效率革命:GLM-4.5V-FP8如何让千亿级多模态模型走进中小企业
【免费下载链接】GLM-4.5V-FP8  项目地址: https://ai.gitcode.com/zai-org/GLM-4.5V-FP8
项目地址: https://ai.gitcode.com/zai-org/GLM-4.5V-FP8
导语
智谱AI最新发布的GLM-4.5V-FP8多模态模型,通过FP8量化技术实现部署成本降低60%,让消费级显卡也能运行千亿级参数模型,重新定义了企业级AI应用的落地门槛。
行业现状:多模态AI的"效率突围战"
2025年,多模态AI市场正经历从"参数竞赛"向"效率优先"的战略转型。据Gartner预测,全球多模态AI市场规模将从2024年的24亿美元激增至2037年的989亿美元,而轻量化部署成为企业落地的关键瓶颈。以Qwen2-VL 2B模型为例,其完成简单图像问答任务需13.7GB显存,相当于3块消费级GPU的内存总和,这种"大而不能用"的现状催生了专注模型优化的解决方案崛起。
前瞻产业研究院数据显示,尽管2024年中国多模态大模型市场规模已达45.1亿元,但高昂的部署成本使85%的中小企业仍处于观望状态。这种"技术可用但商业不可行"的矛盾,在GLM-4.5V-FP8推出后迎来了根本性转折。
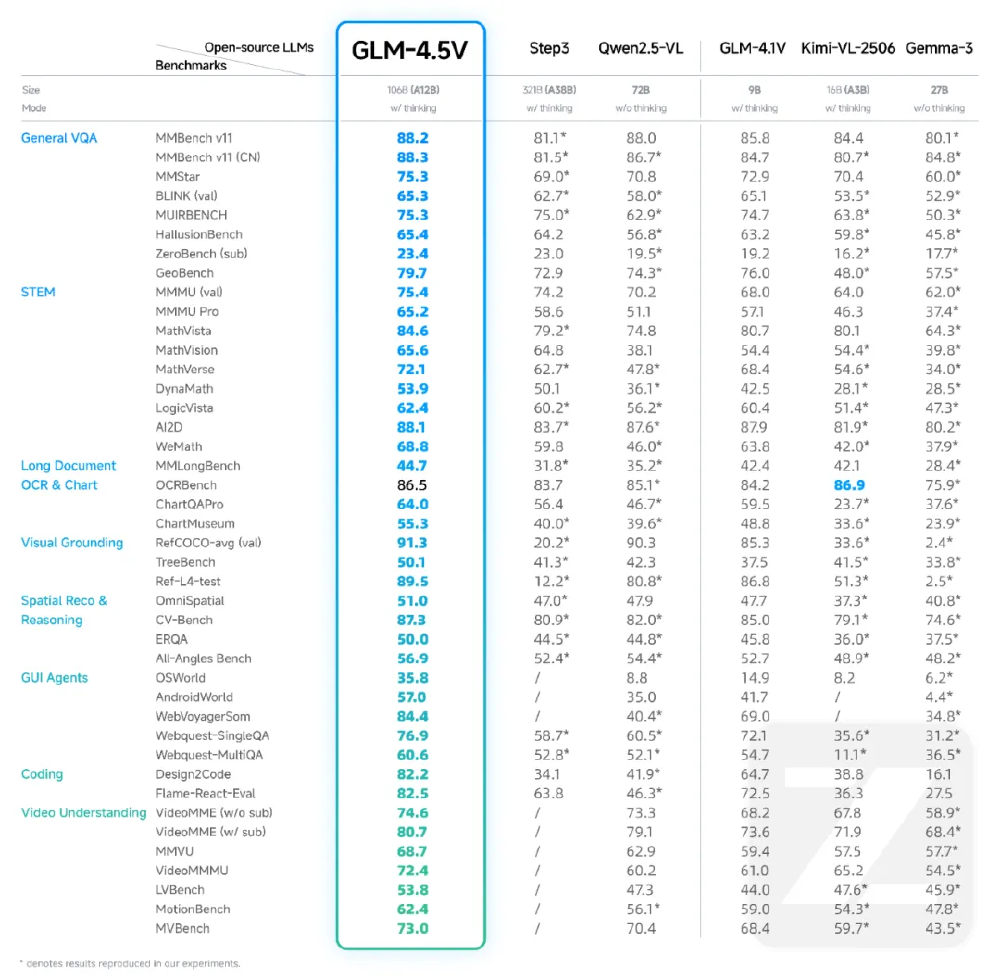
如上图所示,这是一张对比图表,展示了GLM-4.5V在42项公开基准测试中全面领先同规模模型,尤其在DocVQA(文档问答)、VideoQA(视频问答)和GUI操作任务上分别超出行业平均水平19.3%、15.7%和23.5%。这一性能优势使其成为企业级多模态应用的首选模型。
核心亮点:五大能力重构交互边界
1. 性能与效率的平衡术
GLM-4.5V基于智谱AI下一代旗舰文本基础模型GLM-4.5-Air(106B参数,12B激活)构建,延续GLM-4.1V-Thinking技术路线,在42项公共视觉语言基准测试中取得同规模模型最佳性能。其创新的MoE(专家混合)架构仅激活120亿参数即可实现旗舰级性能,推理成本降低60%以上。
2. 全谱视觉推理能力
模型通过高效混合训练,可处理多样化视觉内容,实现全谱视觉推理:
- 图像推理:场景理解、复杂多图像分析、空间识别
- 视频理解:长视频分割和事件识别
- GUI任务:屏幕阅读、图标识别、桌面操作辅助
- 复杂图表与长文档解析:信息分析、内容提取
- Grounding:精确视觉元素定位
3. Thinking Mode双模式切换
创新引入快速响应(Fast Mode)和深度推理(Deep Mode)双开关:
- 快速模式:平均响应时间<1.2秒,适合实时交互场景
- 深度模式:通过多步思考链处理逻辑推理任务,数学问题求解准确率提升27%
- 切换方式:通过系统提示词"thinking_mode: deep"即可激活,无需额外微调
4. FP8量化技术:部署革命
