



在健康管理领域,脱发问题备受关注。本文借助 Python 数据可视化工具(Matplotlib、Pandas),从脱发标记分布、年龄关联、医疗诊断及二值特征等维度,剖析脱发影响因素,为脱发研究与预防提供数据支撑。
一、数据与工具说明
数据围绕脱发标记、年龄、医疗状况、二值特征(遗传、激素等)展开,利用 Pandas 处理数据,Matplotlib 绘制可视化图表,直观呈现各因素与脱发的关联。
二、可视化分析
1. 脱发标记分布:样本均衡性观察
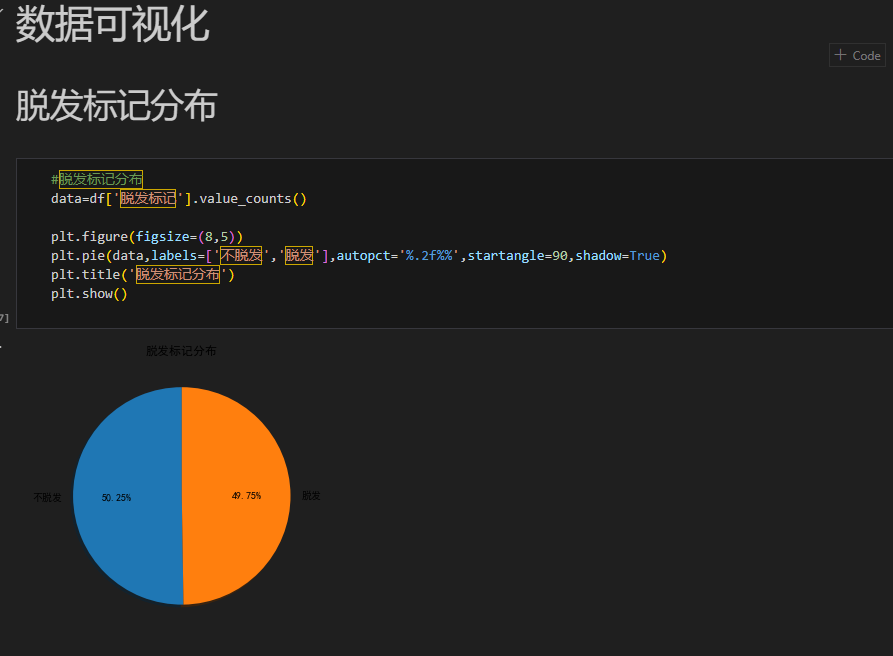
通过饼图展示脱发标记(“脱发”“不脱发”)的分布:# 统计脱发标记分布 data = df['脱发标记'].value_counts() plt.pie(data, labels=['不脱发', '脱发'], autopct='%.2f%%', startangle=90, shadow=True) plt.title('脱发标记分布') plt.show()
(二)模型调优与融合
(三)研究深化与应用
开展长期跟踪研究,采集个体随时间变化的脱发数据,分析脱发发展趋势,为模型提供动态特征;将模型与医疗实践、健康管理结合,为脱发患者提供个性化风险评估与干预建议,实现从 “预测” 到 “干预” 的闭环。
- 结果:“脱发” 占比 49.75%,“不脱发” 占比 50.25% ,样本分布相对均衡,为后续分析奠定基础。
-
2. 年龄与脱发关系:群体差异探究
