






 本文介绍了一种名为Fastbot的多代理自动化GUI测试系统,通过在服务器端构建模型并运用协作机制加速复杂应用的测试。Fastbot在字节跳动的众多应用中展现高效,超越Monkey等工具,以较少时间实现高覆盖率。设计包括分布式工作流、状态与动作定义、AI核心算法如UCB和强化学习,以及实验结果对比和性能提升。
本文介绍了一种名为Fastbot的多代理自动化GUI测试系统,通过在服务器端构建模型并运用协作机制加速复杂应用的测试。Fastbot在字节跳动的众多应用中展现高效,超越Monkey等工具,以较少时间实现高覆盖率。设计包括分布式工作流、状态与动作定义、AI核心算法如UCB和强化学习,以及实验结果对比和性能提升。
fastbot-a-multi-agent-model-based-test-generation-system
fastbot github 仓库
fastbot 官方文章
摘要
用于自动化 GUI 测试的基于模型的测试 (MBT) 生成技术对于应用程序测试具有重要价值。 当应用于具有工业复杂性和可扩展性的应用程序时,现有的基于 GUI 模型的测试工具可能会陷入循环操作并耗尽资源。 在这项工作中,我们提出了一个名为 Fastbot 的多代理 GUI MBT 系统。 Fastbot 在服务端进行模型构建。 它应用多代理协作机制来加快模型构建过程。 提议的方法应用于字节跳动的 20 多个应用程序,每月活跃用户超过 15 亿。 与其他三种自动化测试工具(包括 Droidbot、Humanoid 和 Android Monkey)进行比较,以更少的测试时间实现更高的代码覆盖率。
1 introduction
如今,应用程序的功能变得越来越复杂。 健壮性最好的应用程序在应用程序商店中具有更好的竞争力。 因此,应用程序的自动化测试生成(ATG)成为一个重要的研究方向。
基于 GUI 的 ATG 技术已被广泛研究,例如基于模型的测试、基于搜索的测试、覆盖引导的模糊测试和符号执行。 与基于代码分析的 ATG 方法需要从源代码生成完整的控制流图不同,基于 GUI 的测试具有基于 UI 信息构建应用程序模型的能力。 最先进的工具包括 SAPIENZ [1],它应用随机模糊、系统的和基于搜索的探索; DYNODROID [2],它将应用程序视为事件序列并生成相关的智能输入; 其他流行的工具包括 DroidMate [3]、PUMA 和谷歌的 Android Monkey。
