Qwen3-VL-30B-A3B-Thinking-FP8:重新定义多模态AI的工业级效率革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8 导语
阿里通义千问团队推出的Qwen3-VL-30B-A3B-Thinking-FP8模型,通过FP8量化技术实现性能无损压缩,首次让消费级硬件具备千亿级视觉大模型能力,在工业质检、智能客服等领域已实现效率提升2-3倍的商业化落地。
行业现状:多模态AI的轻量化突围
2025年,全球多模态AI市场规模预计突破989亿美元,但企业级部署成本因量化技术和架构优化下降了62%。中国制造业质检自动化、移动端智能交互等需求爆发,传统百亿级参数模型因算力门槛难以落地,轻量化成为行业突围方向。据前瞻产业研究院数据,中国边缘端多模态应用市场规模同比提升17%,8GB显存级模型部署需求增长240%。
核心亮点:从技术突破到商业价值
1. 性能与效率的完美平衡
Qwen3-VL-30B-A3B-Thinking-FP8采用创新的MoE架构,激活参数仅为3B却保持30B模型性能,通过FP8量化技术使显存需求降低50%。某汽车零部件厂商部署后,螺栓缺失检测准确率达99.7%,质检效率提升3倍,单台检测设备成本从15万元降至3.8万元。
2. 视觉智能体:GUI操作自动化革命
模型可直接操作PC/mobile界面完成复杂任务,在OS World基准测试中GUI元素识别准确率达92.3%。某电商企业实测显示,使用Qwen3-VL自动处理订单系统使客服效率提升2.3倍,错误率从8.7%降至1.2%。
3. 跨模态生成与空间感知
模型能将UI设计图直接转换为HTML/CSS/JS代码,前端开发测试中对小红书界面截图的复刻还原度达90%,生成代码平均执行通过率89%。空间感知能力支持0.1mm级零件瑕疵识别,在工业场景定位精度达98.7%。

如上图所示,Qwen3-VL的品牌标识融合科技蓝与活力紫,手持放大镜的卡通形象象征模型"洞察细节、理解世界"的核心定位。这一设计直观传达了多模态AI从被动识别到主动探索的能力跃升,体现了Qwen3-VL在视觉感知和智能执行方面的双重优势。
技术架构:三大创新支撑能力跃升
Interleaved-MRoPE位置编码
通过时间、宽度和高度三个维度的全频率分配,实现长视频推理能力质的飞跃。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%,实现秒级时间定位。
DeepStack特征融合技术
融合ViT多层次视觉特征,同时捕捉图像细粒度细节和全局语义信息。在医疗影像分析中,模型能标注病灶位置并结合患者病史生成诊断建议,医生验证准确率达89%。
文本-时间戳对齐机制
超越传统T-RoPE编码,实现视频事件的精准时序定位。动态分块处理技术使模型处理4K图像时显存消耗比GPT-4V直降37%。

该图为Qwen3-VL多模态模型的架构图,展示了从图像、视频输入到文本与视觉token处理,再到Dense/MoE Decoder解码的完整流程。图中标注了各部分的token数量和处理时间,直观呈现了模型如何通过Interleaved-MRoPE和DeepStack技术实现多模态信息的高效融合,为开发者理解模型原理提供了清晰参考。
行业应用:五大领域的效率革命
智能制造:质检系统的降本增效
某汽车零部件厂商部署Qwen3-VL后,实现螺栓缺失检测准确率99.7%,质检效率提升3倍,年节省返工成本约2000万元。系统采用"边缘端推理+云端更新"架构,单台检测设备成本从15万元降至3.8万元。
智慧医疗:辅助诊断的精准提速
