




 本文介绍了在Ubuntu上安装Hive的详细步骤,包括下载安装包、修改环境配置、创建HDFS目录、解决启动错误、安装MySQL以及配置使用MySQL作为元数据存储。此外,还提到了Hive适用于大规模数据批处理,不适用于低延迟查询和联机事务处理。
本文介绍了在Ubuntu上安装Hive的详细步骤,包括下载安装包、修改环境配置、创建HDFS目录、解决启动错误、安装MySQL以及配置使用MySQL作为元数据存储。此外,还提到了Hive适用于大规模数据批处理,不适用于低延迟查询和联机事务处理。
hive,是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive是十分适合数据仓库的统计分析和Windows注册表文件。
hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询。hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。
安装准备:①jdk1.7+ ②hadoop安装
1、下载hive安装包并解压(tar -zxvf )
2、修改环境配置 $ vim .bashrc
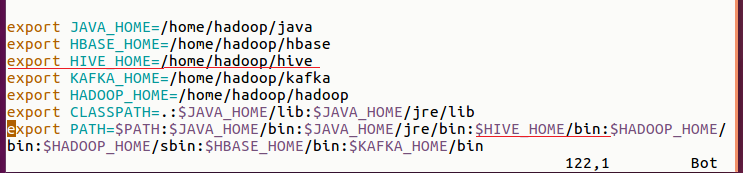
应用修改 $ source .bashrc
3.在hadoop创建hive文件路径
$ hdfs dfs -mkdir -p /user/hive/warehouse
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