它们核心的逻辑聚焦在“如何生成”测试逻辑。以 MBT 为例,GUI 测试(客户端测试)过程中的某个页面,可以被定义为一个状态(State),利用该页面对应的 GUI 树,我们可以提取其中更有意义的操作,比如从 state1 通过 event3 可以到达 state3,从 state2 通过 event2 可以到达 state1。这样,测试生成的问题转化成对有向图的遍历问题。像 Monkey 之类的随机测试工具,由于缺少对于 Log 的更高层面的表述,常让开发者对其有担忧:
(1)由 Monkey 生成的测试序列不容易以文档的形式描述用例;
(2)比较难复现 Bug,缺少复现的详细步骤。
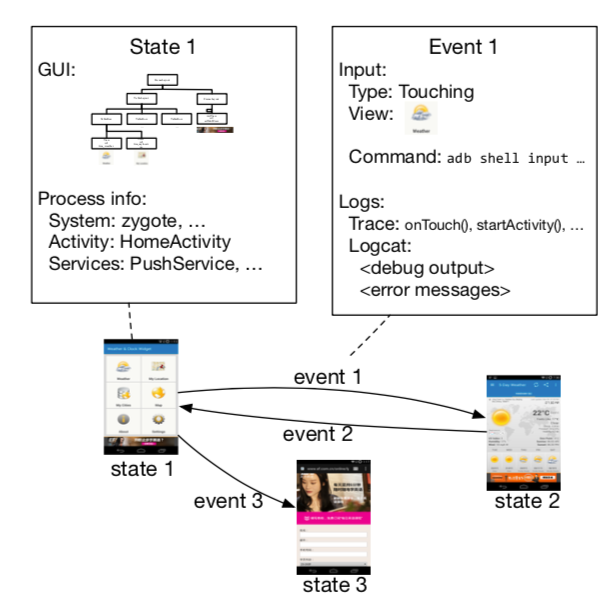
特别是,ATG 中的基于模型的测试 (MBT) 获得了更好的可重用性的巨大优势。 Droidbot [4] 是最前沿的基于 GUI 的 MBT 工具之一,它使用图探索算法执行基于模型的动态测试。北京大学的Humanoid[5]提出了以用户行为引导探索事件的新策略。大多数情况下,基于模型的 GUI 测试基于 2 个工件:描述所有可能的测试路径的有限状态机 (FSM),以及描述从一种状态到另一种状态的转换的操作配置文件。然而,当应用于具有工业复杂性和可扩展性的应用程序时,传统的基于模型的方法有两个缺点。首先,在类似页面中使用“GUI改变”作为状态判断的探索策略,很容易陷入循环操作。通过在探索过程中应用 DFS 和 BFS 算法,包括 DROIDBOT 在内的这些工具可能会在相同的场景中不断捕获,这严重限制了活动覆盖范围。而对于 Humanoid 来说,用户行为数据的可访问性成为最大的障碍。其次,快速扩张的模型会占用移动设备的内存。针对上述问题,我们提出了基于模型的自动测试生成系统Fastbot,实现了多客户端协作模型构建机制,并应用了基于UCB算法[6]和强化学习的算法,以实现更好的探索能力。
2 Design and Implementation
2.1 Fastbot Workflow
如上所述,移动设备的内存和计算能力已成为基于模型的 GUI 测试的主要限制。 Fastbot通过应用分布式计算系统,将模型相关的计算量大的部分移到服务器端,只在客户端保留UI信息收集和动作注入工作。 工作流程如图1所示。
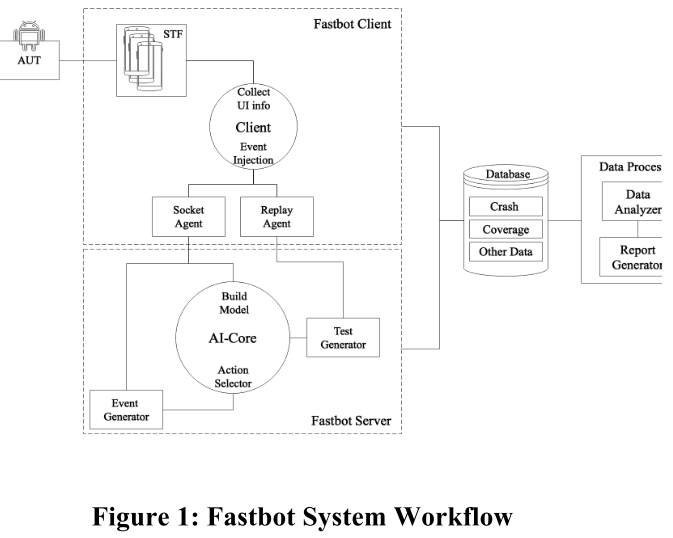
Fastbot 系统支持多个应用测试任务同时工作,互不影响。对于每一项任务,测试中的应用程序 (App Under Test ,AUT) 和用户定义的配置都将部署在多个移动设备上。在每台设备上,Fastbot 客户端将负责 UI 识别和事件注入工作。获取的当前状态的 UI 信息将通过socket代理发送到服务器。相应地,在服务器端有代理分析接收到的 UI 信息,将这些信息格式化为所谓的状态作为 AI-core 算法的输入。每个代理将根据其输入状态、分配的算法和模型信息选择下一个事件,同时协作构建存储在服务器内存中的静态模型。选定的事件将被传输回客户端执行,然后新的 UI-info 将被捕获并再次发送回服务器。在此过程中,将收集崩溃信息、代码覆盖率和有效路径等数据,用于数据分析、案例回放和测试生成。