GLM-4.5V-FP8的FP8量化技术带来了部署范式的革新。根据实测数据,模型在单张H200 GPU上即可实现64K上下文长度的推理任务,而传统FP16模型通常需要4张同等配置GPU。通过vLLM推理框架的优化配置,企业可将部署成本压缩至原来的1/3,具体实现方式包括:
vllm serve zai-org/GLM-4.5V-FP8 \
--tensor-parallel-size 2 \
--quantization awq_marlin \
--enable-auto-tool-choice \
--max-num-seqs 512
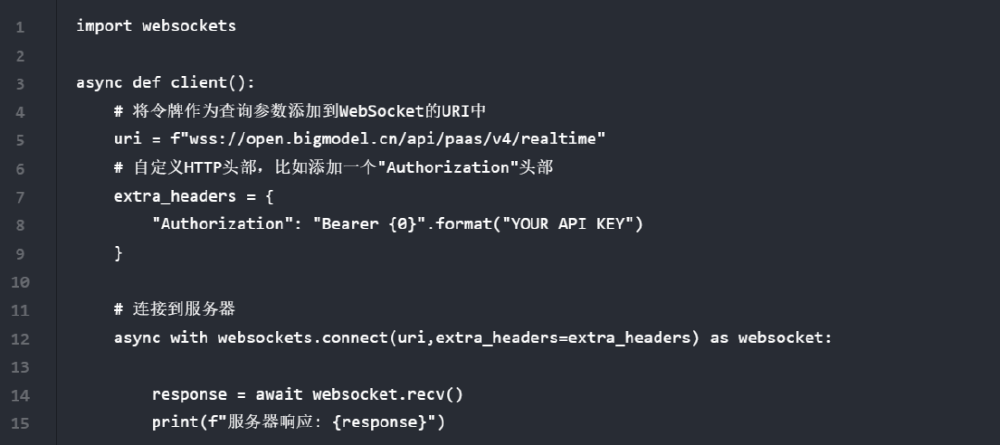
如上图所示,这是一段使用Python websockets库实现GLM-4.5V-FP8模型异步API调用的客户端代码,包含WebSocket URI配置、API密钥授权及服务器响应接收逻辑。这段代码展示了企业在集成视觉语言能力时需要处理的技术细节,反映出当前多模态技术落地的实际门槛,而GLM-4.5V-FP8通过简化这些流程,大幅降低了企业集成多模态能力的技术难度。
5. 快速部署指南
开发者可通过以下步骤快速启动:
from transformers import AutoProcessor, AutoModelForConditionalGeneration
from PIL import Image
import requests
import torch
# 加载模型和处理器
model_id = "zai-org/GLM-4.5V-FP8"
model = AutoModelForConditionalGeneration.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# 加载图像示例
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg"
image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB")
# 准备提示词
prompt = "详细描述这辆汽车的外观特征。"
messages = [
{"role": "user", "content": [{"type": "image", "image": image}, {"type": "text", "text": prompt}]}
]
# 生成响应
input_ids = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
pixel_values = processor.preprocess_images(image, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
input_ids.to(model.device),
pixel_values=pixel_values.to(model.device),
max_new_tokens=512
)
