



一、理解
1. 概念:一种操作便利的对象容器,存储多个对象,多数情况下可替代数组。
2. 位置:所有集合的接口和相关实现类都是位于 java.util 包中
3. 学习集合从以下几个内容进行:
(1) 集合的特点
(2) 集合的常用方法
(3) 集合的实现类
(4) 集合的遍历
4. 集合的分类:
(1) Collection集合体系
-> List集合
-> Set集合
(2) Map集合体系
-> Map集合
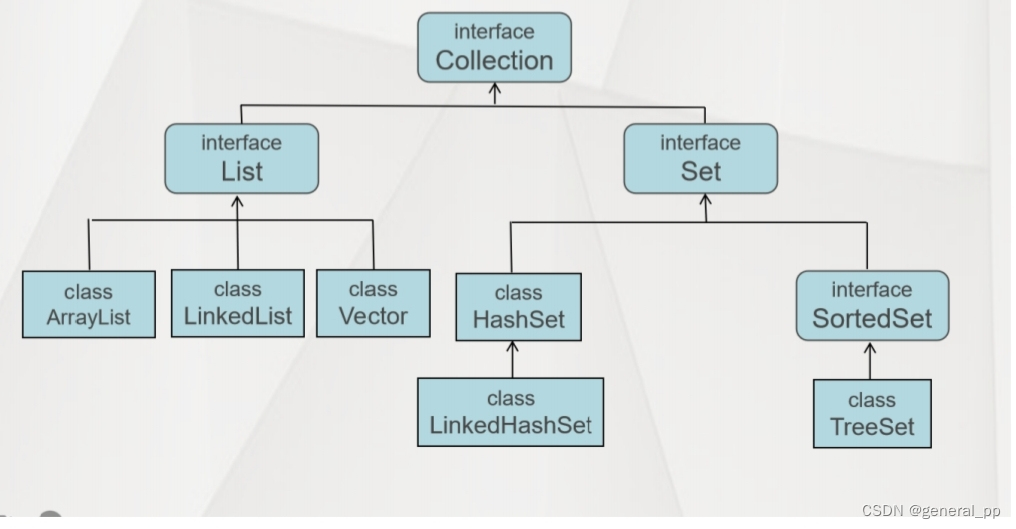
二、Collection集合体系
1.父接口:Collection
(1) Collection接口的特点:存储多个对象,即存储数据类型Object
(2)方法:
boolean add(Object obj): 添加一个对象 【重点】
int size() :返回此集合中的元素个数 【重点】boolean contains(Object o) : 检查此集合中是否包含o对象boolean remove(Object o) :在此集合中移除o对象void clear() :清空此集合中的所有对象。boolean isEmpty() :判断此集合是否为空(3) 实现类:具体看子接口
(4) 遍历:具体看子接口
2. 子接口:List
(1) List接口的特点:存储Object类型的对象,有序、有下标,元素可以重复(下标从0开始,依次为1、2、...)