2.2 Fastbot Model Description
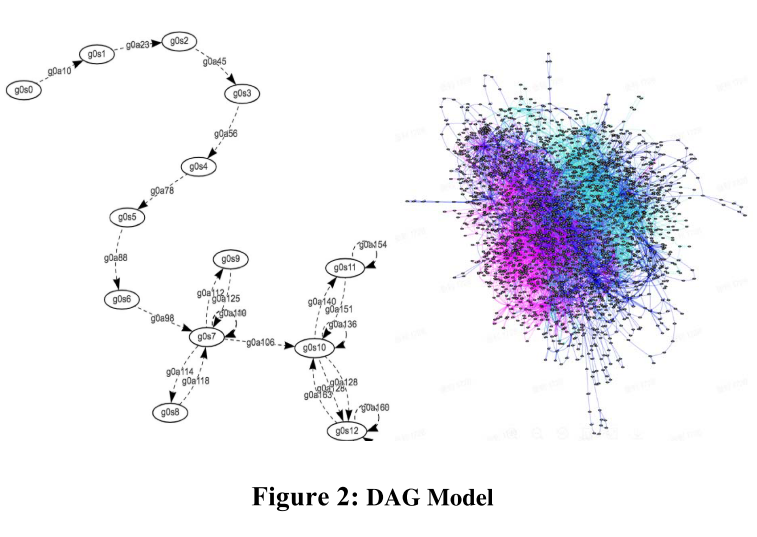
**通过将状态定义为当前页面上 UI 信息的抽象,将动作定义为要采取的事件,**从客户端的事件轨迹构建有向无环图(DAG),状态为图节点,动作为边。 Fastbot 中的模型基于此 DAG。 图 2 中的左侧部分显示了我们模型的一个简短示例。 箭头虚线表示指导和连接圆圈中显示的状态的动作。 通过多代理协作,我们的复合模型显示在图 2 的右侧部分,其中每种颜色代表唯一代理的遍历路径(我不太懂这个复合模型是啥意思)。
定义细粒度的状态是一项具有挑战性的工作。 如果没有对 GUI 信息进行任何抽象,状态数量将急剧增长,从而由于 Feed Pages 数量不限等原因导致服务器出现 OOM 问题。 通过我们的工作,观察到从扁平化的 GUI 树结构中获得的由活动名称(Activity name)、操作类型(Activity Type)和小部件(widgets)分布定义的状态抽象函数具有最佳性能。
2.3 Algorithms in AI core
传统的基于 DFS 和 BFS 的遍历算法的局限性在于基于动态应用程序而非原生应用程序构建的动态 DAG 模型,其中不能保证重复的路径导致恒定的目的地,因为 Feed pages 中不断变化的内容会造成干扰。(Traditional traversal algorithms based on DFS and BFS have their limitation on a dynamic DAG model built on dynamic app rather than native app, where duplicated path is not promised to lead to constant destination, for the reason of the disturb from forever- changing contents in Feed Pages. )
对于静态 Native App 上的测试,如计算器或日历 App,其状态有限,动作的结果相对统一,很少出现统一动作导向不同结果的情况,这种情况下传统的 DFS、BFS 算法仍有不错的遍历效率。
