Kimi K2:万亿参数MoE模型开源,重塑企业级AI智能体应用格局
 项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Instruct
项目地址: https://ai.gitcode.com/MoonshotAI/Kimi-K2-Instruct 导语
月之暗面(Moonshot AI)于2025年7月正式开源万亿参数级混合专家模型Kimi K2,以1万亿总参数、320亿激活参数的创新架构,重新定义AI智能体(Agent)开发的技术标准,已吸引OpenRouter、Visual Studio Code等30余家企业接入部署。
行业现状:大模型进入"高效智能体"竞争阶段
2025年,大语言模型技术正从通用对话向专业化智能体加速演进。根据行业调研,超过68%的企业因部署成本和技术门槛搁置AI应用计划,而现有解决方案中能同时满足100K+上下文、每秒5+ tokens生成速度和低于50万硬件投入的方案不足15%。在此背景下,混合专家模型(MoE)凭借"大参数规模+高效推理"的特性,成为突破企业级AI落地瓶颈的关键技术路径。
核心亮点:MoE架构的"性能-效率"革命
1. 创新混合专家系统设计
Kimi K2采用384个专家的MoE架构,每次推理动态激活8个专家+1个共享专家,在1万亿总参数规模下仅使用320亿激活参数。这种设计使模型在代码生成、多语言处理和复杂推理任务上达到新高度,其上下文窗口长度从128K提升至256K,可一次性处理超过50万字文档,相当于8本《红楼梦》的文本量。
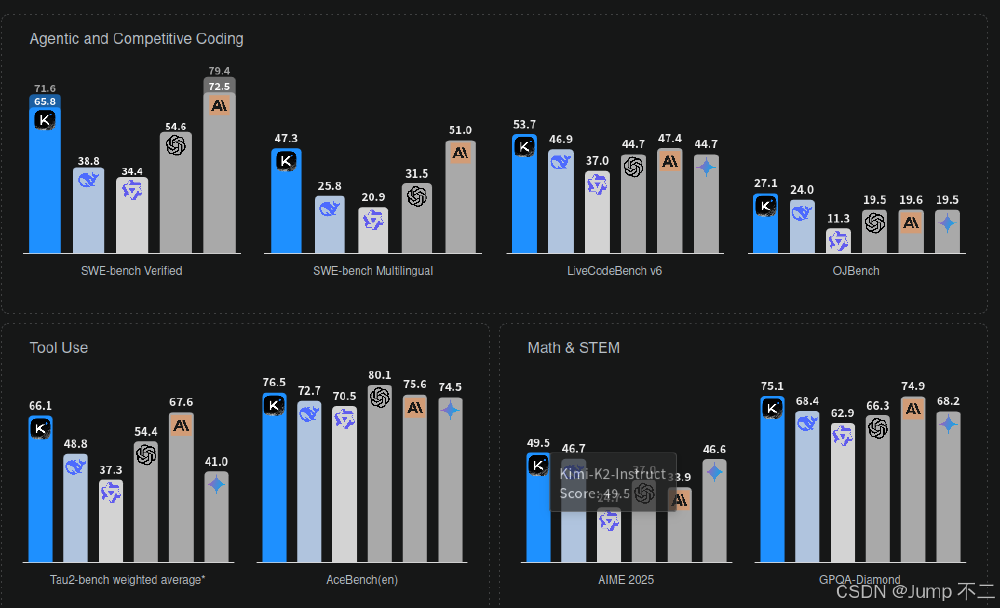
如上图所示,该图表展示了Kimi K2与DeepSeek、Qwen3等主流模型的核心参数对比。从图中可以清晰看到Kimi K2在总参数规模(1T)和上下文长度(256K)上的显著优势,同时320亿的激活参数确保了推理效率,为企业级应用提供了性能与成本的平衡选择。
2. 卓越的代码生成与工具调用能力
在权威代码基准测试中,Kimi K2展现优异性能:SWE-Bench验证集准确率达69.2%,多语言代码生成(SWE-Bench Multilingual)准确率55.9%,终端任务处理(Terminal-Bench)准确率44.5%。美国创业公司Genspark接入Kimi K2后,其AI Agent产品Super Agent实现45天3600万美元的年度经常性收入(ARR),成为模型商业价值的有力证明。
3. 革命性的本地化部署方案
通过Unsloth Dynamic 2.0量化技术,Kimi K2将部署门槛大幅降低。配备16GB VRAM和256GB RAM的普通服务器即可实现每秒5+ tokens的生成速度,采用2-bit XL量化技术后甚至可在消费级硬件运行基础功能。这种部署灵活性使模型应用场景从企业知识库扩展到嵌入式系统。
行业影响:开启AI智能体普惠化进程
1. 企业级应用加速落地