(2) 方法:List是Collection的子接口,所以Collection接口中定义的方法List都可以使用,同时自身也定义了一些方法
Object get(int index) //返回集合中指定位置的元素 【重点】Object remove(int index) //移除index位置上的元素Object set(int index, Object element) //替换index位置上的元素(3) 实现类:ArrayList
(4) 遍历:
a. 下标遍历:// 控制集合的下标:从0开始,到 size-1for(int i=0;i<list.size();i++){// 根据下标获取对应数据:getSystem.out.println(list.get(i));}b. forEach遍历:for(泛型类型 变量名 : 集合名){// 利用变量名操作集合元素3. 子接口:Set}(5) 泛型集合:强制约束集合中的元素类型统一
ArrayList<数据类型> 集合名 = new ArrayList<数据类型>();ArrayList<数据类型> 集合名 = new ArrayList<>(); -->数据类型可以省,<>保留注意:<>前后的数据类型必须统一;基本数据类型的泛型需要使用对应的包装类型(6) 不同实现类区别:
ArrayList:底层用数组实现,查询快,增删慢JDK1.2提供,线程不安全,并发效率高。Vector:底层用数组实现,查询快,增删慢JDK1.0提供,线程安全,并发效率低。LinkedList:底层用链表实现,查询慢,增删快JDK1.2提供,线程不安全,并发效率快
3.子接口:Set
(1) 特点:存储多个Object类型的对象,无序、无下标、元素不可以重复(内容不允许重复)
(2) 方法:继承于 父接口 Collection
(3) 实现类:HashSet
注意:为了保证存储在HashSet集合中对象内容不重复,需要覆盖 equals和 hashCode方法LinkedHashSet:存储多个Object类型的对象,按照添加顺序进行存储、无下标、元素不可以重复(内容不允许重复)(4) 遍历方式:forEach(底层原理迭代器遍历)
(5) SortedSet:是 Set的子接口,无序、无下标、对元素内容进行排序。【了解】
(6) LinkedHashSet:按照添加顺序进行集合元素存储,同时元素内容不允许重复。
注意:LinkedHashSet是 HashSet的子类,所以如果自定类型的对象存储在LinkedHashSet中, 为了保证元素内容不重复,则需要对象对应的类覆盖 hashCode方法 和 equals方法(要求和父类HashSet一致)。
三、Map集合体系
1. Map集合的特点:【基础重点】
(1) 存储任意的 键值对 (key-value),Map中一个集合元素是一个键值对
(2) 键:无序、无下标、不允许重复(唯一)
(3) 值:无序、无下标、允许重复
2. Map 集合中的方法
(1) V put(K key,V value) :
往Map集合中添加一个键值对,如果键在Map中没有存在,则直接添加,返回值为null;如果键在Map中已经存在,则新的Value覆盖原有的value数据,被覆盖的value数据作为返回值进行返回。【开发重点】
(2) V remove(K key):
根据键,删除对应的键值对,被删除的值(value)作为返回值返回。
(3) V get(K key):
根据键,返回对应的值(value)。【重点】
(4) boolean containsKey(K key):
判断Map集合中是否包含指定的键,包含-true;不包含-false.
(5) boolean containsValue(V value):
判断Map集合中是否包含指定的值,包含-true;不包含-false.
(6) int size() : 获取Map中键值对的个数。
3. 实现类:HashMap
注意:如果自定类型的对象存储在HashMap的键上,为保证键的不允许重复,则自定义类型的对象对应的类需要覆盖hashCode方法和equals方法;但是开始通常用 String/Integer类型的数据作为键。
(1) HashMap: JDK1.2 版本,线程不安全,运行效率较高,允许null 作为 key/value。【开发重点】
(2) Hashtable : JDK1.0版本,线程安全,运行效率慢,不允许null作为key/value。
(3) Properties:是 Hashtable的子类,要求 键和值都是String类型。开发时,通常用于读取配置文件。
(4) SortedMap : 是 Map子接口,可以对键完成自动排序。实现类:TreeMap
(5) LinkedHashMap:是 HashMap的子类,按照添加的顺序完成键值对的存储。
4. 遍历:
(1) 第一种遍历方式:键遍历,通过 keySet()方法获取Map 所有的键 【开发应用重点】
Set< K > ks = map.keySet(); // 获取所有的键
// 利用 foreach遍历 set集合
for(K key : ks){
// 通过 map 的 get方法,获取键对应的值
V value = map.get(key);
// 利用 key 和 value 操作每一个键和值即可
}
(2) 第二种遍历方式:值遍历 ,通过 values() 获取 Map中所有的值
Collection< V > vs = map.values();
//利用 foreach 遍历 Collection集合
for(V value:vs){
// 通过 value 操作对应的值
}
(3) 第三种遍历方式:键值对遍历,通过 entrySet方法获取Map中所有键值对
Set< Map.Entry< K,V>> kvs = map.entrySet();
// 通过foreach遍历 set集合 获取每一个键值对(Entry)
for(Map.Entry< K,V> kv : kvs ){
// 利用 Entry中提供两个方法 getKey 和 getValue 获取键和值的信息
K key = kv.getKey(); // 从键值对中获取键的信息
V value = kv.getValue() ; // 从键值对中获取值的信息
// 通过 key 和 value 操作键和值
}

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