然而,在动态的有向有环图模型上,这些传统遍历方法就有很大的局限性了。动态 App 中,相同的动作很可能导向不同的页面,例如进入今日头条 App 后点击推荐 tab,每次拿到的页面都是与之前不同的推荐内容;由于类似的原因,简单的后退操作也无法保证能回到上一步的页面。更严重的是局部循环问题,由于环路的存在,我们可能重新回到某个全部动作都已访问的 State 节点,若不对已访问的动作进行再次访问,则会丢失路径中未访问过的动作,过早的结束遍历测试。如果使用类似贪心算法的方案,在某页面下贪心的选取某个价值较高的动作,不断尝试遍历该动作下的所有可达路径,那我们可能过多的陷入一条局部最优的路径当中,若该高优动作导向了某个不再会出现的 Feed 页面,或多个局部最优动作形成循环链路,则我们会陷入局部循环而无法退出。实际上当前页面判断价值较低的动作下可能隐藏着更多的可覆盖的状态点,需要我们探索开发。
在这里,我们在这种情况下提出了以下更好的拟合算法。
为了覆盖每个状态下更多的动作,我们将一个状态的优先级定义为该状态下动作的总价值,其中动作的价值由动作类型和动作访问标签决定。具有更高优先级的状态更值得再次访问。
对于总是以最大目标优先级分配动作的贪婪算法,能导致无法再次到达 Feed 页面状态的动作将使代理陷入无限循环(the actions leading to Feed Page state that cannot be reached again will trap the agent in infinite loops)。
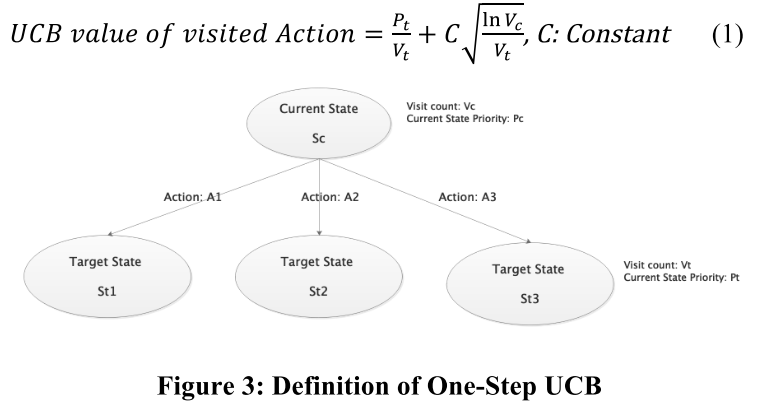
我们的第一个算法基于one-step UCB equation (upper confidence bound) [6] 来平衡探索和开发。在状态仍有未访问动作的情况下,动作优先级仅等于先前定义的动作值。否则,动作的优先级表示为根据公式 1 计算出的 UCB 值,并在图 3 中进行了相应说明。
上述策略的缺点之一是它只计算一步内的UCB值,而隐藏在后面几步的状态可能有更高的值被访问。 n 步 UCB 算法被提出作为克服这个缺点的优化。 代替在 UCB 方程中使用动作目标状态的优先级,我们使用所有目标优先级的累积乘以折扣因子 ? 在接下来的 n 步中作为等式 1 中的 Pt。等式 2 中给出了 Action 的 n 步 UCB 值。但是,该算法需要在以下 n 步中遍历并且需要指数时间复杂度。 逐渐增加的步数 n 最适合这种情况。
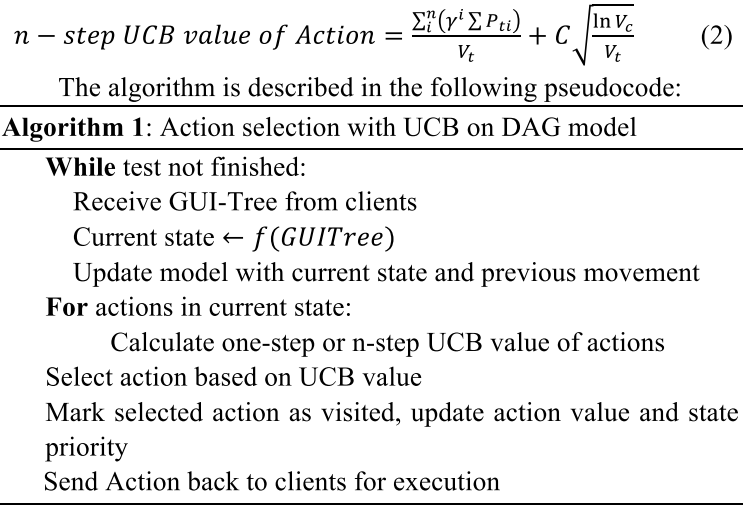
