



可复现性:
要固定随机数种子,可以保证多次运行出来的结果完全相同!!!!
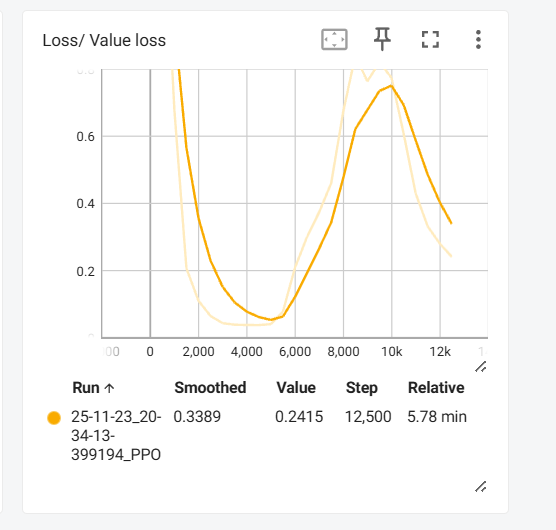
这种value loss先降低,就是policy输出的action逐渐符合所能见识过能获得更好奖励的action了。
但是突然探索到了新的重大奖励的action,于是乎value loss就又先上升,然后后下降
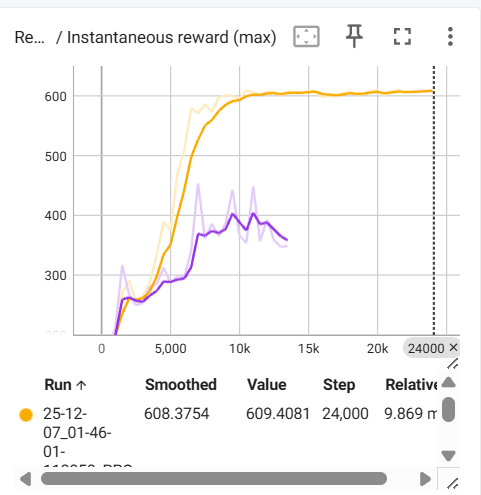
改动前:黄色
改动后:紫色
用最大值相同的奖励替换了一个原来的奖励,导致无法学不到最大的即时奖励了,那就学不到最优策略啊,肯定不行啊。所以不要删掉原来的奖励。在保留的基础上,我又加了新的奖励
权重比例
感觉权重比例是个需要微操大师来操作,在即时奖励里,稍微改一点,加/减一点,效果就完全不一样


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









