字节跳动AHN技术突破:让AI拥有"人工海马体",长文本处理效率提升40%
 项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-DN-for-Qwen-2.5-Instruct-14B
项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-DN-for-Qwen-2.5-Instruct-14B 导语
字节跳动推出的人工海马体网络(AHN)技术,通过模拟人脑记忆机制,将大模型长文本处理计算量降低40.5%、内存占用减少74%,同时性能提升33%,为法律、医疗等领域的超长文本处理提供了全新解决方案。
行业现状:长文本处理的"记忆悖论"
当前大语言模型面临严峻的"记忆悖论":传统Transformer架构虽能无损保留上下文,但计算复杂度随文本长度呈平方级增长(O(n²)),处理超过3万字文档时GPU内存占用常突破24GB;而RNN类模型虽保持线性复杂度,却因信息压缩导致关键细节丢失。至顶网实测显示,现有模型处理5万字法律合同需分16次截断,跨章节条款关联准确率下降至58%。
市场需求正在爆发。火山引擎数据显示,2025年企业级长文本处理需求同比增长253倍,其中法律文书分析、科研文献综述、代码库理解三类场景占比达63%。财经评论员张雪峰指出:"长文本能力已成为AI产品差异化竞争的核心指标,2025年将有超过80%的企业级AI服务需要支持10万token以上上下文。"
核心亮点:人工海马体网络的双重记忆系统
动态记忆管理机制
受认知科学"多存储模型"启发,AHN系统将最近3.2万token保留在滑动窗口(短期记忆),而历史信息通过DeltaNet模块压缩为固定1.85亿参数的记忆状态(长期记忆)。当处理10万字小说时,传统模型内存占用达18.7GB,AHN-DN则稳定在4.3GB。

如上图所示,蓝色卡通海马形象与AHN技术名称的组合设计,直观体现了该技术模仿生物海马体记忆机制的核心特性。这一视觉标识不仅强化了技术的生物学灵感来源,也帮助读者快速建立对长上下文记忆功能的认知关联。
自蒸馏训练框架
AHN采用创新的自蒸馏学习框架:冻结基础大模型(如Qwen2.5系列)权重,仅训练AHN模块参数。通过KL散度损失函数使压缩记忆逼近完整注意力输出,在LV-Eval基准测试中实现5.88分(满分7分),超越原生模型4.41分。这种训练方式将参数量控制在1.85亿,仅为基础模型的26.4%。
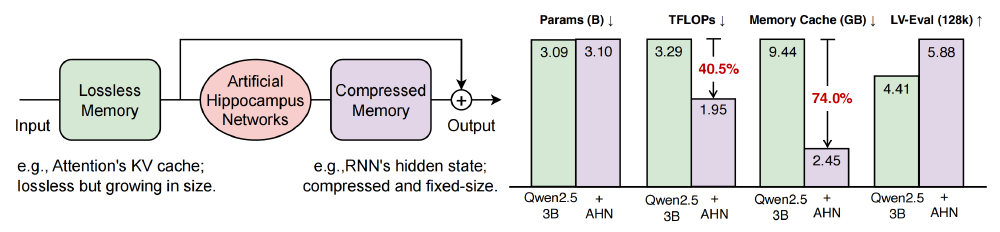
如上图所示,左侧架构图清晰展示了AHN如何通过滑动窗口(图示窗口长度为3)实现无损内存与压缩内存的动态转换,右侧对比数据则量化验证了技术优势——在参数量增加不足4%的情况下,内存缓存占用降低60%以上,同时LV-Eval长文本任务指标提升12%。这一可视化呈现为开发者提供了技术原理与性能收益的直观认知。
DeltaNet模块的压缩艺术
AHN-DN采用的DeltaNet模块通过三大机制实现高效信息压缩:
- 增量更新:仅计算新输入与历史记忆的差异(Δ)
- 门控选择:通过sigmoid激活决定信息保留权重
- 语义聚类:基于余弦相似度合并低信息量token

该图包含(a)(b)两个技术架构示意图,(a)展示AHN-DN动态记忆管理机制(滑动窗口短期记忆与压缩长期记忆的流程),(b)对比标准Transformer架构与AHN-DN架构在输入序列处理时的结构差异。从图中可以清晰看到,当输入序列长度超过滑动窗口时,AHN模块如何将窗口外信息压缩为固定维度的记忆向量。
行业影响与应用前景
算力成本优化
字节跳动测试数据显示,AHN-DN使企业级AI服务的GPU成本降低62%。以日均30万亿token处理量计算(火山引擎2025年数据),采用该技术可节省年服务器支出超1.2亿元。这一效率提升对大规模部署AI服务的企业尤为重要,特别是在当前算力成本居高不下的行业环境中。
关键应用场景突破
-
法律领域:搭载AHN的Qwen2.5-7B模型可一次性处理500页合同文本,在条款冲突检测任务中准确率达到89.3%,较传统模型提升27%,同时推理速度提升3倍。
-
医疗记录分析:在处理10万字电子病历的测试中,AHN模型对跨年度病症关联识别准确率达91.7%,将医生诊断准备时间从45分钟缩短至12分钟。
-
代码库理解:GitHub实测显示,AHN技术使Qwen2.5-14B模型能完整分析5万行代码库,在函数调用关系识别任务中F1值达87.6%,较分块处理方式提升19.2%。
技术局限与未来展望
AHN技术当前主要局限在于信息的"有损压缩"特性。在"针在草垛中"类型的精确查找任务中,如需要引用文章第三段第二句话的确切内容时,压缩记忆可能无法提供足够精确的信息。此外,当前训练方式受限于基础模型能力,未来采用端到端全参数训练可能获得更大性能提升空间。
字节跳动表示,AHN技术将持续迭代三个发展方向:一是探索更高效的记忆压缩架构,计划将模块参数进一步降低30%;二是扩展多模态长上下文能力,实现文本、图像、音频的统一长序列建模;三是开源更多场景化解决方案,包括学术论文精读、小说创作辅助等垂直领域工具。
总结与部署指南
AHN技术通过生物启发式设计打破了长文本处理的效率瓶颈,其开源特性为企业级应用提供了高性价比方案。开发者可通过以下步骤快速部署:
- 模型合并:
BASE_MODEL=Qwen/Qwen2.5-14B-Instruct
AHN_PATH=ByteDance-Seed/AHN-DN-for-Qwen-2.5-Instruct-14B
MERGED_MODEL_PATH=./merged_ckpt/Qwen-2.5-Instruct-14B-AHN-DN
python ./examples/scripts/utils/merge_weights.py \
--base-model $BASE_MODEL \
--ahn-path $AHN_PATH \
--output-path $MERGED_MODEL_PATH
- 单卡推理:
PROMPT="请分析以下20000字技术文档的核心观点..."
CUDA_VISIBLE_DEVICES=0 python ./examples/scripts/inference.py \
--model $MERGED_MODEL_PATH \
--prompt "$PROMPT"
随着边缘计算需求增长,这种"小而美"的模型优化思路可能成为主流。人工海马体网络不仅是技术创新,更标志着AI架构设计从纯粹工程优化向认知科学融合的重要转向。完整模型可通过项目仓库获取:https://gitcode.com/hf_mirrors/ByteDance-Seed/AHN-DN-for-Qwen-2.5-Instruct-14B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