尽管如此,当前决策并未充分利用超过 n 步的信息,因为反向传播不适用于 DAG。另一种名为 MTree 的算法的设计灵感来自 AlphaGo [7] 中应用的蒙特卡罗搜索树算法,我们使用树结构和 DAG 作为我们的模型。每个树节点代表一个状态,将树节点中动作所引导的目标状态添加为子节点。导致先前访问状态的操作被添加为继子以防止循环。活动列表存储在每个树节点中,建议以下可达活动。当发现新活动时,将应用从当前节点到根的反向传播过程,更新子节点中的活动列表。 MTree 结构的示例如图 4 所示。每种颜色代表一个独特的活动。从状态 0 开始作为根节点,树结构在探索过程中向下扩展。虚线所示的动作5引回到被访问的根节点,形成一个循环;因此,我们将状态 5 添加为步骤子节点。Step children 不会参与反向传播或动作选择过程。它们的用途是在以下所有子节点都饱和时导航回来。相应地,在动作选择部分,探索未访问动作仍然是主要选择;对于访问过的动作,我们有 UCB 方程,用于导致等式 3 所示的子节点的动作,其中 Vc 和 Vp 表示子节点和父节点的访问次数。


Q-Learning 算法在 DAG 模型上捕获动作选择功能也带来了智能导航。 在该算法中,为每个状态-动作对计算 Q 值,前向动作根据状态差异函数获得正奖励,而导致访问状态的动作将根据访问次数获得负奖励。 因此,代理学会避免无限循环并发现新状态。 应用带有 UCB 的 N 步 Q 学习进行优化。

3 结果
Fastbot 已经集成到字节跳动测试框架中,作为主要的稳定性和兼容性测试工具服务于 20 多个应用程序。 每天安排超过 300 个构建任务,应用各种自定义配置来匹配每个产品线的需求。 Fastbot 每天暴露大约 5,000 起崩溃,其中新发现的崩溃超过 100 起。 崩溃信息会报告给我们的错误系统并分配给相关开发人员进行调查。 使用此工具,假定在应用程序发布之前找到并修复了罪魁祸首补丁。
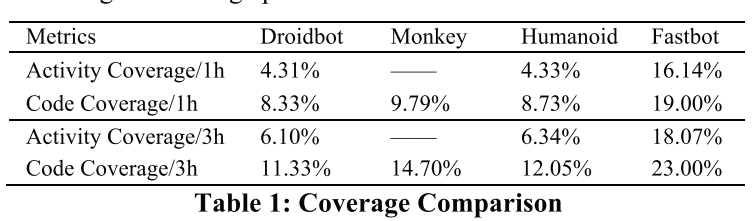
以下实验评估包括我们一款名为今日头条的应用程序的代码覆盖率和活动覆盖率数据。 表 1 显示了单个设备上的一小时和三小时测试数据。 与流行的遍历测试工具包括 Monkey、Droidbot 和 Humanoid 相比,Fastbot 实现了更高的覆盖性能。
此外,Fastbot 在客户端/服务器模式下的多设备协作极大地增强了探索能力。 图 5 显示了 Fastbot 在 1、3、20 和 50 台设备上工作的活动覆盖性能。 显然,多设备协作带来了更高的覆盖率和更快的探索速度。 我们的服务器端分布式系统支持多达100台设备在单个模型上协作50小时,从而产生47.88%的活动覆盖率,不会引发OOM问题或减慢动作决策速度。 如表 2 所示,Fastbot 的三客户端协作相比单设备测试实现了 84% 的活动覆盖增强,而对于 Droidbot 和 Humanoid,从一台设备到三台设备的增强仅为 20.41% 和 24.97%,而对于 Monkey 则为 45.79% .

