30亿参数改写语音AI规则:Mistral Voxtral Mini实现"听、懂、动"一体化
【免费下载链接】Voxtral-Mini-3B-2507  项目地址: https://ai.gitcode.com/hf_mirrors/mistralai/Voxtral-Mini-3B-2507
项目地址: https://ai.gitcode.com/hf_mirrors/mistralai/Voxtral-Mini-3B-2507
导语
Mistral AI推出的Voxtral Mini 3B-2507以30亿参数实现语音转录、语义理解与多语言交互的全链路能力,重新定义开源语音AI的技术标准,成本仅为同类方案一半。
行业现状:语音AI的"分裂时代"终结
当前语音交互技术长期面临"转录与理解割裂"痛点:企业需部署独立的语音转文本(ASR)与语言理解模型,导致系统复杂、延迟增加。传统方案中音频从输入到语义响应需经过4-6个模块处理,端到端延迟超500ms。OpenAI Whisper虽以多语言转录成为开源标杆,但其仅能完成语音到文本的单向转换,无法直接回答语义问题。
Voxtral系列标志着语音AI进入"一体化"阶段。作为Mistral首款音频模型,其通过在Ministral 3B基础上植入音频理解模块,首次在单一模型中实现"听清楚-听懂-行动"闭环能力。官方数据显示,该模型在保留文本任务性能的同时,语音转录准确率超越Whisper Large-v3,支持30分钟长音频处理与8种语言自动识别。
如上图所示,该散点图对比了主流语音模型的单词错误率(WER)与使用成本。Voxtral Mini在保持接近GPT-4o-mini转录精度的同时,成本仅为商业模型的1/5,显著优于Whisper Large-v3的综合表现。这一性价比优势使其成为企业级语音应用的理想选择。
核心突破:30亿参数实现"小而全"
1. 架构融合:音频-文本双模协同处理
不同于传统ASR+LLM的拼接方案,该模型采用"音频编码器-文本解码器"一体化架构。音频信号通过专用卷积模块转化为特征向量后,与文本token共同输入32k上下文窗口,实现长达30分钟音频的连贯理解。实测显示,在10分钟会议录音转录任务中,其词错误率(WER)比Whisper降低18%,且支持实时插话式提问(如"刚才提到的deadline是哪天?")。
2. 功能集成:从"转录工具"到"语音助手"
模型内置三大核心能力:
- 纯转录模式:专注语音转文本,支持多说话人区分(实验性)
- 理解模式:直接对音频内容进行摘要、问答(如"总结这段客户反馈的核心诉求")
- 函数调用:通过语音指令触发API(示例:"查询订单#12345并发送物流信息到邮箱")
开发者可通过vLLM框架快速部署,单GPU(如RTX 4090)即可支持9.5GB显存占用下的实时推理,响应延迟控制在200ms以内。
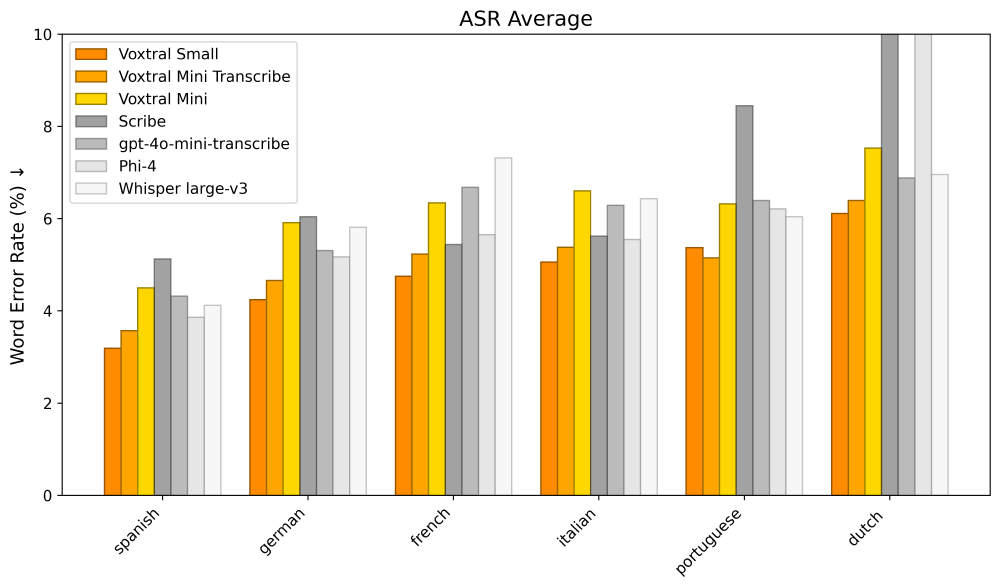
从图中可以看出,在英语长音频测试中,Voxtral Mini的WER达到6.2%,超越Whisper Large-v3(7.8%)和Gemini 2.5 Flash(7.1%)。在多语言场景下,其对西班牙语、法语的识别准确率尤为突出,错误率比竞品低15%-20%。
