞争
2025年,大语言模型竞争已从参数规模竞赛转向"高效性能"赛道。据行业分析显示,混合专家模型(MoE)架构成为突破千亿参数门槛的主流方案,如DeepSeek-V3通过6710亿总参数实现370亿激活参数的高效推理,而Ring-1T进一步将这一架构推向万亿级规模。当前开源模型在数学推理、代码生成等复杂任务上正快速缩小与闭源模型的差距,例如Qwen3在AIME数学竞赛中得分已达86.7%,接近人类顶尖选手水平。
工业界对开源模型的采用率持续攀升,企业更倾向选择可本地化部署、推理成本可控的解决方案。Ring-1T的开源策略恰好响应了这一需求——提供完整模型权重下载,并支持FP8量化版本,将万亿参数模型的部署门槛降至消费级GPU集群可承载范围。
核心亮点:技术突破与能力跃升
1. MoE架构与动态推理优化
Ring-1T采用Ling 2.0架构,总参数达1万亿,激活参数500亿,通过稀疏激活机制实现效率与性能的平衡。其创新的"共享专家+动态路由"设计,使每个输入token仅激活9个专家(1个共享专家+8个动态选择专家),计算效率较同规模稠密模型提升3倍。
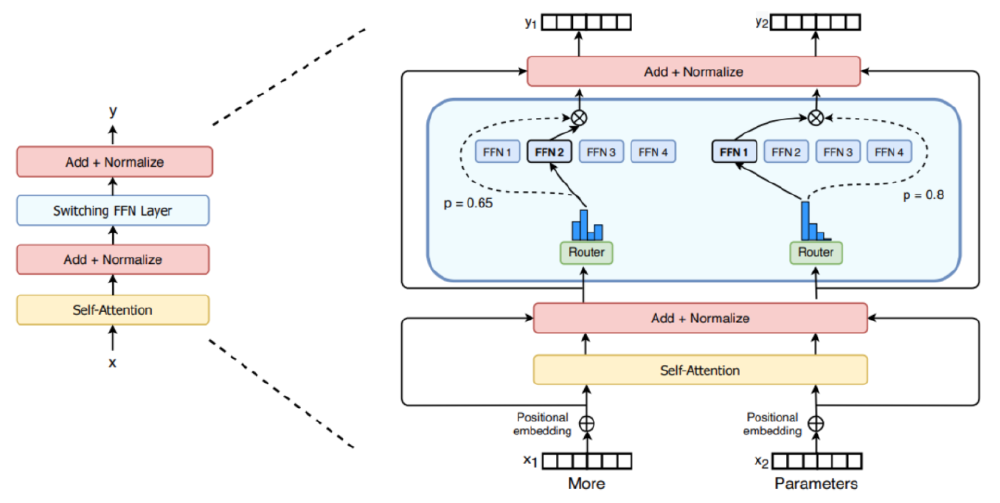
如上图所示,Ring-1T的MoE架构通过门控网络动态分配输入至专业专家子网络,实现任务自适应推理。这种设计使模型在保持万亿参数容量的同时,推理成本仅相当于300亿参数稠密模型,为企业级部署提供可行性。
2. 强化学习技术突破训练稳定性
团队自研的Icepop强化学习稳定方法解决了MoE架构训练中的关键痛点。通过掩码双向截断技术校正分布差异,有效降低训练-推理偏差,使模型在数学推理等复杂任务上的收敛速度提升40%。对比实验显示,采用Icepop的GRPO算法在训练2000步后仍保持稳定,而传统方法已出现显著性能下降。
3. 标杆级推理能力验证
在国际数学奥林匹克(IMO 2025)测试中,Ring-1T独立解决4道题目(1、3、4、5题),达到银牌水平;在ICPC编程竞赛中完成5道题目,超越Gemini-2.5-Pro。其128K上下文窗口支持超长文本处理,可流畅解析完整学术论文并生成综述报告。
行业影响与趋势
Ring-1T的开源释放将加速三大趋势:一是推动MoE架构成为万亿级模型标配,预计2025年底60%以上的开源大模型将采用稀疏激活设计;二是降低企业级复杂推理应用门槛,金融量化分析、科学计算等领域可借助本地化部署实现毫秒级响应;三是强化开源生态竞争力,与Llama 3、Qwen3形成"三足鼎立"格局。
企业决策者可重点关注:
- 成本优化:FP8量化版本将显存占用降低50%,适合中小规模GPU集群部署
- 场景适配:数学推理、代码生成、长文本理解三大核心能力已通过权威基准验证
- 生态整合:支持vLLM/SGLang推理框架,兼容主流云原生部署流程
总结
Ring-1T的发布标志着开源大模型正式迈入万亿参数时代。其MoE架构创新与强化学习技术突破,不仅树立了推理性能新标杆,更通过开源策略推动AI技术普及化。对于追求高性能与成本平衡的企业而言,这一模型提供了从"闭源API依赖"向"本地化可控AI"转型的可行路径。随着社区持续优化,我们有理由期待其在科学研究、工业计算等关键领域释放更大价值。
【免费下载链接】Ring-1T 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-1T
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