用箱线图分析不同脱发标记人群的年龄分布:fig = plt.figure(figsize=(10, 6)) ax1 = plt.subplot(111) df.boxplot(column='年龄', by='脱发标记', ax=ax1) ax1.set_title('脱发人群年龄分布', fontsize=14) ax1.set_ylabel('年龄') plt.show()
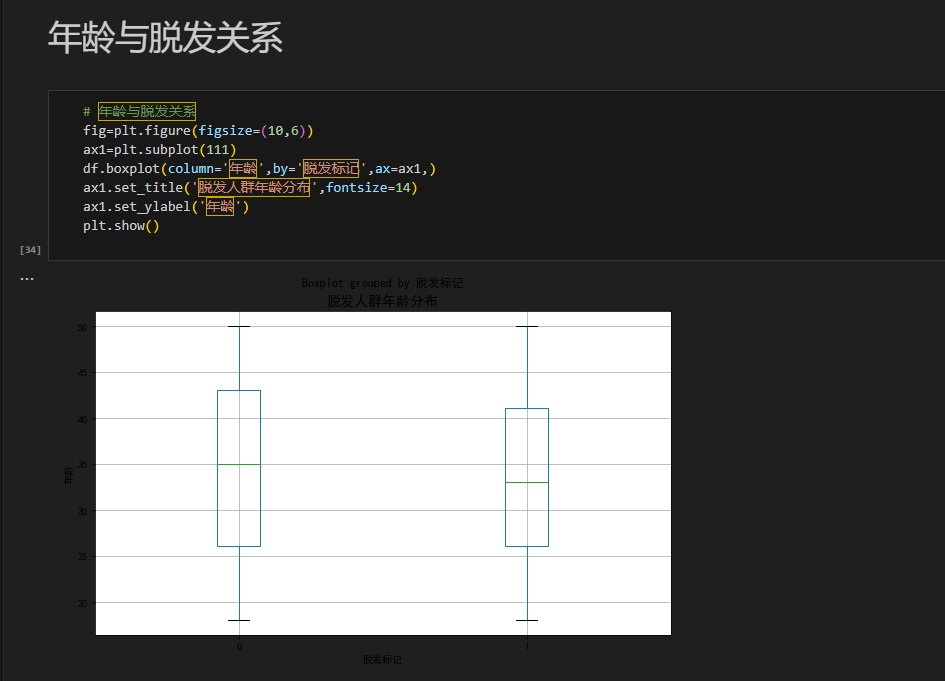
- 结果:箱线图展示了 “脱发” 与 “不脱发” 群体的年龄四分位数、异常值。可观察不同脱发状态下年龄的集中趋势与离散程度,初步判断年龄是否为脱发影响因素(如脱发群体是否存在年龄区间特征 )。
-
3. 常见医疗诊断分析:疾病关联挖掘
提取 “医疗状况” 字段,绘制横向柱状图展示十大高发关联疾病:plt.figure(figsize=(12, 8)) top_conditions = df['医疗状况'].value_counts().head(10) plt.barh(top_conditions.index, top_conditions) # 横向柱状图 plt.title('十大常见脱发相关医疗状况', fontsize=14) plt.xlabel('样本数量', fontsize=12) plt.ylabel('医疗状况', fontsize=12) plt.tight_layout() plt.show()
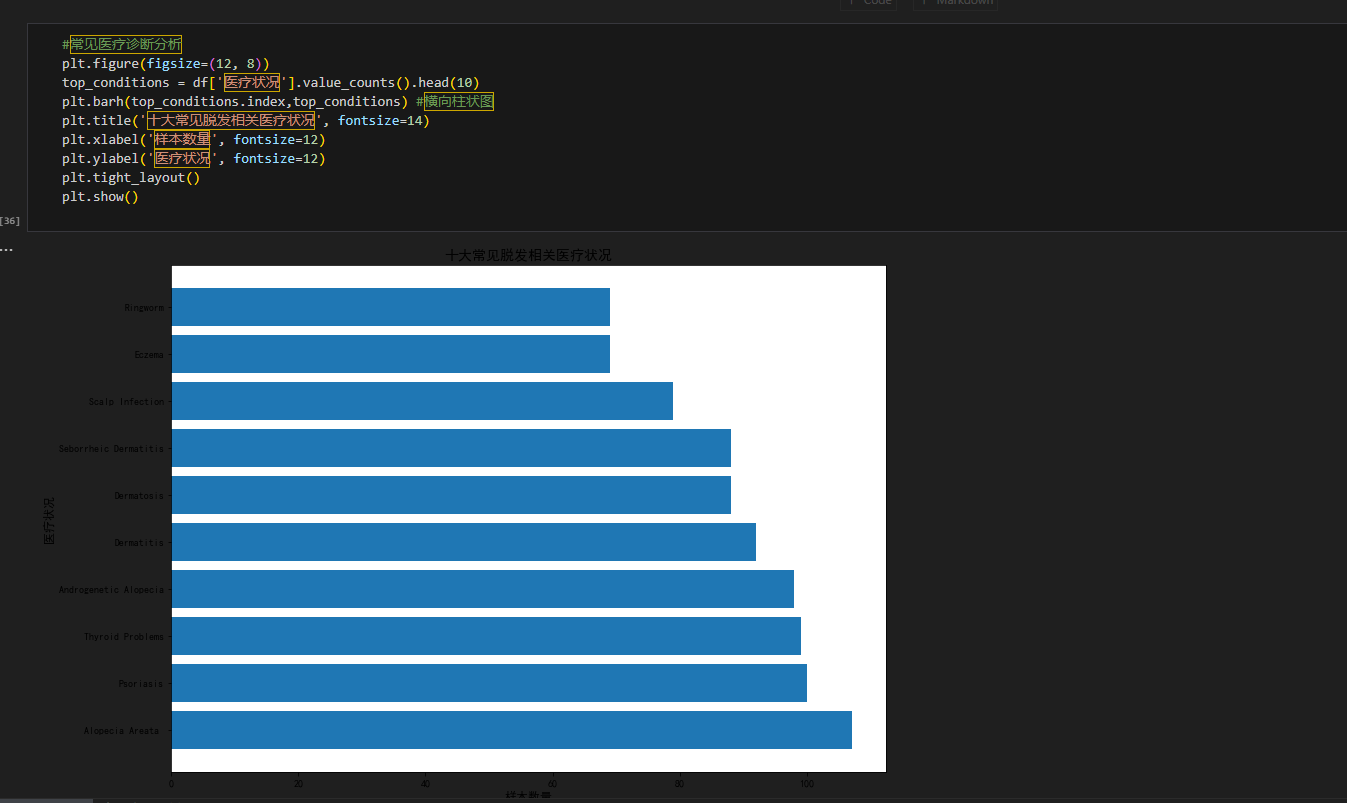
- 结果:直观呈现与脱发关联度高的疾病,如