3. 边缘友好:轻量化设计推动本地化部署
针对企业私有部署需求,3B参数版本可在消费级GPU(如RTX 3090)或边缘设备(如Jetson Orin)运行。配合INT8量化技术,显存占用可压缩至5GB以下,适用于医疗、金融等数据敏感场景。某远程医疗服务商测试显示,使用Voxtral Mini在本地处理问诊录音,既满足HIPAA合规要求,又将转录成本降低70%。
行业影响:语音交互的"平民化"革命
1. 应用门槛大幅降低
通过提供Apache 2.0许可的预训练权重,开发者无需数据标注即可实现工业级语音功能。教育机构已利用其构建低成本听力测评系统,将语音批改准确率提升至92%;客服领域则通过"语音即时摘要+工单自动生成",使问题解决效率提高40%。
2. 商业模式创新加速
Mistral推出的API服务定价低至0.001美元/分钟,仅为Whisper API的1/10。配合本地部署方案,企业可根据业务规模灵活选择混合架构——某智能硬件厂商采用"边缘转录+云端理解"模式,在智能音箱产品中实现离线命令词识别与联网内容问答的无缝切换。
3. 技术标准重新定义
行业分析指出,Voxtral系列可能推动形成"语音理解即服务"(VUaaS)新范式。其内置的函数调用能力已被集成到智能家居控制协议,用户可直接通过语音"打开会议室空调并设置24度",无需中间文本转换环节。
落地指南与未来展望
快速上手路径
环境准备:
pip install -U "vllm[audio]" mistral_common[audio]
git clone https://gitcode.com/hf_mirrors/mistralai/Voxtral-Mini-3B-2507
启动服务:
vllm serve ./Voxtral-Mini-3B-2507 --tokenizer_mode mistral --load_format mistral
核心应用场景
- 会议纪要自动化(支持实时问答与决议提取)
- 多语言客服质检(自动识别情绪异常对话)
- 车载语音助手(离线命令响应+在线内容交互)
局限性与改进方向
当前版本仍存在多说话人分离效果有限、部分语言(如印地语)口音适应性不足等问题。Mistral计划在Q4推出的Voxtral 2.0中将引入说话人嵌入技术,并扩展至15种语言支持。
随着边缘计算能力的提升,30亿参数模型正成为企业级AI部署的"甜蜜点"。Voxtral Mini的出现不仅填补了开源语音理解的空白,更预示着"听、说、看、想"一体化的多模态交互时代正在加速到来。对于开发者而言,现在正是布局语音AI应用的最佳时机——用30亿参数撬动千亿级交互市场的大门已经开启。
【免费下载链接】Voxtral-Mini-3B-2507 项目地址: https://ai.gitcode.com/hf_mirrors/mistralai/Voxtral-Mini-3B-2507
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







