突破日志传输瓶颈:Fluentd与Kafka/RabbitMQ的无缝集成实战
 项目地址: https://gitcode.com/gh_mirrors/fl/fluentd
项目地址: https://gitcode.com/gh_mirrors/fl/fluentd 你是否还在为日志数据积压、传输延迟而困扰?作为统一日志层(Unified Logging Layer)的核心组件,Fluentd通过与消息队列集成,可实现日志的高可靠、高吞吐传输。本文将带你一步步掌握Fluentd与Kafka、RabbitMQ两大主流消息队列的集成方案,读完你将获得:
- 两种消息队列输出插件的配置模板
- 性能调优关键参数解析
- 故障处理与监控实践指南
为什么选择消息队列集成?
Fluentd作为CNCF毕业项目,其插件化架构支持与700+数据源和目的地集成。消息队列(Message Queue)作为日志传输的中间层,能够有效解决:
- 峰值削峰:应对突发流量时的日志洪峰
- 系统解耦:日志生产者与消费者独立扩容
- 数据可靠:通过持久化避免日志丢失
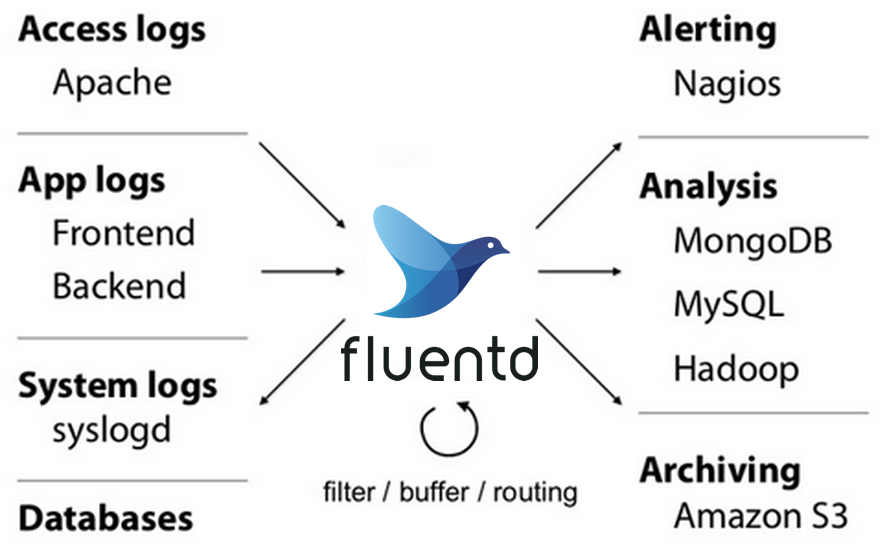
官方架构图展示了Fluentd在日志收集链路中的核心地位,消息队列通常部署在Fluentd与后端存储之间README.md
环境准备与插件安装
基础环境要求
- Ruby 3.2+(Fluentd运行环境)
- Kafka 2.8+ 或 RabbitMQ 3.9+
- Fluentd 1.16+(通过
gem install fluentd安装)
输出插件安装
# Kafka输出插件
gem install fluent-plugin-kafka
# RabbitMQ输出插件
gem install fluent-plugin-rabbitmq
插件安装后可通过
fluentd --plugin命令验证加载情况
Kafka输出插件实战
核心配置模板
创建kafka_output.conf配置文件:
<match application.**>
@type kafka_buffered
# Kafka集群配置
brokers 192.168.1.10:9092,192.168.1.11:9092
topic_key log_topic
partition_key %{record["user_id"]}
# 数据格式设置
format json
include_tag_key true
tag_key fluentd_tag
# 缓冲策略(关键性能参数)
buffer_type file
buffer_path /var/log/fluentd/kafka_buffer/
buffer_chunk_size 8m
buffer_queue_limit 32
flush_interval 5s
retry_limit 17
retry_wait 1.0
</match>
配置文件存放路径建议遵循FHS标准,通常为
/etc/fluentd/conf.d/
关键参数解析
| 参数 | 作用 | 推荐值 |
|---|---|---|
| buffer_chunk_size | 单个缓冲文件大小 | 4-16MB |
| buffer_queue_limit | 最大缓冲队列数 | 16-64 |
| retry_limit | 失败重试次数 | 17(约24小时) |
| partition_key | 分区键表达式 | %{record["id"]} |
性能优化建议
- 分区策略:按业务模块设置topic,避免单topic过度分区
- 批量发送:通过
flush_at_shutdown true确保进程退出时数据刷写 - 监控指标:关注
out_kafka_buffer_queue_length和out_kafka_retry_count指标
RabbitMQ输出插件实战
核心配置模板
创建rabbitmq_output.conf配置文件:
<match system.**>
@type rabbitmq
# 连接配置
host 192.168.1.12
port 5672
user guest
password guest
vhost /
exchange log_exchange
exchange_type topic
routing_key %{tag}
# 消息属性
content_type application/json
delivery_mode persistent
# 错误处理
error_backup_path /var/log/fluentd/rabbitmq_backup/
# 连接池设置
connection_pool_size 5
heartbeat 30
</match>
RabbitMQ的exchange和queue需要预先创建,推荐使用topic类型exchange实现灵活路由
与Kafka插件的关键差异
| 特性 | Kafka插件 | RabbitMQ插件 |
|---|---|---|
| 消息顺序 | 分区内有序 | 单队列有序 |
| 持久化 | 日志级持久化 | 消息级持久化 |
| 吞吐量 | 高(十万级/秒) | 中(万级/秒) |
| 适用场景 | 大数据量批处理 | 实时消息通知 |
故障恢复机制
- 备份文件:通过
error_backup_path保存发送失败的消息 - 死信队列:配置
x-dead-letter-exchange处理无法路由的消息 - 连接恢复:默认启用自动重连,可通过
reconnect_interval调整间隔
集成架构对比与选型建议
典型架构图
选型决策树
- 数据量评估:日活日志超10TB优先选择Kafka
- 延迟要求:毫秒级实时性需求选择RabbitMQ
- 生态集成:与Hadoop/Spark栈集成选Kafka,与微服务通知系统集成选RabbitMQ
- 运维复杂度:Kafka需维护ZooKeeper集群,RabbitMQ单节点部署更简单
监控与故障处理
核心监控指标
Fluentd内置监控接口可通过in_monitor_agent插件暴露指标:
<source>
@type monitor_agent
bind 0.0.0.0
port 24220
</source>
关键监控指标:
buffer_total_queued_size:总缓冲大小retry_count:重试次数output_status:输出状态(ok/warn/error)
常见故障排查流程
- 连接失败:检查网络ACL和消息队列服务状态
- 消息积压:通过
buffer_chunk_limit和buffer_queue_limit调整缓冲策略 - 数据格式错误:启用
@log_level debug查看详细错误日志
总结与最佳实践
通过本文学习,你已掌握Fluentd与两大主流消息队列的集成方案。实际部署中建议:
- 分层部署:按日志重要性分离处理链路(核心业务→Kafka,系统日志→RabbitMQ)
- 配置管理:使用
@include指令拆分大型配置文件,如:@include conf.d/kafka/*.conf @include conf.d/rabbitmq/*.conf - 版本控制:通过Git管理配置文件,配合CI/CD实现配置自动部署
更多输出插件配置示例可参考example目录下的配置模板,如
out_forward.conf展示了基础转发配置
最后,记得关注Fluentd官方CHANGELOG.md获取插件更新动态,定期升级以获得性能优化和安全修复。你在集成过程中遇到过哪些挑战?欢迎在评论区分享你的解决方案!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