Alopecia Areata(斑秃 )、Thyroid Problems(甲状腺问题 )等。可辅助医疗人员关注疾病对脱发的潜在影响,为临床研究提供方向。 -
4. 二值特征与脱发关系:生活习惯等因素剖析
选取 “遗传因素”“激素变化” 等二值特征,用分组柱状图分析其与脱发的关联:features = ['遗传因素', '激素变化', '不良护发习惯', '环境因素', '吸烟习惯', '体重减轻'] fig, axes = plt.subplots(3, 2, figsize=(15, 15)) axes = axes.flatten() df['脱发标记'] = df['脱发标记'].astype('category') categories = df['脱发标记'].cat.categories num_categories = len(categories) x = np.arange(num_categories) width = 0.35 for i, feature in enumerate(features): if i < len(axes): ax = axes[i] counts = df.groupby('脱发标记')[feature].value_counts().unstack(fill_value=0) rects1 = ax.bar(x - width/2, counts[0], width) rects2 = ax.bar(x + width/2, counts[1], width) ax.set_title(f'{feature}与脱发') ax.set_xticks(x) ax.set_xticklabels(categories) ax.legend(['无', '有']) plt.tight_layout() plt.show()
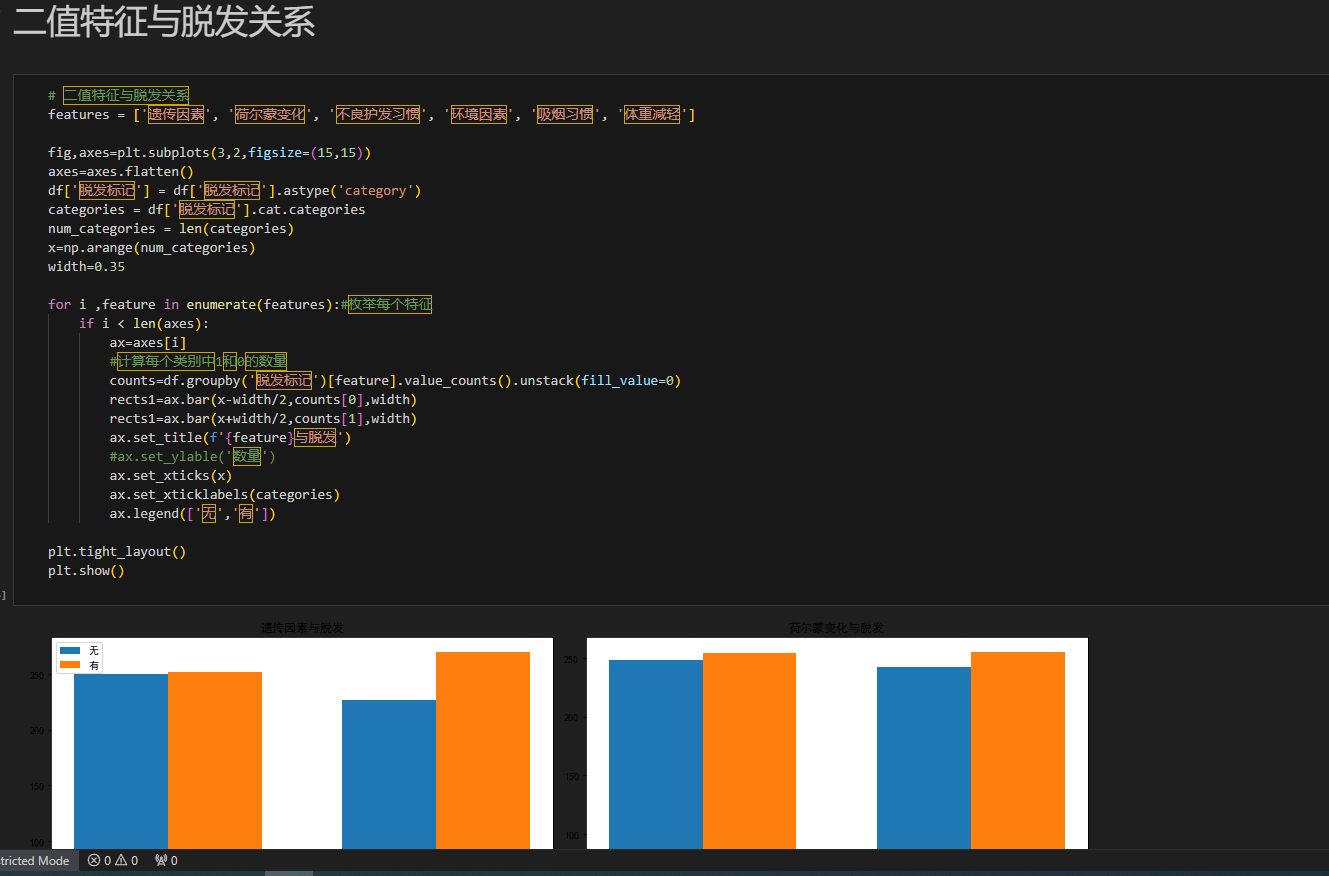
- 结果:每个子图对应一个二值特征与脱发的关联。例如 “遗传因素” 子图中,可对比 “有 / 无遗传因素” 在 “脱发 / 不脱发” 群体的分布,直观判断遗传、激素等因素对脱发的影响倾向。
-
三、XGBoost 模型预测及问题分析
(一)模型评估:混淆矩阵与 ROC 曲线
基于处理后的数据,构建 XGBoost 模型进行脱发预测,并通过混淆矩阵和 ROC 曲线评估模型性能。
混淆矩阵呈现了模型分类的具体结果,包括真阳性、真阴性、假阳性、假阴性的数量分布;ROC 曲线及对应的 AUC 值(本文中 AUC = 0.56 ),反映模型对脱发与不脱发样本的区分能力。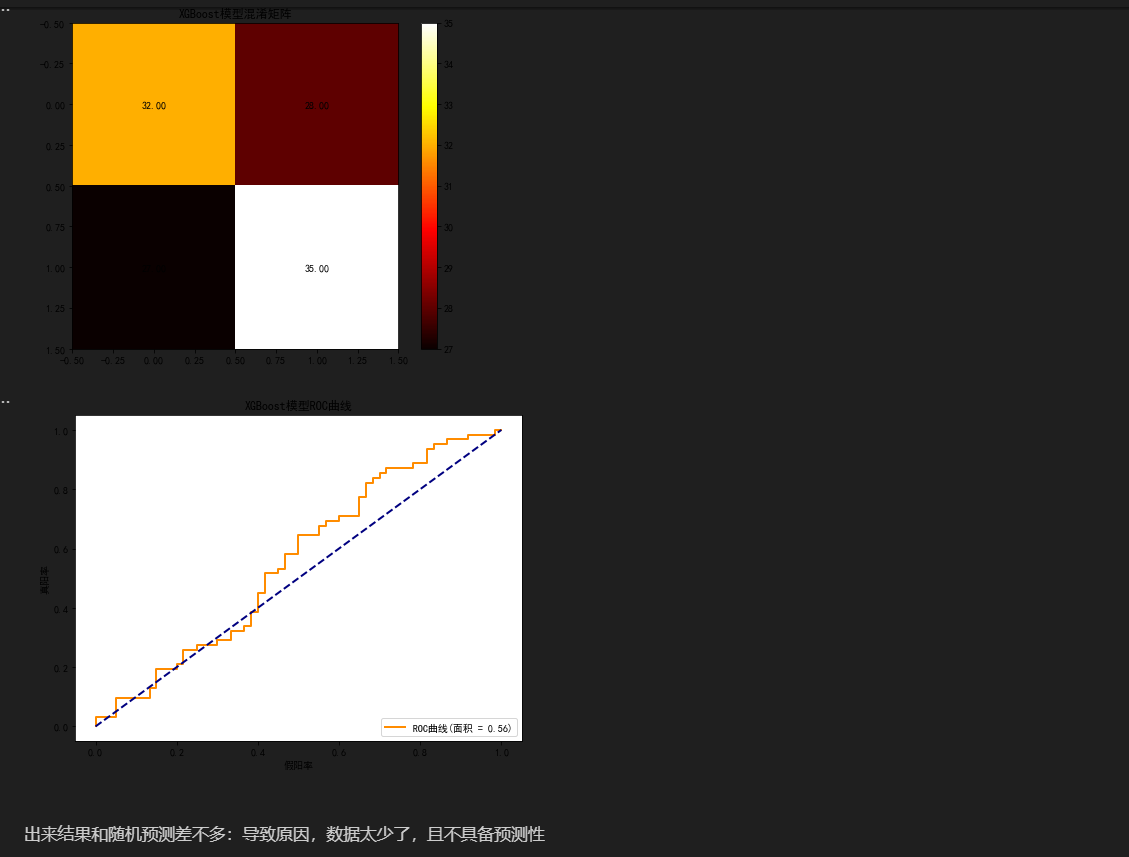
(二)模型问题:数据与性能瓶颈
从评估结果看,模型表现欠佳,预测结果与随机预测差异较小。主要原因如下:
- 数据量少:有限的样本无法让模型充分学习到稳定、有效的模式,难以精准捕捉脱发影响因素间的复杂关联。
- 特征预测性不足:部分输入特征与脱发结果的相关性低,无法为模型提供足够的判别信息,降低了模型区分能力。
-
四、优化方向与展望
(一)数据层面优化
