




复习了一下juc的知识,今天来总结下ThreadPoolExecutor线程池,如果感觉有用,请给我一个赞吧Ciallo~(∠・ω< )⌒★。
一、 使用线程池的好处
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
二、为什么推荐使用 ThreadPoolExecutor 构造函数创建线程池
在《阿里巴巴 Java 开发手册》“并发处理”这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。
为什么呢,也就是上面讲的?
使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。如果不使用线程池,有可能会造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
另外《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下:
FixedThreadPool和SingleThreadExecutor: 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。- CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
三、ThreadPoolExecutor线程池七个参数详解
那想要用好ThreadPoolExecutor线程池那你必须去了解它的参数,接下来就是对它参数的详解
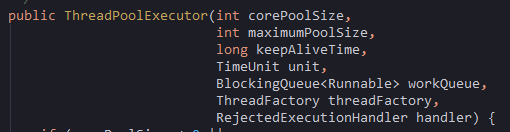
从源码中可以看出,线程池的构造函数有7个参数,分别是corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler。
(1)corePoolSize 核心线程数量
线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,它们也不会被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。任务提交到线程池后,首先会检查当前线程数是否达到了corePoolSize,如果没有达到的话,则会创建一个新线程来处理这个任务。
(2)maximumPoolSize 最大线程数量
当前线程数达到corePoolSize后,如果继续有任务被提交到线程池,会将任务缓存到工作队列(后面会介绍)中。如果队列也已满,则会去创建一个新线程来出来这个处理。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize指定。
(3)keepAliveTime 空闲线程存活时间
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定。
(4)unit 空闲线程存活时间单位
keepAliveTime的计量单位。
(5)workQueue 工作队列
新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk中提供了四种工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQueue
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而基本不会去创建新线程直到maxPoolSize(很难达到Interger.MAX这个数),因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
③SynchronousQueue
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
(6)threadFactory 线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
(7)handler 拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的,jdk中提供了4中拒绝策略:
①CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
②AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
③DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
④DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列。
四、线程池大小确定
线程池数量的确定一直是困扰着程序员的一个难题,大部分程序员在设定线程池大小的时候就是随心而定。 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了上下文切换成本。有一个简单并且适用面比较广的公式:
-
CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
-
I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。、
如何判断是 CPU 密集任务还是 IO 密集任务?
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。单凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