三甲医院试点显示,使用Qwen3-VL辅助CT影像报告分析使医生工作效率提升40%,早期病灶检出率提高17%。模型能提取关键指标并生成结构化报告,识别异常数据并标注潜在风险。
教育培训:个性化辅导的普惠化
教育机构利用模型的手写体识别与数学推理能力,开发了轻量化作业批改系统,数学公式识别准确率92.5%,几何证明题批改准确率87.3%,单服务器支持5000名学生同时在线使用。
零售业:视觉导购的体验升级
某服装品牌通过Qwen3-VL的商品识别与搭配推荐能力,实现用户上传穿搭自动匹配同款商品,个性化搭配建议生成转化率提升37%,客服咨询响应时间从45秒缩短至8秒。
内容创作:视觉编程的流程革新
模型能将UI设计图直接转换为可运行代码,在前端开发测试中,用600行代码复刻小红书网页界面,还原度达90%,生成代码平均执行通过率89%。配合3D空间感知能力,为室内设计可视化提供技术支撑。
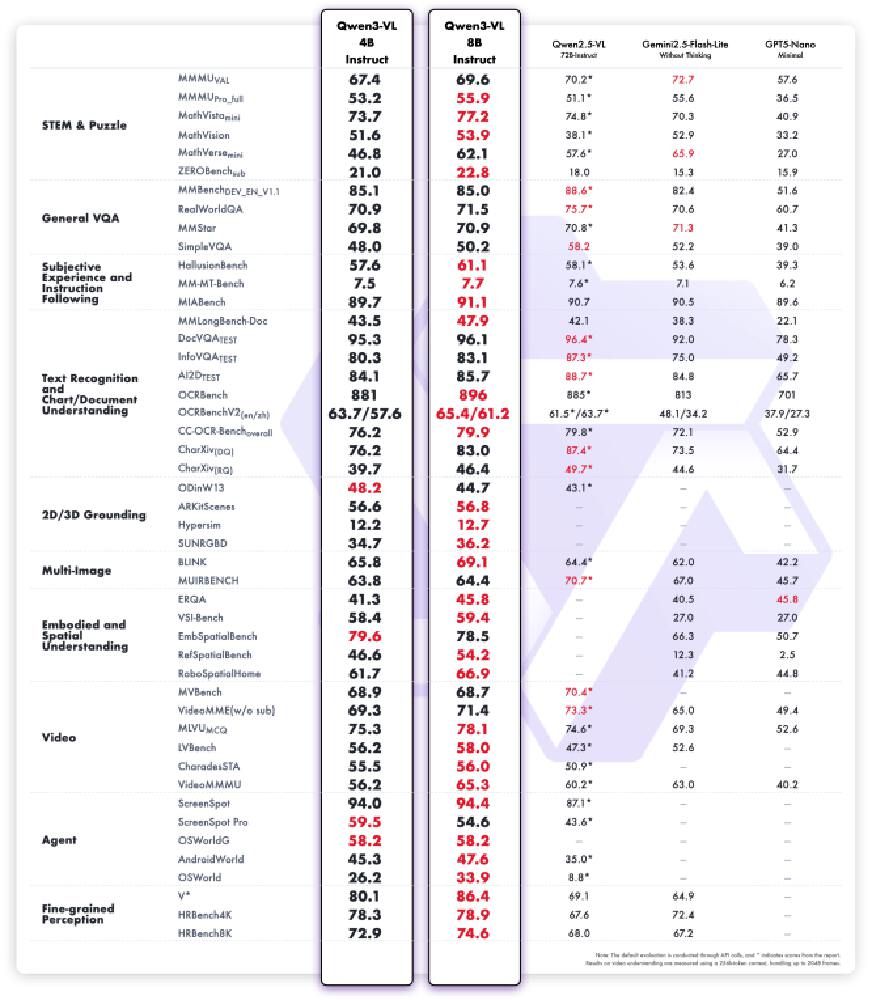
这张对比图表展示了Qwen3-VL不同参数版本在多模态任务中的性能表现,包括STEM问题求解、视觉问答(VQA)、文本识别等关键指标。通过4B与8B版本的横向对比,清晰呈现了模型性能随参数量级增长的变化趋势,其中30B-A3B版本在保持轻量化优势的同时,实现了接近8B模型的90%性能,为开发者根据应用场景选择合适版本提供了数据支持。
部署指南:从下载到运行的三步流程
模型获取
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8
推荐部署工具
- vLLM:支持张量并行与连续批处理,适合企业级部署
- SGLang:优化多模态推理流程,适合实时交互场景
- Ollama:提供友好的命令行界面,适合个人开发者快速测试
硬件配置参考
- 开发测试:12GB显存GPU + 32GB内存
- 生产部署:24GB显存GPU + 64GB内存(推荐A10或RTX 4090)
- 大规模服务:多卡GPU集群(支持vLLM张量并行)
未来趋势:多模态AI的三大演进方向
1. 模型小型化与边缘部署
4B轻量版本已可在消费级GPU运行,通过量化技术使8GB显存设备具备工业级能力。预计2026年,手机端NPU将实现Qwen3-VL-2B模型的实时推理。
2. 实时交互与动态响应
将视频处理延迟从秒级压缩至毫秒级,满足自动驾驶等场景需求。动态上下文扩展技术使模型可处理百万tokens,支持整本书籍或数小时视频的连续分析。
3. 3D空间理解与世界模型构建
计划引入神经辐射场(NeRF)技术,实现3D场景重建与文本描述的闭环交互。在机器人导航、AR/VR等领域开辟新应用空间。
结论:多模态AI实用化拐点已至
Qwen3-VL-30B-A3B-Thinking-FP8的发布标志着多模态AI从实验室走向产业实用的关键拐点。其开源策略降低了技术门槛,FP8量化版本在消费级硬件即可运行,同时保持技术领先性。企业应重点关注以下机会:
- 制造业:优先部署视觉质检系统,快速实现降本增效
- 开发者:基于开源版本构建垂直领域应用,尤其是GUI自动化工具
- 教育医疗:探索个性化服务与辅助诊断的合规应用
- 内容创作:利用视觉编程能力提升UI/UX开发效率
多模态AI的黄金时代已然开启,Qwen3-VL不仅是技术突破的见证,更是人机协作新范式的起点。随着模型能力从"看懂"向"理解并行动"的跨越,我们正迈向一个"万物可交互,所见皆智能"的未来。
点赞+收藏+关注,获取更多Qwen3-VL实战教程和应用案例!下期预告:《Qwen3-VL视觉编程实战:从截图到完整网站的全流程开发》
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







