




 文章介绍了使用Python和OpenCV进行图像处理,包括绘制图形和文字、图像融合、摄像头下的二维码识别与人脸检测,如人脸检测在本地图片和摄像头中的应用,以及如何训练个人脸分类器。
文章介绍了使用Python和OpenCV进行图像处理,包括绘制图形和文字、图像融合、摄像头下的二维码识别与人脸检测,如人脸检测在本地图片和摄像头中的应用,以及如何训练个人脸分类器。
1. 常用技巧
1.1. 绘制图形和文字
绘制直线,图形,文字等
使用matplotlib展示图像

# -*- coding: utf-8 -*-
import cv2
import sys
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('./resource/5.png',cv2.IMREAD_COLOR)
'''
line(img,pt1,pt2,color,thickness,lineType,shift)
rectangle()
circle(img,center,radius,color[,thickness[,lineType[,shift]]])
ellipse(img,center...)
polylines(img,pts,isClosed,color,[])
fillPoly
putText(text,org,fontFace,fontScale)
'''
cv2.line(img,(10,10),(100,100),(0,0,255),5,4)
cv2.rectangle(img,(100,100),(150,150),(0,255,0),5,4)
cv2.circle(img,(300,300),50,(0,0,255))
cv2.ellipse(img,(399,399),(100,50),0,0,360,[0,0,255],5)
pts=np.array([[(250,100),(150,300),(50,280)]],np.int32)
cv2.polylines(img,pts,True,(0,0,255,5))
cv2.fillPoly(img,pts,(0,0,255))
cv2.putText(img,'hello',(300,300),cv2.FONT_HERSHEY_COMPLEX,5,[0,0,255])
plt.figure(figsize=(10,5))
plt.imshow(img[:,:,[2,1,0]])
plt.show()
1.2. 图像的融合
图像腐蚀操作
使用matplotlib展示图像
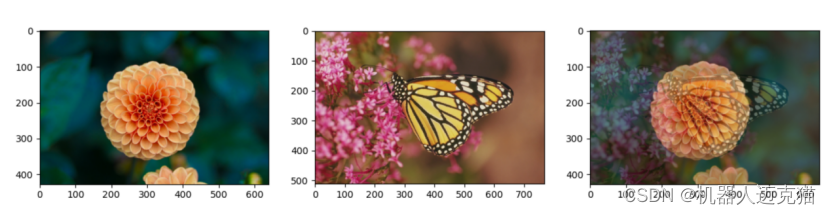
import cv2
import matplotlib.pyplot as plt
butterfly=cv2.imread('./resource/flower.jpg')
flower=cv2.imread('./resource/image_E.bmp')
new_flower=cv2.resize(flower,(butterfly.shape[:-1][::-1]))
result=cv2.addWeighted(new_flower,0.4,butterfly,0.6,0)
# 显示图形
plt.figure(figsize=(15,5))
plt.subplot(131)
plt.imshow(butterfly[:,:,[2,1,0]])
plt.subplot(132)
plt.imshow(flower[:,:,[2,1,0]])
plt.subplot(133)
plt.imshow(result[:,:,[2,1,0]])
plt.show()
2. 二维码检测
2.1. 摄像头识别二维码
# 用摄像头识别二维码
import cv2
import numpy as np
# 初始化摄像头
cap = cv2.VideoCapture(0)
# 创建 QR 检测器实例
detector = cv2.QRCodeDetector()
while True:
_, img = cap.read()
# 检测解码
data, bbox, _ = detector.detectAndDecode(img)
# 标识二维码外框,识别数据
if bbox is not None:
bbox = bbox.astype(np.uint64)
for i in range(len(bbox[0])):
cv2.line(img, tuple(bbox[0][i]), tuple(bbox[0][(i+1) % len(bbox[0])]), color=(255, 0, 0), thickness=2) # 颜色为BGR
if data:
print('数据是:', data)
cv2.imshow('摄像头拍摄', img)
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
2.2. 识别本地图片二维码