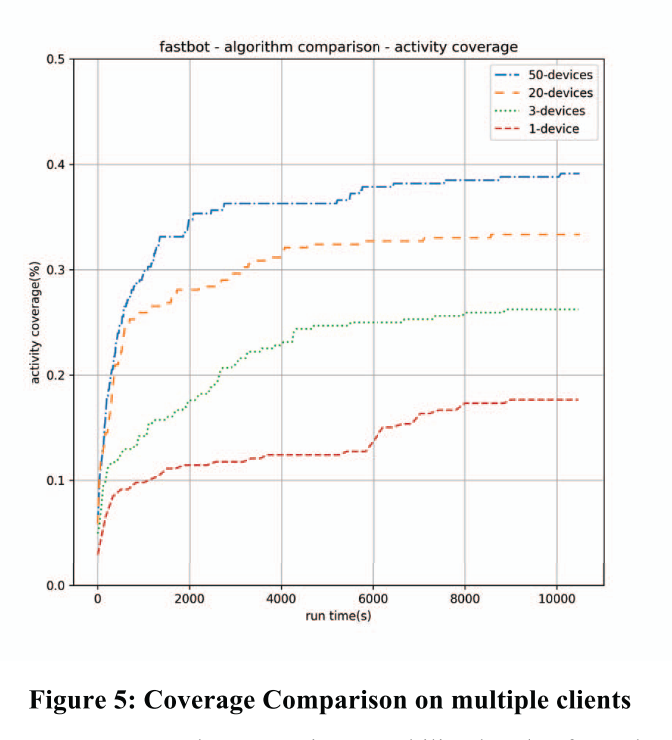
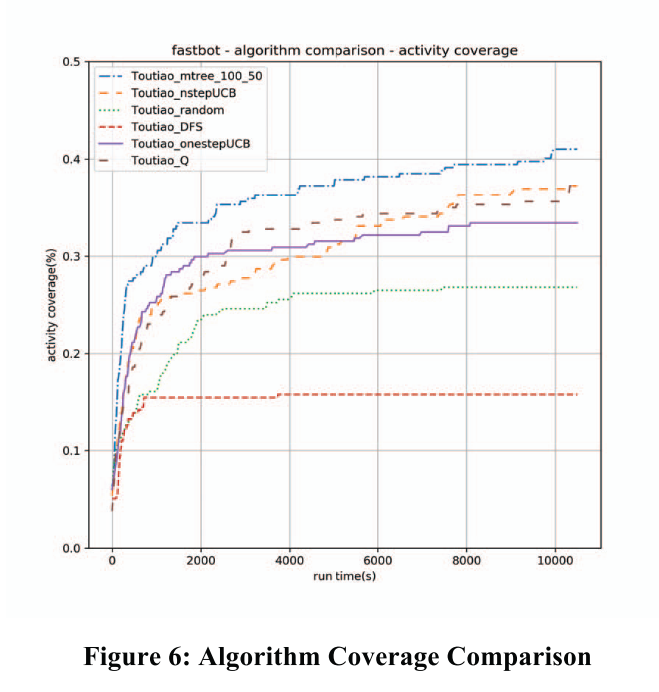
图 6 比较了上述四种算法以及传统 DFS 和随机算法的遍历能力。每个测试都部署了 20 台设备。如图所示,DFS 代理很快卡在内部循环中,活动覆盖率停止增加。 Random Agent 在动态 DAG 情况下有更好的性能,覆盖率达到 26% 左右。一步UCB算法在早期具有最好的探索速度,而发现隐藏在复杂路径后面的活动的潜力成为其弱点。相反,n步UCB代理的覆盖率增长较慢,因为它在到达目标状态之前需要覆盖(n-1)个重复动作,但在后期它表现出更好的更深层次的探索能力。 DQN 代理的性能不稳定。它比 n-step agent 具有更好的上限,同时需要更少的计算资源。然而,性能受到早期探索阶段不可控的动作选择的严重影响。在我们的测试中,MTree Agent 表现出最佳的整体性能。
个人理解与评价
字节的这个工具看上去效果很好。
解决问题:现有的基于 GUI 模型的测试工具可能会陷入循环操作并耗尽资源。 他们的Fastbot 是一个多代理 GUI MBT 系统。 Fastbot 在服务端进行模型构建。 它应用多代理协作机制来加快模型构建过程。
我对 构建描述所有可能的测试路径的有限状态机 (FSM),以及描述从一种状态到另一种状态的转换的操作配置文件这个两个基础过程没有代码级别的理解。另外对于如何进行时间注入我也不太清楚。需要看代码
我不太懂那个通过多代理协作产生的复合模型

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