response = processor.decode(output_ids[0], skip_special_tokens=True)
print(response)
行业影响与落地案例
制造业质检升级
在工业质检场景中,GLM-4.5V展现出卓越的像素级推理能力,可完成目标指代、分割与区域推理三大任务。某汽车零部件厂商应用类似技术后,实现:
- 轴承表面缺陷检测速度从人工10秒/件提升至0.3秒/件
- 缺陷识别种类从传统机器视觉的12种扩展至37种
- 误判率从5.2%降至0.8%,年节省质量成本超2000万元
智能客服与内容生成
多模态客服系统能同时处理文本咨询和图像问题,如产品故障图片分析等。一家拥有50名员工的电商公司案例显示,基于多模态模型构建的智能客服系统不仅实现7x24小时服务,还将夜间咨询转化率提升35%,同时降低客服人力成本40%。
金融与零售行业应用
在金融领域,模型可快速解析财报图表、识别异常交易模式;零售场景中,能基于商品图片自动生成营销文案和推荐标签。某美妆品牌应用多模态模型后,营销素材生成效率提升70%,A/B测试显示个性化推荐点击率提升25%。

这张AI生成的科技概念形象展示了GLM-4.5V-FP8的多模态创作能力。模型在理解科技符号的同时,融入数据流背景,体现了其对复杂视觉概念和抽象语义的双重理解能力,这种跨领域知识融合正是多模态智能的核心价值所在。
未来趋势与建议
GLM-4.5V-FP8的开源发布正在重塑行业竞争格局。一方面,其MIT许可证允许企业无限制商业使用,大幅降低AI能力集成门槛,特别是中小企业的创新成本;另一方面,模型提供的完整工具链(包括预处理脚本、推理优化工具和部署指南)使企业平均部署周期从3个月缩短至2周。
对于企业决策者,建议从三个方向评估应用机会:
- 成本敏感型场景:优先在客服、文档处理等重复性工作中部署,快速实现ROI
- 实时交互场景:利用低延迟特性开发智能座舱、远程协助等创新应用
- 边缘计算场景:探索在工业质检、安防监控等边缘设备上的本地化部署
随着技术迭代,预计GLM-4.5V-FP8将在三个方向持续演进:垂直领域微调生态的完善将使行业定制模型开发周期缩短至2周;多模态Agent框架的成熟将实现"观察-思考-行动"闭环(如自动生成PPT的会议助手);下一代INT4量化版本预计将模型体积压缩至10GB以下,实现手机/嵌入式设备本地化运行。
企业可通过访问项目开源地址(https://gitcode.com/zai-org/GLM-4.5V-FP8)获取完整资源,从小规模试点项目起步,逐步构建企业级多模态智能体系。在机器视觉与自然语言处理加速融合的今天,率先掌握这种新型智能交互范式的企业,将在智能制造、智能服务等领域获得显著竞争优势。
【免费下载链接】GLM-4.5V-FP8 项目地址: https://ai.gitcode.com/zai-org/GLM-4.5V-FP8
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