# import qrcode
# img = qrcode.make('data')
# img.save("./resource/some_file.png")
# 读取二维码
import cv2
import numpy as np
# 读取图片
img = cv2.imread("./resource/some_file.png")
# 创建 QR 检测器实例
detector = cv2.QRCodeDetector()
# 使用检测器检测数据并解码
# data表示二维码的数据,
# bbox表示二维码四边形顶点坐标数组,
# straight_qrcode表示校正后生成的二进制格式的二维码
data, bbox, straight_qrcode = detector.detectAndDecode(img)
#
print(bbox[0])
#转换数据类型 float-》int
bbox = bbox.astype(np.uint64)
print(bbox[0])
# print(len(bbox[0]))
# print(straight_qrcode)
if bbox is not None:
print(f'二维码的数据是:{data}')
# 显示二维码图片的边线
n_lines = len(bbox[0])
for i in range(n_lines):
point_1 = tuple(bbox[0][i])
point_2 = tuple(bbox[0][(i+1) % n_lines])
cv2.line(img, point_1, point_2, color=(255, 0, 0), thickness=2) # 颜色为BGR
# cv2.imwrite("./resource/some_file2.png",img)
# 显示和退出处理
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
3. 人脸检测
3.1. 本地图片人脸检测
import cv2
face_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_frontalface_default.xml")
img = cv2.imread(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\images\woodcutters.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.08, 5)
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x+w, y+h), (255, 255, 0), 2)
cv2.imshow('Woodcutters Detected!', img)
# cv2.imwrite('./woodcutters_detected.png', img)
cv2.waitKey(0)
3.2. 摄像头人脸和人眼检测
import cv2
face_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_eye.xml")
camera = cv2.VideoCapture(0)
while (cv2.waitKey(1) == -1):
success, frame = camera.read()
if success:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray, 1.3, 5, minSize=(120, 120))
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
roi_gray = gray[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(
roi_gray, 1.1, 5, minSize=(40, 40))
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(frame, (x+ex, y+ey),
(x+ex+ew, y+ey+eh), (0, 255, 0), 2)
cv2.imshow('Face Detection', frame)
3.3. 摄像头捕捉人脸并保存
import cv2
import os
output_folder = r'D:\GProject\105_OpenCV\resource\lo4cvwptem\data\at/cooky'
if not os.path.exists(output_folder):
os.makedirs(output_folder)
face_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_eye.xml")
camera = cv2.VideoCapture(0)
count = 0
while (cv2.waitKey(1) == -1):
success, frame = camera.read()
if success:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray, 1.3, 5, minSize=(120, 120))
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
face_img = cv2.resize(gray[y:y+h, x:x+w], (200, 200))
face_filename = '%s/%d.pgm' % (output_folder, count)
cv2.imwrite(face_filename, face_img)
count += 1
cv2.imshow('Capturing Faces...', frame)
3.4. 摄像头换脸 (待定...)
3.5. 自己训练个人脸分类器
import os
import cv2
import numpy
def read_images(path, image_size):
names = []
training_images, training_labels = [], []
label = 0
for dirname, subdirnames, filenames in os.walk(path):
for subdirname in subdirnames:
names.append(subdirname)
subject_path = os.path.join(dirname, subdirname)
for filename in os.listdir(subject_path):
img = cv2.imread(os.path.join(subject_path, filename),
cv2.IMREAD_GRAYSCALE)
if img is None:
# The file cannot be loaded as an image.
# Skip it.
continue
img = cv2.resize(img, image_size)
training_images.append(img)
training_labels.append(label)
label += 1
training_images = numpy.asarray(training_images, numpy.uint8)
training_labels = numpy.asarray(training_labels, numpy.int32)
return names, training_images, training_labels
path_to_training_images = r'D:\GProject\105_OpenCV\resource\lo4cvwptem\data\at'
training_image_size = (200, 200)
names, training_images, training_labels = read_images(
path_to_training_images, training_image_size)
# model = cv2.face.EigenFaceRecognizer_create()
# model = cv2.face.FisherFaceRecognizer_create()
model = cv2.face.LBPHFaceRecognizer_create()
model.train(training_images, training_labels)
face_cascade = cv2.CascadeClassifier(r"D:\GProject\105_OpenCV\resource\lo4cvwptem\chapter05\cascades\haarcascade_frontalface_default.xml")
camera = cv2.VideoCapture(0)
while (cv2.waitKey(1) == -1):
success, frame = camera.read()
if success:
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
roi_gray = gray[x:x+w, y:y+h]
if roi_gray.size == 0:
# The ROI is empty. Maybe the face is at the image edge.
# Skip it.
continue
roi_gray = cv2.resize(roi_gray, training_image_size)
label, confidence = model.predict(roi_gray)
text = '%s, confidence=%.2f' % (names[label], confidence)
cv2.putText(frame, text, (x, y - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
cv2.imshow('Face Recognition', frame)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