- 扩充样本:通过多渠道采集数据,如与医疗机构合作补充病例、开展大规模问卷调查等,增加样本多样性与数量,让模型学习更全面的脱发影响模式。
- 特征工程:深入挖掘特征价值,对现有特征进行优化(如聚类、编码 ),或结合领域知识构建新特征(如 “压力 - 睡眠 - 脱发” 综合指数 ),增强特征与脱发结果的关联性。
- 参数调整:利用网格搜索、贝叶斯优化等方法,针对脱发数据优化 XGBoost 参数,平衡模型拟合与泛化能力,如调整学习率、树深度、正则化系数等。
- 模型融合:结合多种模型(如逻辑回归、随机森林 )进行集成学习,通过投票、 stacking 等方式融合预测结果,发挥不同模型优势,提升整体预测性能。
-
五、总结与拓展
-
通过数据可视化,我们初步挖掘了脱发的影响因素;借助 XGBoost 模型实践,虽暴露了数据与模型性能问题,但也明确了优化方向。期待未来通过数据扩充、特征优化、模型调优等手段,提升脱发预测性能,为脱发研究与健康管理提供更有效的技术支持,助力解决脱发困扰。通过可视化分析,我们清晰呈现了脱发标记分布、年龄关联、疾病影响及生活习惯等因素的作用。后续可拓展方向:
- 结合 机器学习(如逻辑回归、随机森林 ),量化因素对脱发的影响权重;
- 引入更多维度数据(如饮食、压力指数 ),深化脱发成因研究;
- 针对高发关联疾病,联动医疗数据开展深入临床分析。

















 3593
3593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