多家科技公司已宣布接入Kimi K2,包括OpenRouter、Visual Studio Code、硅基流动、金山云等。这些合作覆盖代码开发、文档处理、智能客服等场景:某法律咨询公司使用Kimi K2处理合并收购文档,将审查时间从48小时缩短至6小时,准确率保持95%以上;某电商平台集成后,客服问题一次性解决率提升40%,平均对话轮次减少35%。

该图片展示了接入Kimi K2模型的部分企业生态,包括Genspark、Vercel、YouWare等知名编程和Agent应用。这些合作案例证明Kimi K2已形成初步生态系统,正在AI开发工具链中占据重要位置,为开发者提供从原型到生产的全流程支持。
2. 技术架构引领行业方向
Kimi K2的成功印证了MoE架构在企业级应用中的优势。其采用的MuonClip优化器解决了大模型训练中的梯度稳定性问题,实现15.5T tokens的全程稳定训练。这种技术路径正影响行业发展方向,2025年下半年已有多家厂商宣布跟进万亿级MoE模型开发。
部署与应用指南
快速启动步骤
- 克隆项目仓库:
git clone https://gitcode.com/MoonshotAI/Kimi-K2-Instruct - 环境准备:推荐配备16GB+ VRAM的NVIDIA GPU,Python 3.10+环境
- 基础调用示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("MoonshotAI/Kimi-K2-Instruct")
model = AutoModelForCausalLM.from_pretrained("MoonshotAI/Kimi-K2-Instruct")
inputs = tokenizer("请分析2025年Q2全球半导体行业趋势", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
企业应用建议
- 软件开发企业:优先探索代码生成和自动化测试场景,可显著提升开发效率
- 金融与法律行业:利用256K上下文窗口处理复杂文档,降低合规风险
- 制造业:结合工具调用能力构建智能诊断系统,提升设备维护效率
- 中小企业:从文档问答和客服助手入手,以较低成本实现AI转型
总结:MoE模型定义AI新范式
Kimi K2通过创新的混合专家系统架构、卓越的性能表现和灵活的部署选项,为企业级大模型应用提供了理想解决方案。其开源特性加速了AI技术普惠化进程,使更多企业能够突破成本和技术壁垒,享受先进AI带来的价值。随着本地化部署技术的成熟,大语言模型正从"尝鲜体验"阶段进入"规模化落地"阶段,而Kimi K2所代表的"高效智能体"技术路径,无疑将成为这一进程的重要推动者。
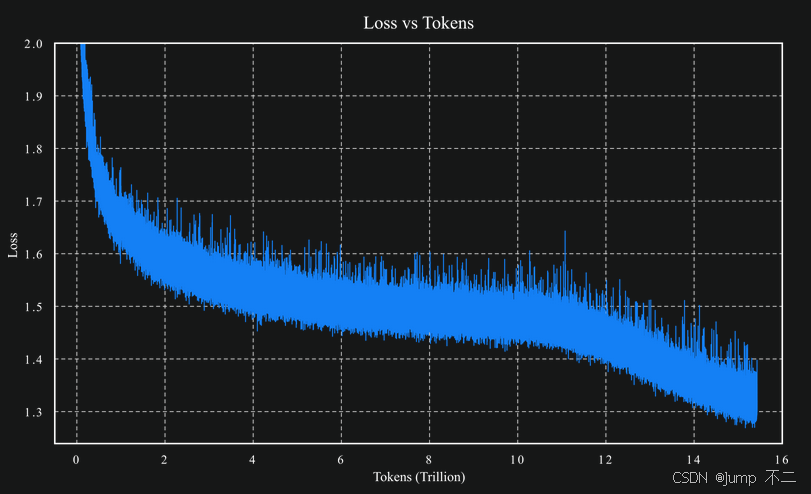
该图表显示了Kimi K2模型训练过程中损失值随处理token数量增加而下降并趋于稳定的趋势。从图中可以看出,得益于MuonClip优化器的应用,模型在处理15.5T tokens的全过程中保持了训练稳定性,这为模型的高性能提供了坚实基础,也展示了月之暗面在大模型训练技术上的深厚积累。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







