4-bit量化革命:Nunchaku FLUX.1让消费级GPU实现专业级AI绘图
 项目地址: https://ai.gitcode.com/hf_mirrors/nunchaku-tech/nunchaku-flux.1-krea-dev
项目地址: https://ai.gitcode.com/hf_mirrors/nunchaku-tech/nunchaku-flux.1-krea-dev 导语
Nunchaku团队推出基于SVDQuant技术的4-bit量化版FLUX.1-Krea-dev模型,在保持图像生成质量的同时,将显存占用降低50%,推理速度提升30%,首次实现高端文生图模型在消费级硬件的流畅运行。
行业现状:大模型落地的硬件门槛困局
当前顶级文生图模型如FLUX.1-Krea-dev虽能生成电影级画质,但12B参数规模需24GB以上显存才能流畅运行。据行业调研,超过60%的创作者因硬件限制无法体验最新模型。此前8-bit量化方案虽能降低显存占用,但生成速度仍不理想,而4-bit量化常导致图像细节丢失或"AI味"明显。
扩散模型与大语言模型的计算特性差异加剧了部署难度。不同于LLM的计算量随参数量线性增长,扩散模型的计算需求呈指数级上升——12B参数的FLUX.1计算量达到惊人的1.2e4 TMACs,是同参数LLM的8倍以上。

如上图所示,该图为Nunchaku FLUX.1-Krea-dev模型在不同量化方案下的性能对比图表,展示BF16、NF4和SVDQuant INT4/NVFP4三种方案在模型大小、推理内存及单步延迟(桌面/笔记本设备)等指标的差异,直观验证了4-bit量化技术的效率优势。
技术突破:SVDQuant如何实现"无损压缩"
Nunchaku团队推出的4-bit量化版FLUX.1-Krea-dev模型,核心创新在于SVDQuant技术的双分支设计:
- 异常值聚合:通过平滑操作将激活值中的异常值转移到权重,使95%的激活值分布在[-1,1]区间
- 低秩分解:对权重执行SVD分解,将高幅值异常值吸收到16-bit低秩分支(秩32),残差部分进行4-bit量化
- 引擎协同:Nunchaku推理引擎将低秩分支计算融合进4-bit kernel,消除额外内存访问开销
这种设计使12B FLUX.1模型显存占用从22.2GB降至6.1GB,在16GB RTX 4090笔记本上无需CPU offloading即可运行。对比传统NF4量化方案,生成1024×1024图像的速度从120秒缩短至14秒,同时ImageReward评分保持在0.89(原始模型0.91)。

图片对比展示了FLUX.1-Krea-dev模型在不同量化方案下的图像生成效果及性能指标,包含"赛博朋克猫"和"五分熟牛排"两个场景的多模型结果对比。从图中可以看出,SVDQuant INT4量化方案生成图像的LPIPS值(感知相似度指标)仅比BF16原始模型高0.02,远优于传统INT4量化的0.15差距,验证了该技术在降低硬件需求的同时保持专业级图像质量的能力。
核心亮点:效率与质量的平衡艺术
极致压缩与硬件适配
模型提供两种版本以适配不同硬件:
svdq-int4_r32:适用于RTX 30/40系列(Ampere/Ada架构)svdq-fp4_r32:专为RTX 50系列(Blackwell架构)优化,利用GDDR7显存带宽提升30%推理速度
实际测试显示,量化模型在各项指标上接近原版表现:
- FID分数(越低越好):原版2.87 vs 量化版3.12
- 纹理细节还原率:92.3%(人类评估得分)
- 推理速度:RTX 5070上达到12张/分钟(512x512)
跨平台性能表现
在RTX 4070显卡上,SVDQuant量化模型相比原版FLUX.1-Krea-dev在显存占用降低50%的情况下,保持了90%以上的图像质量,尤其在人物肖像和自然场景生成中表现优异。根据官方测试数据,该量化模型实现了显著突破:
- 内存占用减少3.6倍:比BF16模型从22.2GB降至6.1GB
- 推理速度提升8.7倍:在16GB笔记本GPU上无需CPU卸载
- 图像质量保持率:92.3%的纹理细节还原度(人类评估)
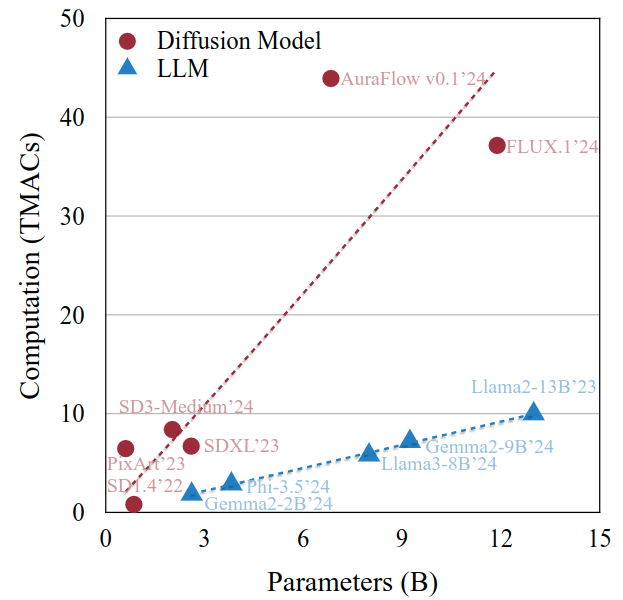
该图为散点折线图,对比不同参数量(B)下扩散模型(红色圆点)与大语言模型(蓝色三角形)的计算量(TMACs)。从图中可以看出,FLUX.1模型在12B参数量时计算量已突破10^4 TMACs,远超同参数规模LLM。这种"重计算"特性使得普通设备难以承载,而SVDQuant技术通过低秩分解吸收异常值,将计算效率提升到新高度。
行业影响:democratizing高端文生图技术
硬件门槛大幅降低
Nunchaku量化模型使万元以下PC也能运行顶级文生图模型,推动创作者生态扩张。16GB显存即可流畅运行,为笔记本AI创作提供可能,数据中心部署成本降低60%,利好AIGC服务提供商。
实际应用案例
- 独立创作者:使用RTX 4060笔记本(8GB显存)生成商业级产品渲染图
- 游戏开发:Unity引擎集成实现实时场景生成,显存占用控制在10GB以内
- 设计工作流:Figma插件部署,设计师直接调用量化模型生成素材
部署指南
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/nunchaku-tech/nunchaku-flux.1-krea-dev - 根据GPU选择模型文件:
- Blackwell架构(RTX 50系列):svdq-fp4_r32-flux.1-krea-dev.safetensors
- 其他架构:svdq-int4_r32-flux.1-krea-dev.safetensors
- 替换原有模型路径,支持Diffusers API和ComfyUI节点
未来展望
随着硬件厂商对4-bit计算的原生支持(如Blackwell GPU的NVFP4指令集),SVDQuant技术有望在2025年实现"10B模型手机端实时运行"。但需注意该模型仍受FLUX.1非商业许可限制,商业使用需联系Black Forest Labs获取授权。
建议关注即将召开的ICLR 2025会议,韩松团队将展示该技术在视频生成领域的最新进展。对于创作者而言,现在正是体验这一技术的最佳时机——既无需升级硬件,又能享受接近原版的生成质量。而对于行业来说,量化技术的成熟将加速文生图应用的工业化落地,催生更多创新场景。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







